Industry: FinTech (SMB Lending) | Region: New York, USA | Client Type: Series C Enterprise
About the Client
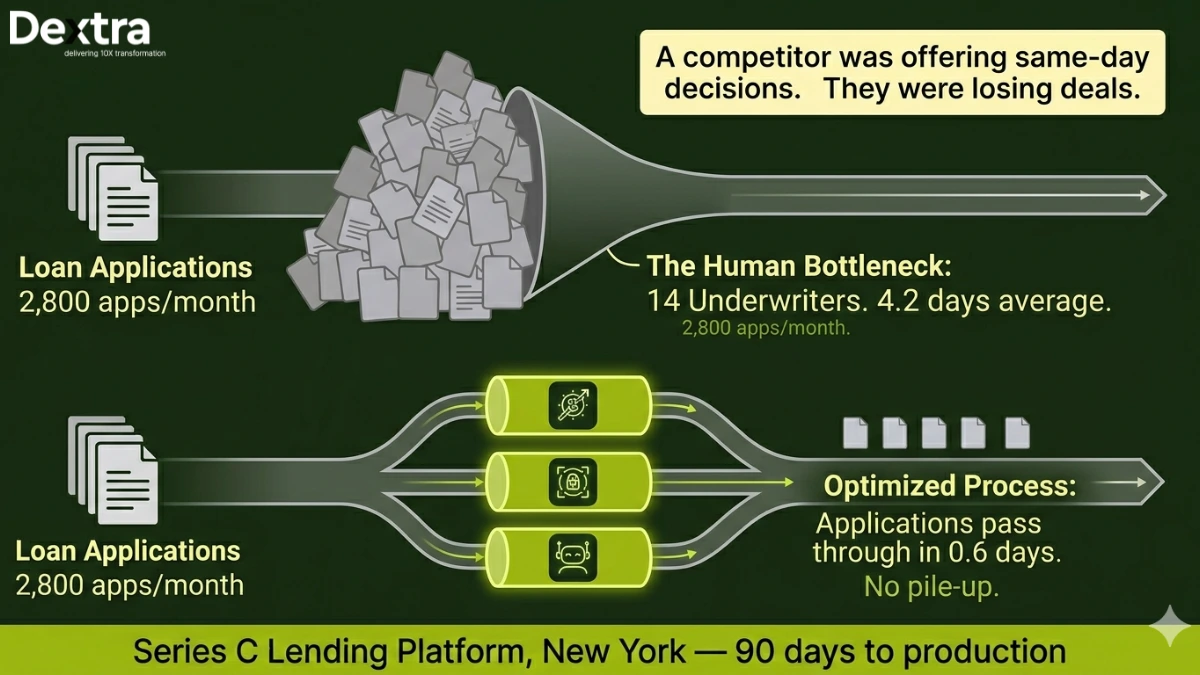
The client is a Series C lending platform headquartered in New York, focused on SMB financing. They originate short-term working capital loans and revenue-based financing for small businesses across the United States. At the time of engagement, they were processing over 2,800 loan applications per month with a team of 14 underwriters.
The company had just closed a $38M round and was under pressure to scale origination volume without linearly scaling headcount. Their board wanted proof that AI could move the needle on unit economics before the next funding milestone.
The Problem
Underwriting at this company was a grind. Every application came with a stack of documents, bank statements (often 6 months across multiple accounts), tax returns (W-2s, K-1s, corporate filings), articles of incorporation and personal guarantees. An underwriter would spend 2–3 hours just extracting numbers from these files, then another 1–2 hours cross-referencing those numbers against the company’s internal credit policy, a 200-page document that had been built up over five years of lending experience.

