What Every Team Should Know, And How Dextra Labs Helps You Get It Right From Day One
If you’re an engineer, technical leader, or founder trying to bring LLMs into real products, you already know something most people don’t:
It’s easy to build an LLM demo. But, it’s hard to build an LLM system people actually trust and use. The leap from “fun prototype” to “production-ready, scalable, reliable LLM application” is huge. Suddenly you’re dealing with messy workflows, inconsistent outputs, performance bottlenecks, unpredictable reasoning, user skepticism, and the eternal question:
“Why did the model give me this answer?” At Dextra Labs, we help teams navigate this reality every day. We specialize in everything from LLM implementation to evaluations, deployments, prompt systems, fine-tuning, and enterprise integration. And over dozens of projects across engineering-heavy industries, we’ve learned a simple truth: Success with LLMs is less about the model, and more about the engineering around the model.
According to a 2025 survey by S&P Global Market Intelligence, 42% of companies abandoned most of their AI initiatives in 2025 (up from 17% in 2024). On average, organizations scrapped 46% of their AI proof-of-concept (PoC) projects before production deployment.
This article breaks down 10 practical lessons that can save your team months of trial and error. If you’re serious about building LLM systems that work, not just look good in a demo, read on.
Lesson 1: Not Every Problem Needs an LLM: Start With the Basics
Let’s just get this out of the way: LLMs are powerful, but they’re not hammers for every nail.

Sometimes a simple script, rule, or classical ML model will beat an LLM in accuracy, speed, and cost, especially for deterministic tasks.
Before you even think about prompts or vector databases, ask:
- Does this task require reasoning?
- Is the input unstructured or messy?
- Do we need natural language understanding?
- Would a simple rule solve most cases?
When we work with clients at Dextralabs, we always start with a Solution Fit Assessment. It prevents teams from building LLM systems where they don’t belong, and saves a ton of budget.
Lesson 2: Think “Augment,” Not “Automate”
This is one of the most important mindset shifts.
If you walk into an engineering team’s office and say: “We’re replacing part of your decision-making with a black-box AI!” you’ve already lost.
LLM solutions succeed when engineers see them as assistants, not replacements.
Think:
- a junior teammate that speeds up analysis
- a summarizer for long documents
- an explainer for complex data
- a helper that reduces repetitive tasks
At Dextra Labs, we design systems where:
- humans stay in control
- LLMs contribute but don’t dominate
- outputs are suggestions, not final decisions
This builds trust, the foundation of all successful AI adoption.
Lesson 3: Build With Domain Experts, Not in Isolation
You can’t engineer a real-world LLM application from a conference room.
The best systems come from sitting next to domain experts and watching how they work:
- how they triage issues
- how they organize information
- where they make decisions
- what frustrates them
- what they ignore
- what matters most
Only then can you answer the key question:
“What does better look like for them?”
Sometimes “better” means faster.
Sometimes “better” means more consistent.
Sometimes “better” means fewer manual tasks.
At Dextra Labs, we call this co-design. It cuts development time dramatically and leads to solutions users actually adopt.
Lesson 4: Build Copilots, Not Autopilots
One-click, fully automated LLM systems sound futuristic, but most real-world processes are too nuanced for that.
Engineers don’t want to hit a magic button and pray the system guessed right. They want to see the steps.
Great LLM applications break the problem into stages:
- Understand the input
- Extract important information
- Generate intermediate reasoning
- Propose options
- Ask for confirmation
- Produce final output
This makes the system:
- explainable
- predictable
- easier to test
- easier to trust
Dextra’s workflow designs follow this structure almost universally. It’s a game-changer for adoption.
Lesson 5: Don’t Pick Technology First: Design the Workflow First
This is a trap we see all the time: “Should we use LangGraph? AutoGen? CrewAI? Haystack? Agents? Tools?”
Wrong question.
Frameworks matter, but only after you understand the workflow.

Start with:
- What steps does the user actually follow?
- What data moves between those steps?
- When does the system need memory?
- Which parts must be deterministic?
- Where do humans intervene?
Once that’s clear, the technology choice becomes obvious. This workflow-first approach at Dextra Labs prevents teams from over-engineering or choosing tools they don’t actually need.
Lesson 6: Walk Before You Run: Start Deterministic, Then Add Agency
Everyone wants to build agents. They’re exciting, autonomous, dynamic.
But they’re also unpredictable, especially in engineering domains that require accuracy.
The best-performing LLM systems start simple:
- deterministic steps
- fixed workflow
- clear inputs and outputs
- minimal free-form reasoning
Only when the system is stable should you introduce:
- tool use
- agentic loops
- autonomous decisions
- multi-step planning
Dextralabs often helps clients downscale their initial agentic prototypes into more stable workflows, then gradually layer in agentic AI capabilities where they make sense.
