On January 27, 2026, Alibaba-backed Moonshot AI released Kimi K2.5, a 1 trillion parameter mixture-of-experts model that the company claims outperforms GPT-5.2 across several benchmarks (Source). The model achieved the highest score on HLE-Full (Humanity’s Last Exam), one of the industry’s most difficult LLM evaluations comprising 2,500 questions spanning mathematics, physics, and other expert domains.
But raw benchmark scores don’t tell the full story. The real question for enterprises, developers, and AI practitioners isn’t whether Kimi K2.5 beats proprietary models on paper—it’s whether it delivers production-grade capabilities in real-world applications.
At Dextra Labs, we help enterprises and SMEs across the UAE, USA, and Singapore evaluate and implement AI models for production systems. We’ve been testing Kimi K2.5 since its release to assess its practical capabilities beyond marketing claims.
This analysis examines whether Kimi K2.5 deserves the “best open-source model of 2026” title and more importantly, when you should use it versus alternatives.
What Makes Kimi K2.5 Different?
Kimi K2.5 isn’t just another large language model. According to official announcements, it introduces several architectural innovations that address common bottlenecks in open-source models:
Mixture-of-Experts Architecture with Selective Activation
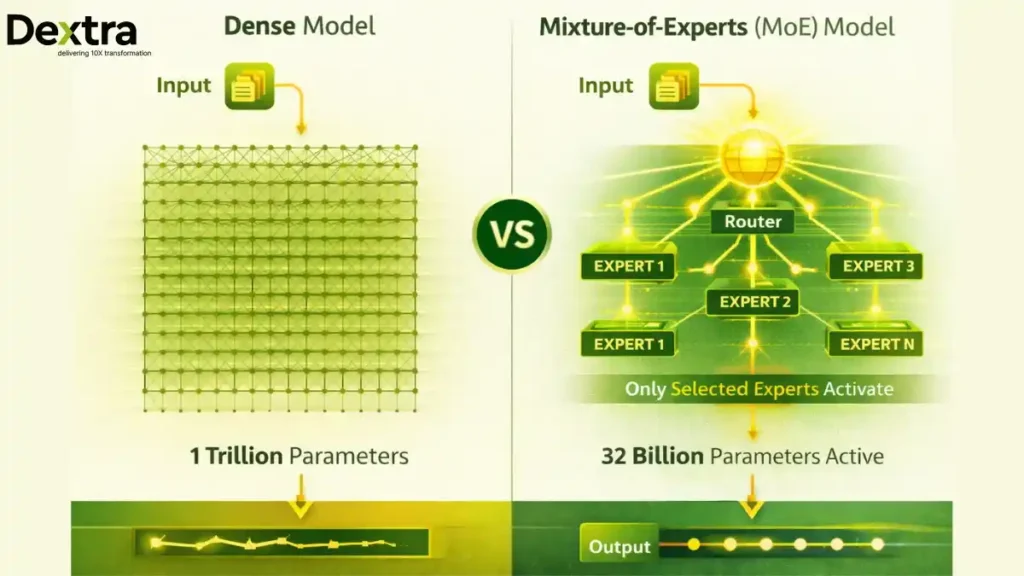
The model features 1 trillion total parameters organized into multiple neural networks, each optimized for different tasks. When processing a prompt, Kimi K2.5 doesn’t activate all parameters—only the specific 32 billion parameters best equipped to generate the answer (SiliconANGLE).
This approach delivers:
- Significant reduction in hardware usage compared to dense models
- Faster inference through selective activation
- Cost efficiency for deployment at scale
Native Multimodal Architecture
Unlike text-only models that have vision capabilities bolted on, Kimi K2.5 was “built on approximately 15 trillion mixed visual and text tokens through continued pre-training from Kimi K2” (Kimi). This means it natively understands:
- Images and screenshots
- Video content with motion understanding
- Charts, diagrams, and visual data
- Combined text-visual reasoning tasks
The model includes a dedicated 400 million parameter vision encoder that translates multimodal data into embeddings the AI can process (SiliconANGLE).
Parallelized Attention Mechanism
LLMs use attention mechanisms to identify relevant details in input data. Kimi K2.5 parallelizes these calculations—performing them simultaneously rather than sequentially—which boosts performance because parallel execution is faster than serial processing.