The average turnaround from application to decision was 4.2 days. That doesn’t sound terrible until you realize that borrowers seeking working capital are usually in a hurry. A competitor offering same-day decisions was winning deals. The client estimated they were losing 15–20% of qualified applicants to churn during the waiting period.
They’d tried a basic rules engine. It covered maybe 30% of cases and broke constantly when edge cases came in, partnerships with complex K-1 structures, businesses with seasonal revenue, applicants with multiple entities. Anything outside the happy path went straight back to a human.
What Dextralabs Built?
As one of most reliable AI agent development agency in USA, we didn’t build one monolithic agent. That’s the mistake most teams make, they try to create a single system that handles everything from document parsing to decision-making. It becomes impossible to debug, impossible to improve incrementally and impossible to trust.
Instead, we decomposed the problem into three specialized agents, each with a clear responsibility and well-defined input/output contracts:
Agent 1: Document Ingestion Agent
This agent handles the messy, thankless work of turning 23 different document types into structured data. Bank statements come in every format imaginable, Chase looks nothing like a local credit union’s PDF export. Tax documents have their own quirks. We built a layout-aware parsing pipeline using Tesseract OCR enhanced with custom post-processing that understands the spatial relationships on financial documents. The extraction accuracy across all document types sits at 96.8%.
Agent 2: Risk Assessment Agent
This is the brain. It takes the structured data from Agent 1 and reasons over it against the client’s credit policy. We built a RAG pipeline that indexes the full 200-page policy document, so the agent’s decisions are grounded in specific clauses and thresholds, not generic financial knowledge from its training data. The agent produces structured reasoning chains: “Revenue in months 3–6 averaged $42,000/month, exceeding the minimum threshold of $35,000 per Policy Section 4.2.1. However, month 2 showed a 40% decline, triggering the volatility review per Section 7.1.” Every decision is traceable to a policy clause.
Agent 3: Underwriter Copilot
The third agent compiles the outputs from Agents 1 and 2 into a structured decision package for human review. For straightforward cases (clean documents, clear policy alignment, no flags), it generates an “approve” recommendation with a full audit trail. For complex cases, it highlights exactly which elements need human judgment and why. The underwriter sees a pre-filled review screen, not a blank form.
Architecture and Technical Decisions
The three Ai agents communicate through an asynchronous event bus built on Redis Streams. This was a deliberate choice over synchronous orchestration. If Agent 1 takes longer on a particularly complex document, Agents 2 and 3 don’t sit idle, they process other applications. If any agent fails on a specific file, the system routes that application to the human queue with a clear error context rather than crashing the entire pipeline.

We built a dead-letter queue for cases where the system couldn’t reach a confident decision. These aren’t failures, they’re honest acknowledgments that some applications genuinely require human expertise. The client’s underwriting team reviews these cases and their feedback continuously improves the agents’ handling of edge cases.
Tech Stack
GPT-4o + Claude 3.5 Sonnet · LangGraph · Pinecone · AWS Lambda · Tesseract OCR · Redis Streams · PostgreSQL · Python FastAPIResults
| 78% Applications auto-decisioned same-day | 4.2 → 0.6 days Average turnaround time | $1.2M/yr Operational cost savings | 99.4% Decision accuracy vs. human baseline |
Within 90 days of production deployment, 78% of incoming applications were being auto-decisioned on the same day they were submitted. The average turnaround dropped from 4.2 days to 0.6 days. Applicant churn during the review period fell by over half.
The underwriting team went from 14 people to 6, not through layoffs, but through natural attrition and redeployment. The remaining team members handle genuinely complex cases and spend their time on portfolio strategy rather than data entry. Annual operational savings hit $1.2 million.
The metric the client cares about most: decision accuracy. We benchmarked the agent’s decisions against the historical decisions of the human team on a holdout set of 500 applications. The agent matched human decisions 99.4% of the time. In the 0.6% of disagreements, a senior underwriter reviewed both decisions and sided with the agent in roughly half the cases.
“We went from a 4-day bottleneck to same-day decisions on 78% of files. The agents don’t just speed things up, they catch inconsistencies our team was missing at volume.”
— VP of Credit Operations, Series C Lending Platform, New York
Engagement Timeline
14 weeks from discovery to production deployment. Weeks 1–2: discovery and credit policy analysis. Weeks 3–6: Agent 1 (document parsing) development and testing. Weeks 5–9: Agents 2 and 3 development in parallel. Weeks 10–12: integration testing with live application data. Weeks 13–14: production rollout with shadow mode (agents ran alongside humans for comparison).

Facing a similar challenge?
Talk to our team about building AI agents for your underwriting, credit, or financial operations workflows.
👉 Book a 30-min AI Consultation




