Fine tuning LLMs helps shape them to truly understand and perform well in specific tasks or industries, making AI more relevant and effective. Large Language Models (LLMs) represent the foundation of modern AI systems, trained on vast datasets to understand and generate human-like text. These models, including GPT-4, Claude, and LLaMA, demonstrate remarkable capabilities across diverse tasks but often lack the specialized knowledge required for specific business applications.
The year 2026 marks a critical inflection point for enterprise AI adoption. Organizations now have access to mature fine tuning llm tools, cost-effective compute resources, and proven methodologies that make customizing LLMs feasible at scale. Companies that master llm fine tuning will gain substantial competitive advantages through AI systems that understand their unique business contexts, terminology, and requirements.
Fine tuning llm creates this competitive edge by converting general-purpose models into specialized experts. Rather than relying on one-size-fits-all solutions, organizations can build AI systems that speak their industry’s language, follow their specific protocols, and deliver results aligned with their operational needs. LLM-focused firms like Dextralabs are helping enterprises transition from generic AI to task-specific agents that drive measurable business outcomes.

Ready to Fine-Tune Your Own LLM?
Let Dextralabs help you implement a custom AI model tailored to your data and business goals.
Explore Our Custom AI Implementation ServicesThe Strategic Importance of Fine-Tuning LLM
The difference between pre-trained generalists and specialized experts becomes apparent when examining real-world applications. A general-purpose LLM might provide accurate but generic responses, while a fine tuned llm delivers precise, contextually appropriate answers that reflect deep domain expertise.
Enterprise benefits of fine tuning llm extend beyond improved performance. Organizations achieve faster deployment cycles by reducing the prompt engineering required for consistent outputs. Fine-tuned llm also enable better compliance alignment, as they can be trained to follow specific regulatory requirements, ethical guidelines, and organizational policies from the ground up.
According to the research conducted by Ireland’s centre for AI, there is a compelling necessity from enterprises for fine tuning LLMs to get them trained on proprietary domain knowledge, with the challenge being to imbibe the LLMs with domain specific knowledge using the most optimal resource and cost.
Additionally, industry research from SuperAnnotate indicates that enterprises are increasingly exploring fine-tuning when encountering problems such as the need for domain-specific knowledge, difficulty controlling model output using just prompts, and high inference costs. The choice between fine-tuning and Retrieval-Augmented Generation (RAG) depends on your specific use case.
Fine tuning llm excels when you need consistent behavior across all interactions, have sufficient training data, and require the model to internalize complex domain knowledge. RAG works better for scenarios requiring access to frequently updated information, when training data is limited, or when you need to maintain strict control over information sources.
What are the types of LLM Fine-Tuning Techniques in 2026?

1. Supervised Fine-Tuning (SFT):
SFT remains the most common approach, using labeled examples to teach models specific tasks. This method works well when you have clear input-output pairs and want predictable, consistent results. According to the comprehensive LLM fine-tuning research SFT llm approaches are particularly effective for domain adaptation tasks.
2. Unsupervised Fine-Tuning:
It leverages unlabeled domain-specific text to help models better understand particular fields or industries. This approach proves valuable when you have extensive domain content but limited labeled examples for finetuning llm.
3. Instruction Tuning via Prompt Engineering:
It represents a hybrid approach that combines careful prompt design with light fine-tuning. This method offers quick iteration cycles and lower computational costs while still achieving significant performance improvements in llm fine tuning.
When comparing these approaches, consider that SFT typically delivers the highest accuracy but requires the most labeled data and computational resources. Unsupervised methods offer good scalability with lower data requirements but may provide less precise control over outputs. Instruction tuning strikes a balance between effectiveness and efficiency, making it ideal for rapid prototyping and resource-constrained environments when you fine tune llm.
The 7-Stage LLM Fine-Tuning Pipeline in 2026:
Research indicates that a structured seven-stage pipeline for llm fine-tuning spans data preparation, model initialization, hyperparameter tuning, and model deployment. This comprehensive approach ensures systematic and effective fine tuning llm models.