Lesson 7: Structure Everything: Inputs, Outputs, Knowledge, Rules
LLMs love structure. However, they struggle with chaos.
If you feed them:
- raw logs
- messy PDFs
- giant paragraphs
- unorganized data
…you’re almost guaranteed inconsistent results.
Instead, convert everything into structured formats:
- JSON schemas
- tagged text blocks
- extracted entities
- consistent templates
- well-defined fields
Do the same for outputs.
Example:
{
“findings”: […],
“evidence”: […],
“recommendations”: […],
“confidence”: “medium”
}
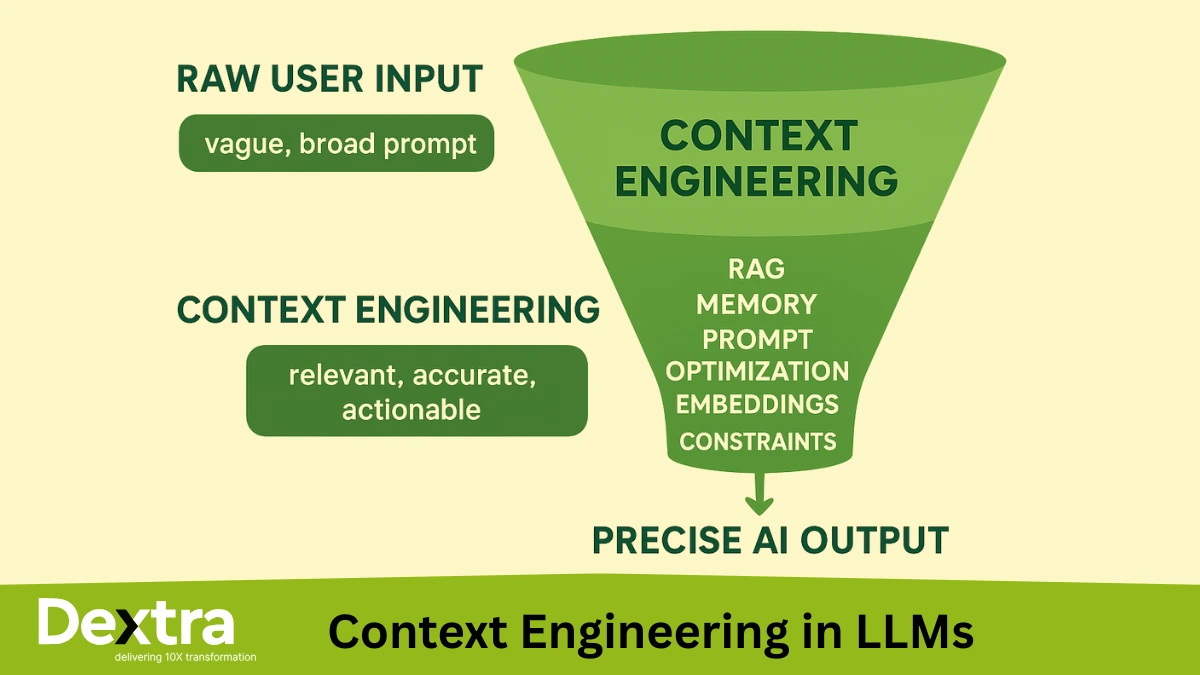
This structure massively boosts accuracy and makes your system testable. Dextra Labs specializes in structured prompting, schema design, and knowledge organization, and it’s often the turning point for reliability.
Lesson 8: Don’t Force LLMs to Do Everything: Use Classical Analytics
LLMs are great at language, reasoning, and synthesis. They’re not great at raw math, anomaly scoring, or numerical prediction.
So use a hybrid approach:
- Classical AI – detect patterns
- Classical AI – score anomalies
- Classical AI – analyze signals
- LLMs – explain results
- LLMs – summarize
- LLMs – contextualize
- LLMs – generate recommendations
This balance delivers:
- higher accuracy
- lower latency
- lower cost
- more trust
Dextra Labs builds many of these hybrid systems, and they outperform pure LLM setups every time.
Lesson 9: Put LLM Intelligence Where Engineers Actually Work
Here’s a hard truth: No one wants another standalone chatbot. Engineers won’t adopt tools that force them to leave their environment.
LLMs are most effective when seamlessly integrated into:
- dashboards
- reports
- monitoring tools
- field apps
- document systems
- issue trackers
Think small, powerful features:
- “Explain this”
- “Summarize the last 24 hours”
- “Find similar issues”
- “Recommend next steps”
- “Generate a draft report”
- “Highlight key risks”
At Dextra Labs, we embed LLMs directly into our platform FieldXpress and into clients’ existing systems, resulting in far better adoption.
