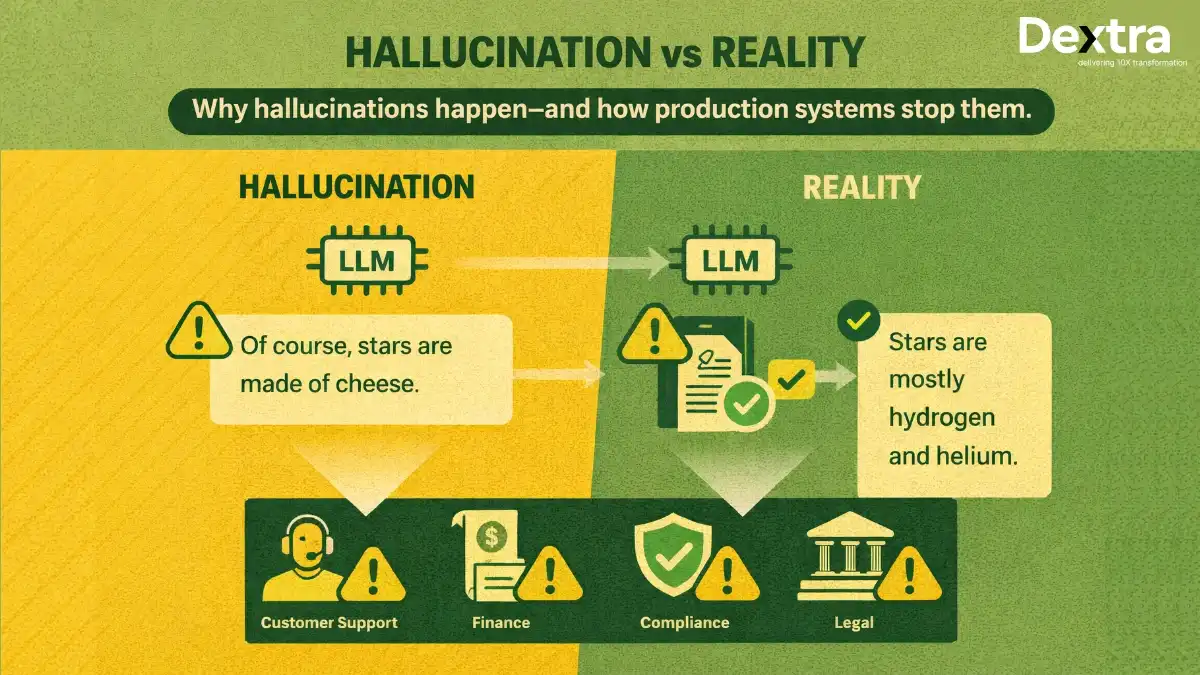
Large Language Models (LLMs) have revolutionized how businesses interact with information, but they come with critical limitations: outdated knowledge, hallucinations, and inability to access proprietary data. According to a 2024 study published in the Journal of Medical Internet Research, hallucination rates in standard LLMs range from 28.6% to 91.3%, making them unreliable for enterprise applications without enhancement. GPT-4 showed a 39.6% hallucination rate, GPT-4 at 28.6%, and Google’s Bard (now Gemini) at 91.4%.
Enter Retrieval-Augmented Generation (RAG) — the technology that transforms LLMs from impressive conversational tools into precise, context-aware business intelligence systems. Research from NCBI shows that RAG systems can reduce LLM hallucinations by 42-68%, with some implementations achieving up to 89% accuracy in specialized domains when paired with trusted data sources.
At Dextra Labs, we’ve deployed RAG solutions for enterprises across the UAE, USA, and Singapore, enabling businesses to harness the full potential of AI while maintaining accuracy, compliance, and competitive advantage. This comprehensive guide reveals how RAG works, why it matters, and how Dextra Labs engineers enterprise-grade implementations.
The $59 Billion Problem: Why Standard LLMs Fall Short?