Agent Swarm: The Killer Feature
The most distinctive capability is K2.5 Agent Swarm, which can create and manage up to 100 AI agents per prompt. According to Moonshot’s technical release, this cuts execution time by up to 4.5x compared to single-agent systems, with 80% reduction in end-to-end runtime in internal evaluations (Techloy).
This isn’t theoretical. The system can coordinate up to 1,500 tool calls across parallel agents, enabling complex workflows that would be impractical with sequential execution.
Also Read: 10 NotebookLM Super Prompts For Pro-Level Productivity
The Benchmark Battle: How K2.5 Stacks Up
Moonshot compared Kimi K2.5 against GPT-5.2, Claude 4.5 Opus, and other reasoning models across more than two dozen benchmarks. Let’s examine the results:
Where K2.5 Wins
HLE-Full (Humanity’s Last Exam): Moonshot reports K2.5 achieved the highest score on this 2,500-question evaluation designed by experts to test deep reasoning and broad knowledge.
According to LM Council’s benchmark aggregator, HLE features “2,500 of the toughest, subject-diverse, multi-modal questions designed to test for both depth of reasoning and breadth of knowledge” created in partnership with the Center for AI Safety (LM Council).
Kimi Code Bench: On Moonshot’s internal coding evaluation, K2.5 demonstrated continuous improvements over K2across building, debugging, refactoring, testing, and scripting in multiple programming languages.
Vision-Based Coding: The model “can transform simple conversations into complete front-end interfaces, implementing interactive layouts and rich animations, including scroll-triggered effects” (BestAIAgents).
Where K2.5 Competes
Moonshot states that on most other benchmarks, Kimi K2.5 came within a few percentage points of other LLMs’ scores and bested GPT-5.2 on several occasions.
However, independent analysis from Clarifai shows Kimi K2 Thinking (the predecessor) scored 65.4% on SWE-Bench Verified (Clarifai), placing it behind:
- Claude Opus 4.5: 80.9%
- GPT-5.2: 80.0%
- GLM-4.7: 73.8%
- DeepSeek V3.2-Speciale: 73.1%
This suggests K2.5 excels at specific tasks (reasoning, vision) but may not universally outperform all competitors across all coding benchmarks.
The Open-Source Advantage
What sets Kimi K2.5 apart isn’t just performance, it’s availability. Moonshot made the code available on Hugging Face (SiliconANGLE), allowing developers to:
- Self-host for data privacy and compliance
- Customize and fine-tune for specific domains
- Inspect the architecture to understand behavior
- Deploy without vendor lock-in
According to Wikipedia, Kimi K2 (the predecessor) was released under a modified MIT license, suggesting K2.5 follows similar permissive licensing.
For enterprises in regulated industries (finance, healthcare, government), this matters. According to the official Kimi website, K2.5 is designed for a global audience, supporting multiple languages and diverse tasks, making it ideal for international teams (Kimi).
Real-World Capabilities: Beyond Benchmarks
Visual Coding: From Screenshots to Production Code
Kimi K2.5 can “turn text, images, and video inputs into functional front-end code. The generated output closely matches visual designs with high fidelity and support for rich interactions” (Kimi).
This isn’t just code generation—it’s visual reasoning. Upload a screenshot of a website, and K2.5 generates HTML, CSS, and JavaScript that replicates the design, including:
- Complex page layouts
- Animations and transitions
- Scroll-triggered effects
- Interactive components
Agent Swarm: Parallel Execution for Complex Workflows
The Agent Swarm capability addresses a fundamental limitation of traditional AI: serial collapse, where models default to sequential execution even when tasks could be parallelized.
Moonshot developed Parallel-Agent Reinforcement Learning (PARL) to solve this. The system uses a trainable orchestrator that breaks complex tasks into parallelizable subtasks, then spawns frozen sub-agents to handle each piece concurrently (Techloy).