Lesson 10: Evaluate With Real Cases: And Show Your Work
Once the system is live, you’re not done. You’re actually at the most important phase: evaluation.

And not evaluation with synthetic examples. Evaluation with real messy cases from real users.
A good LLM system should show:
- what evidence it used
- its reasoning steps
- its assumptions
- its confidence
- where ambiguity exists
This transparency is essential.
At Dextra Labs, our LLM Evaluation service includes:
- Real-case benchmarking
- Error-pattern analysis
- Prompt refinement
- Scorecards for accuracy
- Human-in-the-loop reviews
- Continuous updates
This is how you move from “it works sometimes” to “it works reliably.”
How Dextra Labs Helps You Build LLM Applications That Actually Work?
Dextralabs is built for one purpose: to help companies turn LLM technology into real-world impact.
We support the entire lifecycle:
LLM Strategy & Consulting
Identifying where LLMs create value.
LLM Implementation
Building your workflow, prompts, and logic.
LLM Deployment
Secure, scalable, optimized infrastructure.
LLM Evaluation
Making sure the system is reliable, testable, and trustworthy.
LLM Prompt Engineering
Designing robust, structured, schema-driven prompts.
Custom Model Development
Fine-tuning, domain-specific training, and private models.
Agent & Workflow Design
From simple copilots to semi-autonomous assistants.
Integration Into Existing Tools
Embedding LLM capabilities right into your existing platforms and workflows.
We’re the engineering partner that stays with you from idea → prototype → production → scale.
Final Thoughts
LLMs have enormous potential, but only when built with engineering discipline and a deep understanding of real-world workflows.
The 10 lessons above will help you:
- avoid common pitfalls
- design smarter systems
- create better user experiences
- increase trust and adoption
- deliver more reliable outcomes
And if you’re looking for a partner who has already walked this path with dozens of teams, Dextralabs is here to help. Real engineering, real workflows, and real AI. That’s how LLM applications succeed.
FAQs:
Q. What is an LLM in production?
An LLM in production means a large language model is no longer just a demo or experiment—it’s actively being used by real users inside a live product or business workflow. At this stage, the model must be:
– Reliable and consistent
– Secure and compliant
– Fast enough for real usage
– Integrated with real databases, APIs, and systems
– Fully monitored and evaluated
In simple terms, production LLMs are built for trust, scale, and real business impact, not just impressive demos.
Q. What is a production-ready application?
A production-ready application is software that is stable, secure, and ready for real-world users at scale. It’s not just about “working on your laptop.”
A production-ready app typically includes:
– Strong performance and low downtime
– Security, authentication, and access control
– Error handling and logging
– Monitoring and performance tracking
– Scalable infrastructure
– Regular testing and updates
For LLM-based products, this also includes prompt stability, output validation, hallucination control, and continuous evaluation.
Q. What are some of the applications of LLMs?
LLMs are already powering real-world systems across industries. Common applications include:
– Customer support automation
– Document analysis and summarization
– Code generation and review
– Sales and marketing content creation
– Legal and compliance document review
– Healthcare note summarization
– Knowledge assistants for enterprises
– HR screening and onboarding tools
– Financial report analysis
– Product recommendation and insights
The real power of LLMs comes when they are deeply integrated into workflows, not just used as chatbots.
Q. What is the use of LLM in manufacturing?
In manufacturing, LLMs are mainly used to improve efficiency, safety, quality, and decision-making. Some powerful use cases include:
– Analyzing machine logs and maintenance data
– Predictive maintenance explanations
– Root cause analysis for production issues
– Quality inspection reporting
– SOP and documentation automation
– Engineer copilots for troubleshooting
– Supply chain insights and summaries
Instead of replacing engineers, LLMs act as intelligent copilots that help teams diagnose issues faster and make better decisions.
Q. What is LLM observability in production?
LLM observability is the practice of tracking, monitoring, and understanding how an LLM behaves in real-time after deployment.
It helps answer critical questions like:
– Why did the model give this output?
– What data influenced this response?
– Is performance degrading over time?
– Are hallucinations increasing?
– Which prompts are failing?
– Are users trusting the system?
LLM observability typically includes:
– Prompt and response logging
– Accuracy scoring
– Latency tracking
– Cost monitoring
– Drift detection
– Human feedback loops
Without observability, LLM systems become black boxes—and black boxes don’t survive in production.
Q. What is LLM in product management?
For product managers, LLMs act as decision accelerators and productivity multipliers. Common uses include:
– User feedback analysis at scale
– Feature prioritization insights
– Product requirement drafting
– Sprint summary generation
– Market research analysis
– Competitive intelligence reports
– Roadmap documentation
In product management, LLMs don’t replace human judgment—they compress weeks of thinking into hours, allowing faster and smarter decisions.