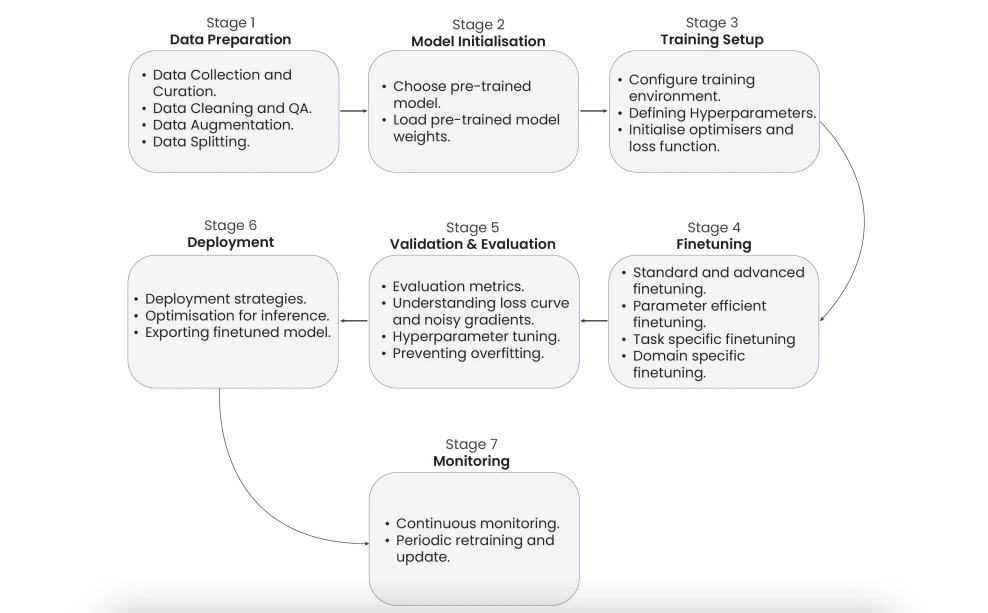
Stage 1: Dataset Preparation
Success begins with high-quality data. Source your training data from authoritative sources within your domain, ensuring it represents the full range of scenarios your model will encounter when you fine tune llm. Format consistency matters, establish clear standards for input structure, output format, and metadata annotation.
Data augmentation techniques can multiply your effective dataset size for finetuning llm. Consider paraphrasing existing examples, generating synthetic samples for underrepresented scenarios, and creating variations that test edge cases. Address data imbalance by identifying underrepresented categories and either collecting additional examples or using techniques like weighted sampling.
Ethical data curation requires careful attention to bias, privacy, and representation when fine tuning large language models. Remove personally identifiable information, check for demographic biases, and ensure your training data reflects the diversity of your intended user base. Tools like HuggingFace Datasets, Trifacta, and SNORKEL can streamline these processes while maintaining data quality standards.
Stage 2: Model Initialization
Choosing the right base model sets the foundation for success when it comes to how to fine tune llm. LLaMA 3, Mistral, and Mixtral each offer different strengths. Evaluate them based on your specific requirements for model size, performance, and licensing constraints for llm finetuning.
Model architecture adaptation involves determining which layers to modify and which to freeze. Freezing early layers often preserves general language understanding while allowing later layers to specialize for your domain when you fine-tune llm. Parameter freezing reduces computational requirements and can prevent overfitting when working with smaller datasets.
Stage 3: Training Environment Setup
Hyperparameter tuning significantly impacts results in llm fine tuning methods. Learning rate, batch size, and training duration require careful calibration based on your dataset size and computational resources. AdamW optimizer typically works well for most scenarios, while specialized optimizers like SGD may be preferable for certain architectures.
Infrastructure decisions affect both cost and performance when considering how to fine tune an llm. Cloud GPU services offer flexibility and access to cutting-edge hardware, while on-premises clusters provide better control over data security and long-term costs. Consider hybrid approaches that use cloud resources for experimentation and on-premises infrastructure for production training.