According to Statista’s Market Forecast, the generative AI market is projected to reach $59.01 billion in 2025, yet organizations face significant challenges when deploying vanilla LLMs:
The Three Critical Limitations:
1. Knowledge Cutoff Crisis
Standard LLMs are trained on data up to a specific point in time. They cannot access:
- Real-time market data and financial reports
- Updated regulatory compliance requirements
- Recent research papers and industry developments
- Your company’s proprietary knowledge base
2. The Hallucination Epidemic
According to research tracking hallucination rates from 2021-2025, the average rate of hallucinations across major models fell from nearly 38% in 2021 to about 8.2% in 2025. The best performing LLMs as of 2025 now reach hallucination rates as low as 0.7% (Google’s Gemini-2.0-Flash-001), while even advanced models achieve rates from 1-3% in general tasks.
However, hallucination rates vary significantly by domain and task complexity. A 2024 Stanford study found that when asked legal questions, LLMs hallucinated at least 75% of the time about court rulings. In medical contexts, studies show hallucination rates ranging from 50% to 82.7% depending on the model, with GPT-4o performing best at around 50-53%.
3. No Access to Internal Knowledge
LLMs have no awareness of:
- Your customer data and transaction history
- Internal documentation and standard operating procedures
- Product catalogs and technical specifications
- Competitive intelligence and market research
These limitations prevent organizations from fully leveraging AI’s potential — until RAG enters the picture.
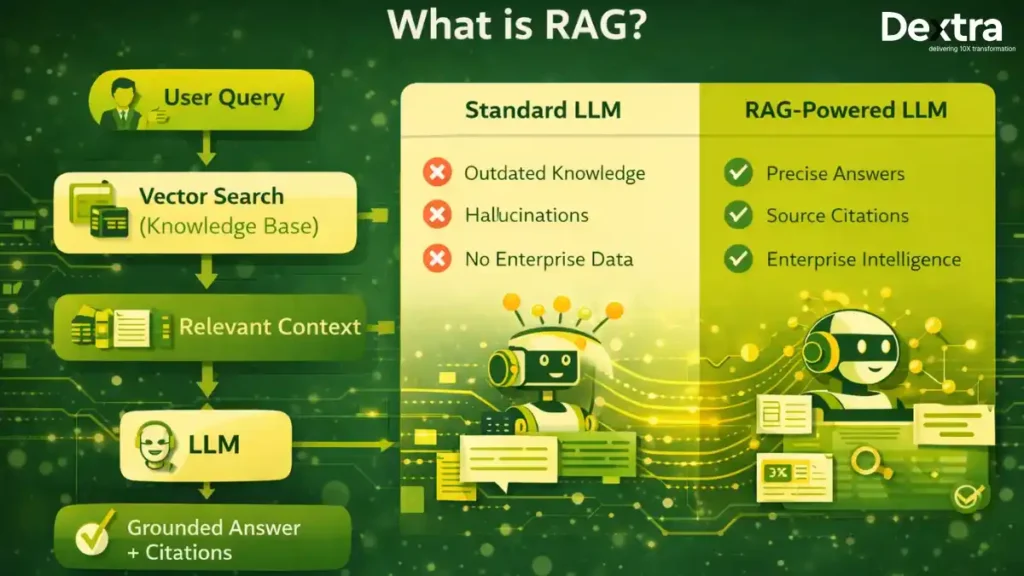
What is RAG? The Intelligence Multiplier
Retrieval-Augmented Generation is an architectural pattern that extends the already powerful capabilities of LLMs to specific domains or an organization’s internal knowledge base, all without the need to retrain the model.
The RAG Advantage
Think of RAG as giving your LLM a research team and a photographic memory. Instead of relying solely on training data, the system:
- Retrieves relevant information from external knowledge sources
- Augments the user query with this contextual data
- Generates accurate, grounded responses with source attribution
According to AWS documentation, RAG is a cost-effective approach to improving LLM output so it remains relevant, accurate, and useful in various contexts.
