
A significant turning point in the development of large language models (LLMs) is set to happen in 2026. LLMs are now mission-critical infrastructure with multimodal capabilities, domain-specific reasoning, and enterprise-grade deployment features. From independent financial advisors in the United Arab Emirates to regulatory-heavy healthcare copilots in the United States to e-commerce agents in Singapore, organizations are integrating these models into workflows that handle sensitive data, regulatory responsibilities, and customer interactions at scale.
The scale of adoption is remarkable:
- Gartner forecasts global end-user spending on generative AI (GenAI) will surge to $14.2 billion in 2025, up a staggering 148% year-over-year, a dramatic leap that reflects growing enterprise confidence in AI investments.
- According to Credence Research, the broader LLM market is projected to expand from approximately $4.7 billion in 2023 to nearly $70 billion by 2032, sustaining a robust 35% CAGR over the next decade.
- Yet despite hype, not all AI deployments succeed. Gartner reports that at least 30% of GenAI projects will be abandoned after proof of concept by the end of 2025, often due to poor data quality, soaring costs, or unclear business value.
With dozens of new LLMs launching each quarter, open-source and proprietary alike, choosing the right model has never been more complex. That’s precisely why LLM leaderboards have become indispensable decision-making tools, offering clarity on model accuracy, efficiency, bias, and risk.
The issue is that there are now dozens of proprietary and open-source LLMs being created every quarter, making it difficult to choose the best model. The LLM leaderboards are useful in this situation. Businesses can distinguish between hype and reality thanks to these standards, which offer defined rankings for accuracy, latency, efficiency, and even bias.
At Dextralabs, we’ve noticed that multinationals, SMEs, and startups in the United States, UAE, and Singapore are increasingly using LLM rankings as the basis for model selection. Leaderboards provide detailed insights into trade-offs that directly affect TCO (Total Cost of Ownership), time-to-deployment, and regulatory compliance. Drawing on our knowledge, we’ve created this guide to assist firms in deciphering the most reliable LLM benchmark leaderboards for 2025.
Also Read: Top 15 AI Consulting Companies in 2026
Why LLM Leaderboards Matter in 2026?
LLM benchmarks have evolved beyond raw accuracy; they now measure efficiency, safety, reasoning, and cost-effectiveness. These rankings help:
- Compare model accuracy and speed across domains.
- Understand trade-offs between size, latency, and resource use.
- Identify bias, hallucination vulnerabilities, and robustness.
While public LLM leaderboards are useful, they may not accurately reflect enterprise realities such as deployment efficiency in the cloud versus on-premises.
- Customizable flexibility for proprietary datasets.
- Fine-tuning flexibility for proprietary datasets.
- Compliance with GDPR, HIPAA, or UAE data residency laws.
That is why, at Dextralabs, we combine leaderboard data with enterprise-specific evaluation frameworks to ensure models meet performance, compliance, and operational resilience criteria before deployment.
Top LLM Leaderboards to Follow in 2026:
Hugging Face Open LLM Leaderboard
What it is:
The de facto public leaderboard for open-source models. It ranks models using academic benchmarks like MMLU, ARC, TruthfulQA, and GSM8K, updated almost daily.
Features:
- Covers reasoning, language understanding, math, and factual accuracy.
- Filters by model size, architecture, and quantization precision.
- Transparent submissions from model developers.
Use Cases:
- Great for comparing open-source models if you want transparency and community validation.
- Useful starting point for procurement teams deciding whether to build on OSS vs. pay for proprietary APIs.
Pros (CTO View): Clear, transparent, fast-moving; excellent for spotting rising OSS models.
Cons: Purely benchmark-driven; doesn’t account for latency, deployment cost, or compliance fit.