Stage 4: Fine-Tuning Strategies
Full Fine-Tuning updates all model parameters and typically delivers the best performance but requires substantial computational resources. Partial Fine-Tuning modifies only specific layers or components, reducing costs while often maintaining most of the performance gains.
Parameter-Efficient Fine-Tuning (PEFT) techniques like LoRA, QLoRA, and DoRA offer compelling alternatives for fine tune llm. LoRA (Low-Rank Adaptation) adds small adapter layers that capture task-specific knowledge while keeping the base model frozen. QLoRA combines LoRA with quantization to further reduce memory requirements. DoRA (Weight-Decomposed Low-Rank Adaptation) provides even better parameter efficiency.
Advanced techniques continue to emerge. Memory tuning approaches like those developed by Lamini enable efficient knowledge storage and retrieval. Mixture of Experts (MoE) architectures activate different model components based on input characteristics. Mixture of Agents (MoA) coordinates multiple specialized models for complex tasks.
Stage 5: Evaluation and Validation
Robust evaluation requires multiple metrics for fine tune large language model. Cross-entropy loss provides a fundamental measure of model confidence, while task-specific metrics like BLEU for translation or ROUGE for summarization offer domain-relevant assessments. Safety benchmarks such as LlamaGuard and ShieldGemma help ensure responsible AI behavior.
Monitor training carefully for signs of overfitting, which appears as diverging training and validation performance when how to finetune llm. Noisy gradients may indicate learning rate issues or data quality problems. Loss curves should show steady improvement without erratic fluctuations.
Stage 6: Deployment Optimization
Optimize your fine-tuned llm for production through quantization, which reduces model size and memory requirements while maintaining performance. WebGPU enables browser-based inference for certain applications. Distributed serving approaches, including torrent-style model distribution and vLLM implementations, can improve scalability and reduce latency.
Consider inference efficiency carefully when fine tuning language models. Techniques like speculative decoding, key-value caching, and attention optimization can significantly reduce response times and computational costs in production environments.
Stage 7: Post-Deployment Monitoring & Maintenance
Establish continuous feedback loops that capture user interactions, model performance, and potential issues in llm tuning. Implement prompt and response auditing systems that help identify drift, bias, or quality degradation over time.
Plan for knowledge updates and retraining cycles for fine tune llms. As your domain evolves, your model needs fresh data and periodic retraining to maintain relevance and accuracy. Develop automated pipelines that can incorporate new data while preserving existing capabilities.
Popular Tools and Frameworks in 2026
Autotrain by HuggingFace provides an accessible entry point for organizations new to llm finetune. Its automated approach handles many technical details while still allowing customization for specific needs.
Amazon SageMaker JumpStart offers pre-configured environments and model selections, while Bedrock provides managed fine-tuning services with enterprise-grade security and compliance features. Choose JumpStart for hands-on control or Bedrock for managed simplicity when how to finetune a llm.
OpenAI’s Fine-Tuning API delivers convenience and integration with existing OpenAI services, though it limits access to underlying model details and customization options for what is llm fine tuning.
NVIDIA NeMo excels for organizations requiring maximum control and performance optimization, particularly when working with large-scale deployments or custom architectures in large language model fine tuning.
Each tool offers distinct advantages. Evaluate them based on your team’s technical expertise, integration requirements, budget constraints, and compliance needs for what is fine tuning llm.
Multimodal and Audio-Language LLM Fine-Tuning
Vision-language models enable text-image understanding, useful for document analysis, visual QA, and content generation—especially when exploring how to fine tune a LLM. Speech-text models like Whisper create opportunities for voice-enabled interfaces and automated transcription services.
Healthcare applications benefit from finetuning large language models trained on medical imaging and clinical notes. Manufacturing systems can combine visual inspection data with maintenance logs for predictive analytics. Educational platforms use multimodal models to create interactive learning experiences that adapt to different content types.