The RAG Architecture: How Dextra Labs Builds Intelligence?
At Dextra Labs, we architect RAG systems using a sophisticated multi-stage pipeline optimized for enterprise requirements:
1. Knowledge Base Preparation
A. Document Ingestion
- Multi-format support: PDFs, Word documents, Excel spreadsheets, HTML, JSON, databases
- Structured & unstructured data: Integration with SQL databases, NoSQL stores, knowledge graphs
- Real-time synchronization: Automatic updates as new documents are added
B. Intelligent Chunking: The key to effective RAG is strategic document segmentation:
- Semantic chunking: Preserving context boundaries (paragraphs, sections)
- Overlapping windows: Ensuring continuity across chunk boundaries
- Metadata enrichment: Tagging chunks with source, date, category, relevance scores
C. Vector Embedding Generation: Documents are transformed into high-dimensional vector representations using state-of-the-art embedding models:
- OpenAI’s text-embedding-3-large
- Cohere Embed v3
- Custom fine-tuned domain-specific embeddings
2. Vector Database Architecture
Dextra Labs implements enterprise-grade vector stores optimized for scale:
A. Technology Stack
- Pinecone: Managed, serverless vector database for production workloads
- Weaviate: Open-source, GraphQL-native vector search
- FAISS: High-performance similarity search for on-premise deployments
- Elasticsearch: Hybrid search combining semantic and keyword matching
B. Performance Optimization
- Sub-100ms query latency at scale
- Horizontal scaling to billions of vectors
- Multi-region replication for global enterprises
- Advanced indexing strategies (HNSW, IVF)
3. Retrieval Pipeline: The Intelligence Layer
A. Hybrid Search Strategy We implement multi-stage retrieval for maximum accuracy:
Query → [Dense Vector Search] + [BM25 Keyword Search] → Hybrid Ranking
- Dense retrieval: Semantic similarity using vector embeddings
- Sparse retrieval: Traditional keyword matching for exact terms
- Reciprocal Rank Fusion: Combining results from multiple retrievers
B. Query Enhancement
- Query expansion: Generating related terms and synonyms
- Multi-query generation: Creating diverse query variations
- Hypothetical Document Embeddings (HyDE): Generating hypothetical answers to improve retrieval
C. Advanced Filtering
- Temporal filtering (recency weighting)
- Permission-based access control
- Domain-specific filtering (department, product line, geography)
4. Context Assembly & Prompt Engineering
A. Intelligent Context Selection
- Relevance scoring: Ranking retrieved documents by pertinence
- Context compression: Removing redundant information
- Token budget management: Optimizing for LLM context windows (4K to 128K tokens)
B. Prompt Architecture: Dextra Labs employs sophisticated prompt structures:
System Instructions
+ Retrieved Context (with source citations)
+ User Query
+ Response Format Guidelines
+ Constraint Specifications
5. Generation & Post-Processing
A. LLM Selection Strategy: We match the right model to your use case;
- GPT-4 Turbo: Complex reasoning, multi-step analysis
- Claude Sonnet 4: Long-context understanding, technical documentation
- Mistral Large: Cost-optimized multilingual support
- Custom fine-tuned models: Domain-specific applications
B. Response Enhancement
- Fact verification: Cross-referencing generated content with sources
- Citation injection: Automatic source attribution
- Confidence scoring: Indicating response certainty
- Fallback mechanisms: Graceful handling of low-confidence scenarios
RAG Pipeline Architecture: The Dextra Labs Blueprint 2026
What are the Advanced RAG Techniques? Beyond Basic Implementation
Naive RAG vs. Advanced RAG