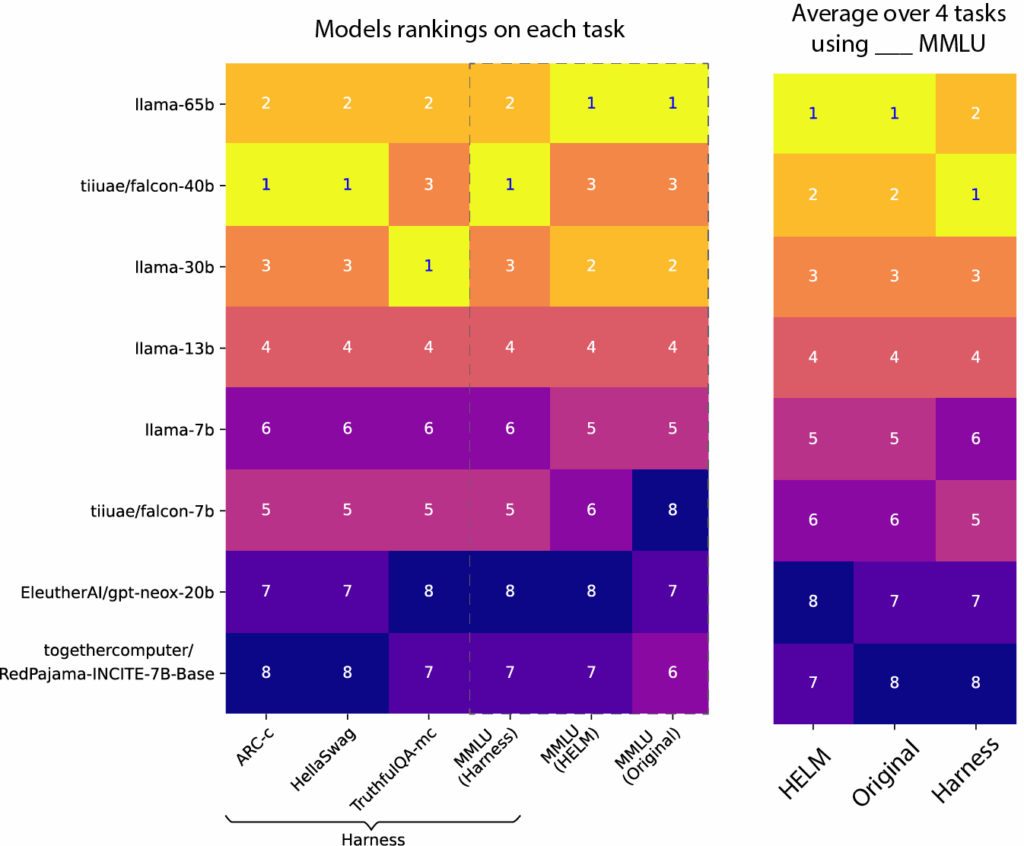
LMSYS Chatbot Arena (LMSYS Leaderboard)
A community-driven, crowd-sourced leaderboard using pairwise human comparisons, ideal for evaluating conversational quality and real-world interaction handling.
What it is:
A crowdsourced leaderboard where models are tested head-to-head by humans in blind conversations. Think of it as the “Consumer Reports” of conversational AI.
Features:
- Pairwise comparisons between models (human judges vote).
- Focuses on real-world chatbot quality over academic scores.
- Rankings shift quickly with community votes.
Use Cases:
- Ideal if your LLM use case is customer-facing chat, support, or copilots.
- Helps gauge how “natural” a model feels in actual conversations.
Pros: Reflects real conversational quality better than benchmarks.
Cons: Vulnerable to bias (10% bad votes can skew ranks); lacks enterprise metrics like TCO or compliance.
Also Read: LLM Jailbreaking: Steps by steps guide 2026
Stanford HELM (Holistic Evaluation of Language Models)
HELM evaluates models across 42 realistic scenarios and seven metrics: accuracy, fairness, bias, toxicity, efficiency, robustness, and calibration. It’s fully transparent and extensible, offering both overall and domain-specific leaderboards, including medical and finance.
What it is:
The most comprehensive academic benchmark for LLMs, evaluating across 42 scenarios and 7 dimensions: accuracy, fairness, bias, toxicity, efficiency, robustness, and calibration.
Features:
- Extensible to new domains (finance, healthcare).
- Fully transparent methodology.
- Offers domain-specific leaderboards (not just general performance).