Fine tuning language model Whisper for Automatic Speech Recognition demonstrates the potential of specialized audio models. Domain-specific training can improve accuracy for technical terminology, accented speech, or noisy environments while maintaining general speech recognition capabilities.
Key Challenges and Emerging Research Areas
Scalability and Compute remain primary concerns in supervised fine tuning llm. Hardware-algorithm co-design approaches aim to optimize both software and hardware for specific fine-tuning tasks. New architectures and training methods continue to reduce computational requirements while maintaining or improving performance.
Ethics and Privacy considerations require ongoing attention when how to fine tune llm models. Fairness assessment tools help identify and mitigate bias in fine-tuned models. Hallucination control techniques prevent models from generating false information confidently. Explainability methods help users understand model reasoning and identify potential issues.
Accountability Frameworks establish transparent AI pipelines that enable auditing and compliance verification for how to fine tune llm on custom data. These frameworks become increasingly important as fine-tuned models handle sensitive decisions and regulated processes.
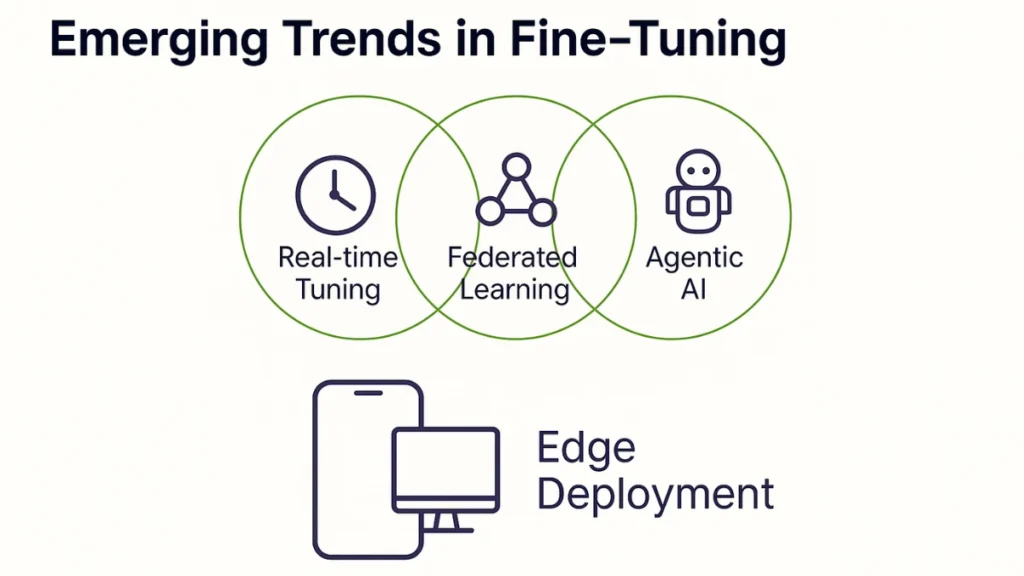
Emerging opportunities include real-time tuning systems that adapt continuously to new data, federated fine-tuning approaches that enable collaborative model development while preserving data privacy, and edge deployment solutions that bring fine-tuned capabilities to resource-constrained environments.
Fine-Tuning vs RAG 2026: When to Choose What?
According to the research by CeADAR Ireland’s Centre For AI, fine-tuning is specifically aimed to allow a model to perform a task different from the task it was initially trained on, leveraging knowledge from large datasets and applying it to specific domains. The research shows that despite better-performing models, we still need either model fine-tuning for generating customized responses or use Retrieval-Augmented Generation (RAG) systems to provide extra context to the base model.