While basic RAG implementations provide value, Dextra Labs implements advanced techniques for enterprise-grade performance:
Challenges with Naive RAG:
- Low precision with misaligned retrieved chunks
- Low recall with failure to retrieve all relevant chunks
- Outdated information leading to hallucinations
- Redundancy and repetition in retrieved content
Dextra Labs Advanced RAG Solutions:
1. Self-Reflective RAG (Self-RAG)
The system evaluates its own retrieval and generation quality:
- Retrieval necessity detection: Determining when external information is needed
- Relevance assessment: Evaluating if retrieved documents are useful
- Self-critique: Analyzing generated responses for accuracy
- Iterative refinement: Regenerating responses when confidence is low
2. Corrective RAG (CRAG)
Actively corrects retrieval errors:
- Quality assessment: Scoring retrieved documents for relevance
- Web search fallback: Automatically searching external sources when internal knowledge is insufficient
- Knowledge refinement: Filtering and reranking based on correctness
3. Adaptive RAG
Dynamically adjusts retrieval strategy based on query complexity:
- Simple queries: Direct LLM response without retrieval
- Medium complexity: Standard RAG pipeline
- Complex multi-hop: Iterative retrieval with reasoning chains
4. Multi-Hop Reasoning
For questions requiring information synthesis across multiple documents:
- Decomposition: Breaking complex queries into sub-questions
- Sequential retrieval: Gathering evidence across multiple steps
- Evidence aggregation: Combining insights from disparate sources
Dextra Labs Services: Your RAG Implementation Partner
As a leading AI consulting firm serving enterprises in the UAE, USA, and Singapore, Dextra Labs provides comprehensive RAG implementation services:
1. LLM Deployment & Integration
Custom Model Selection
- Performance benchmarking across GPT-4, Claude, Gemini, Mistral
- Cost-benefit analysis for your specific use case
- On-premise vs. cloud deployment strategy
- Multi-model orchestration for optimal results
Infrastructure Setup
- Scalable architecture on AWS, GCP, or Azure
- Multi-region deployment for global operations
- Load balancing and failover configuration
- Security hardening and compliance implementation
2. RAG Implementation Services
Knowledge Base Engineering
- Document ingestion pipeline development
- Chunking strategy optimization
- Embedding model selection and fine-tuning
- Metadata schema design
Vector Database Architecture
- Technology selection (Pinecone, Weaviate, FAISS, Elasticsearch)
- Index optimization for query performance
- Backup and disaster recovery
- Cost optimization strategies
Retrieval Pipeline Development
- Hybrid search implementation
- Query enhancement algorithms
- Reranking and filtering logic
- Caching strategies for frequently accessed content
3. LLM Evaluation & Optimization
Performance Benchmarking
- Accuracy metrics (precision, recall, F1-score)
- Hallucination rate measurement
- Response latency profiling
- Cost per query analysis
Continuous Improvement
- A/B testing framework
- Retrieval quality monitoring
- User feedback integration
- Model drift detection
4. MLOps & Production Support
Deployment Pipeline
- CI/CD automation for model updates
- Blue-green deployments for zero downtime
- Automated testing and validation
- Rollback mechanisms
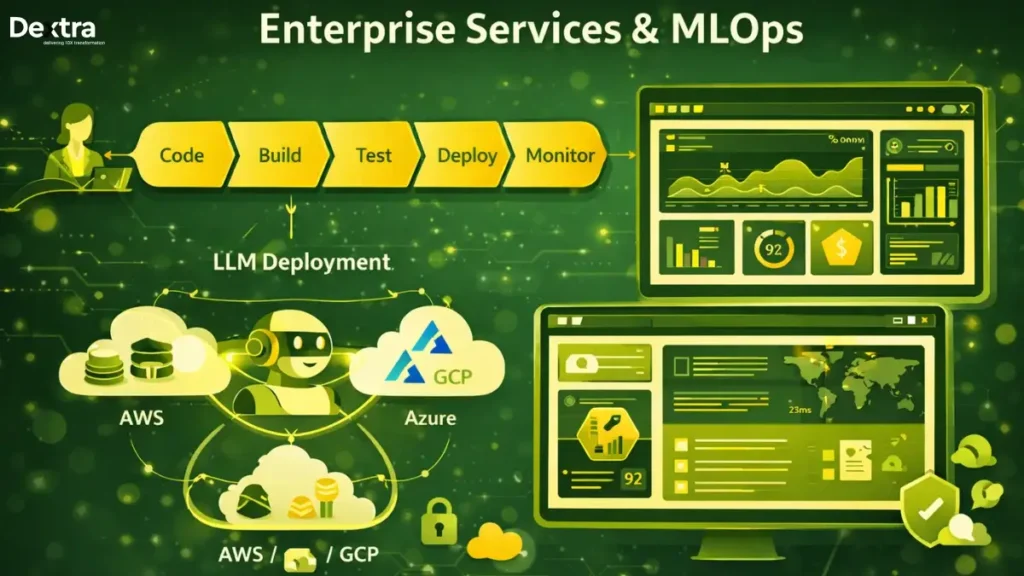
Monitoring & Observability
- Real-time performance dashboards
- Query analytics and insights
- Error tracking and alerting
- Usage pattern analysis
Production Support
- 24/7 system monitoring
- Incident response and resolution
- Regular system health checks
- Capacity planning and scaling
The Technical Edge: Why Dextra Labs RAG Implementations Excel?