Use Cases:
- Critical if you’re deploying in regulated industries like banking or healthcare.
- Great for vendor due diligence—proves whether a model meets bias and fairness standards.
Pros: Balanced, holistic view across accuracy, safety, and efficiency.
Cons: Academic setup—doesn’t always map neatly to enterprise deployment conditions (e.g., cloud costs).
MT-Bench / Chatbot Arena:
Crowd-evaluated chatbot performance via pairwise comparisons.
What it is:
An evaluation designed specifically for multi-turn conversation quality, often used alongside LMSYS.
Features:
- Tests reasoning across chained, multi-step prompts.
- Focuses on dialogue coherence and sustained interaction.
Use Cases:
- Ideal if your LLM powers customer support bots, copilots, or tutoring systems where multi-turn reasoning matters.
Pros: Better at exposing weaknesses in long-form dialogue than single-question benchmarks.
Cons: Narrower focus—doesn’t cover embeddings, latency, or bias.
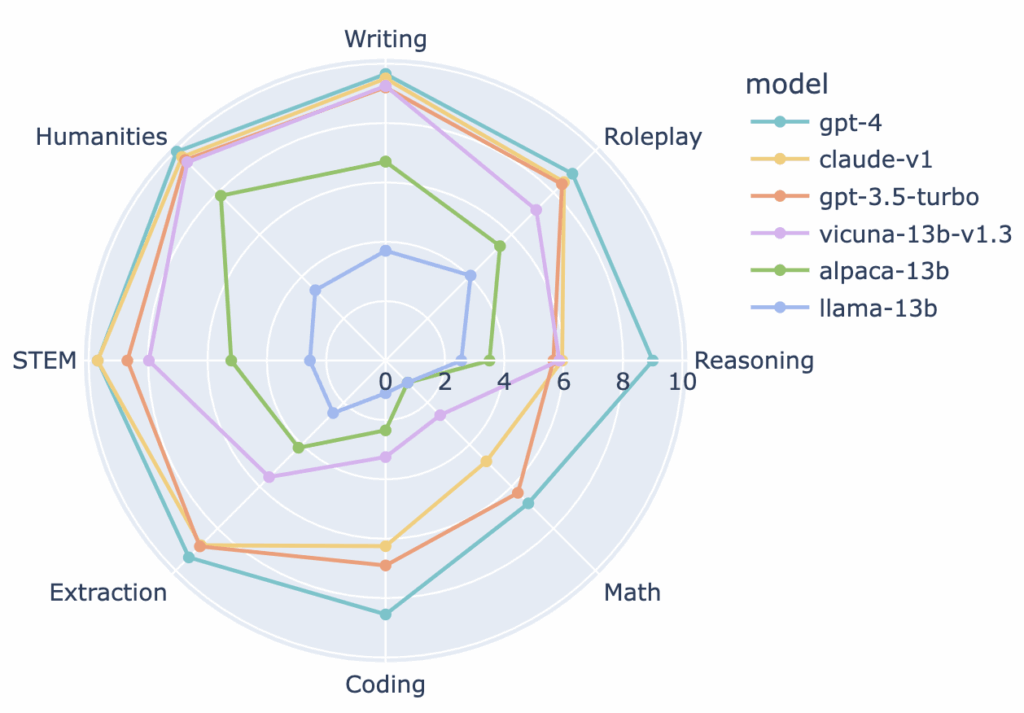
OpenCompass CompassRank:
Multi-domain leaderboard with both open and proprietary models.
What it is:
A multi-domain leaderboard covering both open and proprietary models, developed in China but globally relevant.
Features:
- Evaluates across dozens of domains (STEM, humanities, law, etc.).
- Includes both closed-source and open-source LLMs.
Use Cases:
- Good for enterprises wanting a broad comparative view across model types.
- Especially useful in Asia-Pacific markets with local LLM players.
Pros: Wide coverage, includes proprietary models.
Cons: Methodology less transparent than HELM; regulatory environment may influence submissions.
CanAiCode Leaderboard:
Evaluates code-generation ability of small LLMs, useful for dev teams.