Additionally, SuperAnnotate’s industry analysis indicates that fine-tuning becomes necessary when businesses face specialized situations that broadly trained models may not address well.
| Factor | Fine-Tuning | RAG | Best Use Cases |
| Knowledge Updates | Periodic retraining required | Real-time information access | Fine-tuning: Stable domains; RAG: Rapidly changing information |
| Data Requirements | Large labeled datasets | Smaller, structured knowledge bases | Fine-tuning: Rich training data; RAG: Limited examples |
| Computational Cost | High training, lower inference | Lower training, higher inference | Fine-tuning: High-volume applications; RAG: Occasional use |
| Customization Depth | Deep behavioral modification | Surface-level information retrieval | Fine-tuning: Specialized behavior; RAG: Information lookup |
| Latency | Lower response times | Higher due to retrieval step | Fine-tuning: Real-time applications; RAG: Acceptable delays |
Hybrid approaches combine both techniques, using fine-tuning for consistent behavior and domain understanding while employing RAG for accessing current information and specific facts. This combination often delivers optimal results for complex enterprise applications.
How Enterprises Can Adopt Fine-Tuning Effectively in 2026?
Evaluate your organization’s readiness by assessing data availability, technical expertise, computational resources, and business objectives for types of llm. Start with pilot projects that demonstrate clear value while building internal capabilities and confidence.
Budget planning should account for compute costs, data preparation expenses, ongoing maintenance, and team structure when fine tuning an llm. Initial investments may seem substantial, but successful fine-tuning projects typically deliver significant long-term returns through improved efficiency and competitive advantages.
Consider working with experienced AI partners to accelerate your adoption timeline when llm fine tune. Organizations like Dextra Labs can help bridge the gap between proof-of-concept experiments and production-ready systems, reducing risks and shortening development cycles.
Build internal expertise gradually in llm sft. Start with simpler projects using managed services, then progressively take on more complex implementations as your team develops skills and confidence. This approach minimizes risks while building sustainable capabilities.
Final Thoughts: The Future of Fine-Tuning LLMs
Personalization at scale represents the next frontier for fine-tuned llm. Future systems will adapt continuously to individual user preferences, organizational contexts, and evolving business requirements while maintaining consistency and reliability.
The rise of agentic AI systems will depend heavily on fine-tuning capabilities. These systems require models that understand specific domains deeply enough to make autonomous decisions, interact with specialized tools, and maintain context across complex multi-step processes.
The evolution from model fine-tuning to outcome fine-tuning will focus optimization efforts on business results rather than technical metrics. This shift will drive development of new evaluation methods, training objectives, and deployment strategies that align AI capabilities directly with organizational success.
Fine-tuning LLMs in 2025 offers unprecedented opportunities for organizations ready to move beyond generic AI solutions. Success requires careful planning, appropriate tool selection, and commitment to ongoing learning and improvement. Organizations that invest in fine-tuning capabilities now will establish competitive advantages that compound over time, creating AI systems that truly understand and serve their unique business needs.
FAQs on Fine Tuning for LLMs:
Q. Is it possible to fine-tune an LLM with a small dataset? Will it still work well?
Yes, you can fine-tune with a smaller dataset—especially using techniques like LoRA or QLoRA—but the key is quality over quantity. A well-curated, task-specific dataset can still deliver great results without overwhelming compute costs. However, the model might not generalize as broadly compared to training on larger, more diverse data.
Q. How do I stop my model from forgetting what it already knows while fine-tuning?
That’s a common concern called catastrophic forgetting. To avoid it, you can use strategies like gradual unfreezing, regularization, or parameter-efficient fine-tuning (like adapters or LoRA), which update only parts of the model while keeping the rest intact. It’s all about balance—teaching new skills without erasing the old ones.
Q. What kind of hardware do I need to fine-tune a large language model?
The hardware depends on the size of the model and the tuning approach. For full fine-tuning of models like LLaMA 2 or Mistral, you’ll need powerful GPUs—typically A100s or H100s. For lighter methods like QLoRA, even a single RTX 3090 or A6000 can work. Cloud options like AWS, GCP, or Hugging Face also offer scalable infrastructure without upfront hardware investment.