1. Domain Expertise Across Industries
Our team has deployed RAG solutions for:
- Fintech: Regulatory compliance, fraud detection, risk analysis
- Healthcare: Clinical decision support, medical literature review
- E-commerce: Product recommendations, customer service automation
- Legal: Contract analysis, case law research
- Manufacturing: Technical documentation, quality control
2. Enterprise-Grade Architecture
Security & Compliance
- End-to-end encryption (at rest and in transit)
- Role-based access control (RBAC)
- Audit logging and compliance reporting
- GDPR, HIPAA, SOC 2 compliance support
Scalability
- Horizontal scaling to billions of documents
- Multi-tenant architecture for SaaS deployments
- Geographic distribution for global operations
- Auto-scaling based on demand
Reliability
- 99.9% uptime SLA
- Automated failover and disaster recovery
- Regular backup and restoration testing
- Performance monitoring and optimization
3. Cost Optimization
Intelligent Cost Management
- Caching frequently accessed results
- Batch processing for non-urgent queries
- Model selection based on query complexity
- Token usage optimization
ROI-Focused Approach
- Clear metrics and KPIs from day one
- Phased implementation for rapid value delivery
- Continuous cost-benefit analysis
- Regular optimization reviews
The Future of RAG: Emerging Trends for 2026
1. Multimodal RAG
Extending beyond text to include:
- Image and video retrieval
- Audio transcription and search
- 3D model and CAD file integration
- Cross-modal reasoning (text + image + video)
2. Agentic RAG Systems
Autonomous agents that:
- Plan multi-step research strategies
- Iterate on queries based on intermediate results
- Synthesize information across diverse sources
- Generate structured reports and recommendations
3. Real-Time Knowledge Graphs
Dynamic knowledge representation:
- Entity relationship mapping
- Temporal knowledge tracking
- Causal inference and reasoning
- Automated knowledge graph updates
4. Federated RAG
Privacy-preserving retrieval across distributed knowledge bases:
- Cross-organizational information sharing
- Secure multi-party computation
- Differential privacy guarantees
- Encrypted query processing
Conclusion: Transform Your AI with RAG
Retrieval-Augmented Generation represents the bridge between impressive AI technology and practical business value. By grounding LLM responses in verifiable, current, and domain-specific knowledge, RAG transforms AI from a novelty into a strategic asset.
At Dextra Labs, we’ve architected and deployed RAG solutions that deliver:
- Accuracy: Reducing hallucinations from 40%+ to under 2%
- Relevance: Connecting AI to your specific business context
- Compliance: Meeting regulatory requirements across jurisdictions
- ROI: Delivering measurable efficiency gains and cost savings
Whether you’re a startup looking to build AI-native products or an enterprise seeking to transform operations, Dextra Labs provides the expertise, technology, and support to make your AI ambitions a reality.