What it is:
A niche leaderboard focused on code generation and reasoning abilities of LLMs.
Features:
- Benchmarks coding tasks across languages (Python, Java, C++).
- Evaluates debugging, completion, and reasoning.
Use Cases:
- Critical for dev teams exploring AI copilots, code assistants, or automation.
- Helps choose the right model for software engineering workflows.
Pros: Sharp focus on developer productivity use cases.
Cons: Doesn’t measure general language or compliance—too narrow for full enterprise adoption.
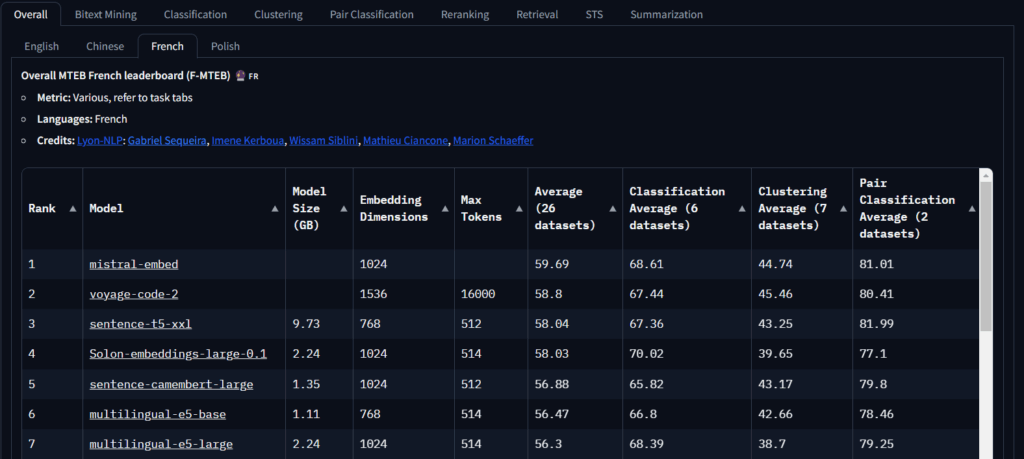
MTEB Leaderboard:
Benchmarks text embedding models across 56 datasets and languages.
What it is:
The standard benchmark for text embedding models, which power search, retrieval, and semantic similarity tasks.
Features:
- Covers 56 datasets and multiple languages.
- Evaluates embeddings for classification, clustering, RAG, and multilingual tasks.
Use Cases:
- Must-track if you’re building RAG systems, semantic search, or recommendation engines.
Pros: Gold standard for embeddings, highly detailed.
Cons: Embeddings ≠ generative performance; needs to be paired with other leaderboards for a full picture.
Humanity’s Last Exam:
A newly introduced, highly challenging benchmark measuring reasoning across broad topics, ideal for testing frontier models.
What it is:
A new high-stakes benchmark measuring advanced reasoning and general knowledge. Designed to push frontier models to their limits.
Features:
- Covers reasoning across law, philosophy, science, and more.
- Designed to surface hallucinations and fragile reasoning.
Use Cases:
- Useful for evaluating frontier models for enterprise R&D and long-horizon strategy.
- Helps stress-test LLMs for mission-critical decision support.
Pros: Excellent for testing reasoning robustness.
Cons: Early-stage benchmark, less adoption in production contexts.
Also Read: Fine-Tuning Large Language Models (LLMs) in 2026
How Businesses Should Interpret LLM Leaderboards?
Here’s the trap many enterprises fall into: assuming the top-ranked model is the best fit. In reality:
- Raw scores ≠ readiness. High accuracy may come at the expense of deployment cost or latency.
- Generalist vs. Specialist. GPT-4 may top global rankings, but a smaller fine-tuned model could outperform it in a compliance-heavy financial workflow.
- Hidden Costs. Models with higher leaderboard scores often require more GPU memory, longer training, or higher inference costs.
CTOs should balance leaderboard insights with:
- Latency benchmarks – Critical for customer-facing apps.
- Compliance alignment – Does the model meet HIPAA, GDPR, or UAE data localization standards?