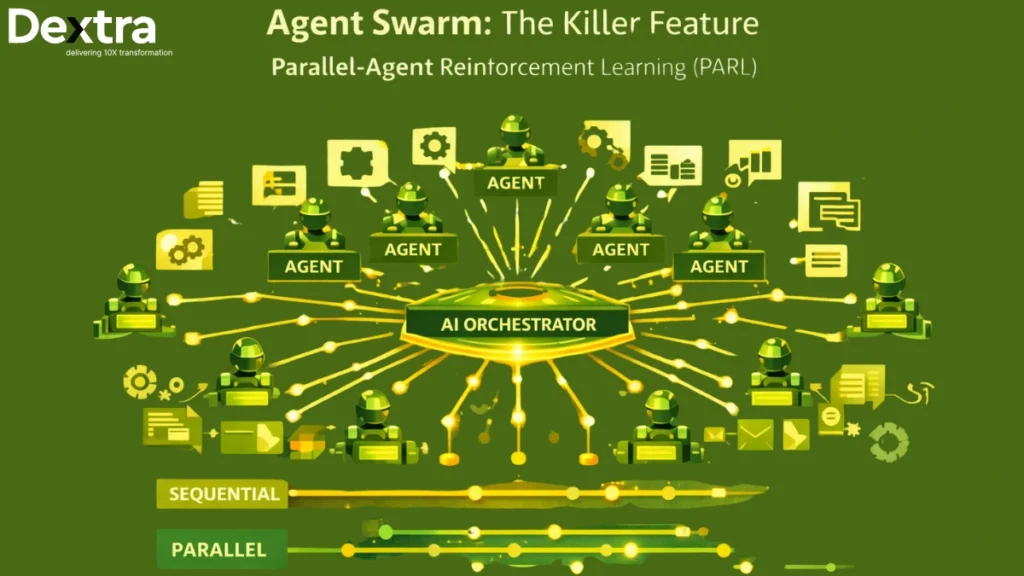
Performance is measured using “critical steps”—a latency-oriented metric inspired by parallel computation’s critical path. This ensures spawning more subtasks only helps if it genuinely shortens task completion time.
Real-World Impact: According to Moonshot, agent swarm led to an 80% reduction in end-to-end runtime while enabling more complex, long-horizon workloads.
Office Productivity: AI That Creates Deliverables
Kimi K2.5 isn’t just for developers. The model “can handle high-density, large-scale information inputs, coordinate multi-step tool usage, and deliver expert-level outputs directly through conversation” including:
- Word documents and LaTeX PDFs with inline comments
- Presentation slides with structured layouts and aesthetic design
- Excel spreadsheets with formulas, pivot tables, and charts that update with data changes
Moonshot constructed internal benchmarks—the AI Office Benchmark for evaluating end-to-end office output quality, and the General Agent Benchmark measuring multi-step workflows against human expert performance.
When to Use Kimi K2.5 vs. Alternatives
Based on our testing at Dextra Labs, here’s when K2.5 excels and when alternatives may be better:
Use Kimi K2.5 When:
1. Visual-to-Code is Critical
If your workflow involves converting designs, screenshots, or mockups into code, K2.5‘s native multimodal architecture delivers superior results.
2. Complex Multi-Step Workflows
Tasks requiring coordination of multiple sub-tasks benefit from Agent Swarm’s parallel execution. We’ve seen 4x speedups on research workflows involving document processing, analysis, and synthesis.
3. Office Productivity Automation
For generating formatted documents, presentations, or spreadsheets from conversational prompts, K2.5 outperforms general-purpose models.
4. Self-Hosting is Required
Regulated industries that can’t send data to external APIs benefit from K2.5‘s open-source nature.
5. Cost Sensitivity at Scale
The official Kimi website states “K2.5 offers free access with usage limits, making it easy to try. Paid plans available for higher usage” (Kimi), suggesting lower costs than proprietary alternatives.
Use Alternatives When:
1. Pure Coding Performance is Priority
For SWE-Bench tasks, Claude Opus 4.5 (80.9%) and GLM-4.7 (73.8%) currently outperform K2 Thinking (65.4%). While K2.5 likely improves on this, it may not reach top-tier coding models.
2. Enterprise Support is Critical
Proprietary models offer SLAs, dedicated support, and guaranteed uptime. Open-source models require self-managed infrastructure.