- Domain adaptation – Does it specialize in legal, medical, or multilingual contexts?
At Dextralabs, our methodology helps enterprises map leaderboard results to real-world ROI metrics, ensuring the chosen model is technically feasible, compliant, and cost-optimized.
Also Read: Best LLM for Coding: Choose the Best Right Now (2026 Edition)
Consider this example:
A UAE-based financial institution initially selected a leaderboard-topping model from Hugging Face. It performed well in general reasoning but struggled with compliance-heavy use cases, producing subtle errors in risk calculations.
Through Dextralabs’ enterprise evaluation framework, the client pivoted to a smaller, domain-adapted model. The outcome:
- 30% efficiency gains in processing compliance workflows.
- 40% reduction in inference costs.
- Improved auditability, reducing regulatory risk.
This case highlights why leaderboards are necessary but insufficient, and why expert interpretation matters.
The Future of LLM Leaderboards Beyond 2025
We expect leaderboards to evolve with greater enterprise alignment:
- Multimodal evaluations, models tested across text, image, audio, and video capabilities.
- Industry-specific metrics, compliance, governance, and performance in regulated environments.
- Regional leaderboards, for example, multilingual benchmarks like SEA-HELM, featuring Filipino, Indonesian, Tamil, Thai, and Vietnamese evaluations.
At Dextralabs, we anticipate integrating these real-world metrics, deployment success, domain fit, and governance standards into future model rankings.
Conclusion & Call to Action
The takeaway is clear: LLM leaderboards are powerful guides, but not the final word. They tell you which models perform best under certain conditions, but not whether they align with your business needs.
As models proliferate, organizations will need strategic partners who can interpret leaderboards, benchmark real-world deployments, and align AI with compliance, cost, and operational realities.
At Dextralabs, we partner with enterprises, SMEs, and startups to simplify LLM selection, deployment, and evaluation, ensuring your AI journey is built on a foundation stronger than raw numbers.
Let’s move beyond rankings to build AI strategies that truly deliver.
FAQs on llm leaderboard:
Q. Where can I find an LLM model leaderboard that ranks models by accuracy and speed?
You’ve got solid options! For open-source models, Hugging Face’s leaderboard shows accuracy benchmarks and lets you filter by speed (via quantization). For a broader view (including some proprietary models), HELM and OpenCompass often include latency metrics. And for real-time speed demons, Artificial Analysis has great visualizations of inference times. Pro tip: Always cross-check claims with your own hardware—cloud vs. on-prem can flip results!
Q. How often is the open LLM leaderboard updated?
Hugging Face’s Open LLM Leaderboard is basically live. Models are submitted constantly, and rankings shift daily—sometimes hourly! It’s the heartbeat of the OSS community. Others like LMSYS Chatbot Arena update in near real-time as humans vote. But if you’re tracking something like HELM, updates are more structured (think quarterly deep dives). Bottom line: For bleeding-edge OSS, Hugging Face is your always-fresh feed.
Q. What is the best LLM leaderboard in 2026?
(Laughs nervously) Trick question! There’s no single “best”—it’s like asking “What’s the best vehicle?” without saying if you’re hauling lumber or racing F1.
– For open-source transparency: Hugging Face.
– For chatbot conversational skills: LMSYS Chatbot Arena.
– For enterprise safety & compliance: Stanford HELM (it’s the most holistic).
– For code wizards: CanAiCode.
– For embedding whisperers: MTEB.
The smartest move? Use 2-3 complementary ones and never skip real-world testing.
Q. Which LLM leaderboard is the most comprehensive?
Hands down, Stanford HELM. It’s the most ambitious framework out there—testing 42 scenarios across 7 dimensions (accuracy, bias, toxicity, efficiency, robustness, calibration, and more). It’s like a 360-degree health check for models. But “comprehensive” doesn’t mean “perfect for your use case.” HELM’s academic rigor is awesome for due diligence, but it won’t tell you if Model X fits your budget or runs on your Dubai servers. Pair it with deployment-focused evals!