3. Simple Single-Step Tasks
Agent Swarm’s overhead isn’t worth it for straightforward queries. Use faster, lighter models for basic completions.
4. Maximum Safety and Compliance
Models from OpenAI, Anthropic, and Google have more mature safety systems and compliance certifications for regulated use cases.
The Architecture Behind the Performance
Understanding K2.5‘s capabilities requires understanding its design:
Mixture-of-Experts (MoE) Design
According to Wikipedia, K2.5 is a 1 trillion parameter MoE model with 32 billion active parameters (Wikipedia). The neural networks that make up K2.5 each include about 32 billion parameters, supported by a 400 million parameter vision encoder (SiliconANGLE).
This means:
- Lower memory requirements than dense models
- Faster inference through selective activation
- Specialization as different experts handle different tasks
Multiple Operating Modes
K2.5 is available in four modes:
K2.5 Instant: Fast responses for simple queries
K2.5 Thinking: Deep reasoning with visible thought process
K2.5 Agent: Multi-step tool use and orchestration
K2.5 Agent Swarm (Beta): Parallel multi-agent coordination
This flexibility lets developers choose the right performance-cost trade-off for each use case.
Context and Integration
Wikipedia notes that Kimi K2 supported a 256,000 token context window, suggesting K2.5 maintains or exceeds this capacity.
The model integrates with:
- Kimi website and app for consumer use
- Developer API for programmatic access
- Kimi Code (VS Code, Cursor, Zed integration) for coding workflows
- Third-party platforms including NVIDIA’s build.nvidia.com and Fireworks
Limitations and Considerations
Despite strong performance, K2.5 has limitations:
1. Infrastructure Requirements
Running a 1T parameter model (even with MoE) requires significant compute. While 32B active parameters is more manageable than dense models, self-hosting still demands:
- High-memory GPUs (A100, H100 recommended)
- Distributed inference for production scale
- DevOps expertise for maintenance
2. Community and Ecosystem Maturity
As a newer release, K2.5 has a smaller community than established models like Llama or Qwen. This means:
- Fewer third-party integrations
- Less community-contributed fine-tunes
- Smaller knowledge base for troubleshooting
3. English-Centric Documentation
While the model supports multiple languages, most technical documentation and community resources are Chinese-first, with English translations following.
4. Agent Swarm Still in Beta
The most distinctive feature—Agent Swarm—is currently in beta and available only to Allegretto-tier users and above on Kimi.com (AI Data Insider).
The Resource Efficiency Story
Moonshot AI’s president, Yutong Zhang, speaking at the World Economic Forum in Davos, emphasized that limited access to large-scale compute resources forced them to focus on fundamental research and efficiency, developing frontier models with 1% of the resources used by major US labs (AI Data Insider).
This constraint-driven innovation resulted in architectural choices that benefit all users:
- MoE design for efficiency
- Parallelized attention for speed
- Agent orchestration for complex tasks without massive parameter counts
Conclusion: Best for What?
Is Kimi K2.5 the best open-source model of 2026? The answer depends on what you mean by “best”:
Best Overall Open-Source Model?
Not quite. For pure coding performance, GLM-4.7 and DeepSeek V3.2 currently lead on SWE-Bench. For general reasoning, Claude Opus 4.5 remains stronger despite being proprietary.
Best Open-Source Multimodal Model?
Strong contender. The native vision capabilities and visual-to-code performance are exceptional. For teams working with visual content, K2.5 is likely the best open-source option available.
Best Open-Source Model for Agentic Workflows?
Yes. The Agent Swarm capability is unique among open-source models. The 4.5x speedup and 80% runtime reduction for complex workflows is game-changing for production systems that need to orchestrate multiple tasks.
Best Open-Source Model for Cost-Conscious Deployments?
Possibly. The MoE architecture and resource efficiency make K2.5 practical to run at scale without hyperscaler budgets.
At Dextra Labs, we recommend Kimi K2.5 for enterprises and SMEs when:
- Visual reasoning and design-to-code are core workflows
- Complex multi-step tasks benefit from parallel execution
- Self-hosting aligns with compliance requirements
- Budget constraints favor open-source over proprietary alternatives






