Big, brainy AI is no longer just the stuff of sci-fi movies or the plaything of tech giants. In 2025, Large Language Models (LLMs) are reshaping how businesses of every size talk to customers, dig into data, and even create entirely new products. And at the heart of this revolution? LLM deployment on cloud platforms, the fastest, smartest way to harness these digital marvels.
LLM deployment on cloud platforms is revolutionizing how businesses operate, with LLM deployment on AWS Azure GCP leading the charge. From solving tough problems to creating new ways for companies to connect with their customers, LLMs are the new stars on the technology stage. But the secret sauce isn’t just clever algorithms. It’s the shift to cloud-based AI platforms that truly allows these models to shine. For businesses, deploying LLMs in the cloud eliminates the need for costly hardware while offering scalability and flexibility. It is like giving access to powerful tools without the heavy costs and headaches of managing hardware. No wonder so many founders are picking AWS, Azure, or Google Cloud, they let you scale instantly, experiment freely, and stay competitive.
Here’s a number that says it all: an impressive 75% of enterprise AI workloads are cloud-deployed in 2025 (IDC). The cloud is no longer just an option, it’s the default. In this blog, we’ll explore why the cloud is driving this AI revolution, how major providers compare, and what you need to know before choosing your platform.

Future-Proof Your AI Infrastructure
Partner with Dextralabs for end-to-end LLM packaging, cloud deployment, and intelligent monitoring.
Book Your free AI ConsultationKey Considerations Before Choosing a Cloud Provider:
Jumping into LLM deployment on AWS Azure GCP isn’t about chasing the fanciest feature list. Make your choice with your end goals front and center by considering these essentials:
1. Compute power requirements (e.g., GPU types for inference)
LLMs are like marathon runners, they thrive on energy and speed. You’ll want modern GPUs like NVIDIA A100 or H100 to serve users quickly. Some platforms have long waitlists for these, so check availability in your location.
Example: If your chatbot is handling customer requests all day long, a single consumer GPU is like sending it into a marathon with flip-flops. For real performance, you’ll need those cloud-powered, GPU-accelerated legs. AWS offers cutting-edge GPUs like NVIDIA A100 and H100, making it a top choice for GPU-accelerated LLM deployment.
2. Budget: Pay-as-you-go vs reserved pricing
Cloud bills can grow fast! Pay-as-you-go keeps it simple for experimentation, but if you plan to stick around, reserved pricing or spot instances might save you serious cash. Heads-up: GPU-backed managed endpoints cost 3–5x more than CPU endpoints (AWS Pricing, 2025).
3. Time to market: Managed vs custom deployment
Managed services like SageMaker, Azure ML, or Vertex AI mean you can hit the ground running. Want more control? Roll up your sleeves and build on custom VMs or containers for your best shot at peak performance.
4. Vendor lock-in risks
Do your tools rely too much on any single provider’s magic? Plan for the future with open architectures, so you don’t get trapped or face roadblocks if you want to switch later.
5. Security and compliance needs
If you’re dealing with sensitive data, don’t skimp here. The good news: top cloud platforms are battle-tested for SOC2, HIPAA, GDPR, and more.
6. Data locality and residency laws
For global products, you may need to keep data in specific countries. Make sure your provider supports the right data residency and locality controls.
LLM Deployment on AWS: Amazon SageMaker, Bedrock & ECS
AWS is the Swiss Army knife for AI, loaded with features and ready for everything from quick experiments to massive, global-scale rollouts.
Services to Know:
Have a look at the services to know:
- Amazon SageMaker: Your all-in-one playground for hosting large language models and automating MLOps pipelines, perfect for scaling up and down as needed. With SageMaker LLM deployment, businesses can quickly scale their AI models while leveraging AWS’s robust infrastructure.
- AWS Bedrock: Access top-tier foundation models (like Claude and GPT) via simple APIs, think “AI as a service” for hassle-free starts.
- Amazon ECS (custom container deployments): Build containerized LLM projects for flexible, high-performance solutions.
- AWS Lambda (lightweight inference tasks): Run small, event-driven inference jobs with instant spin-up.
Deployment Process:
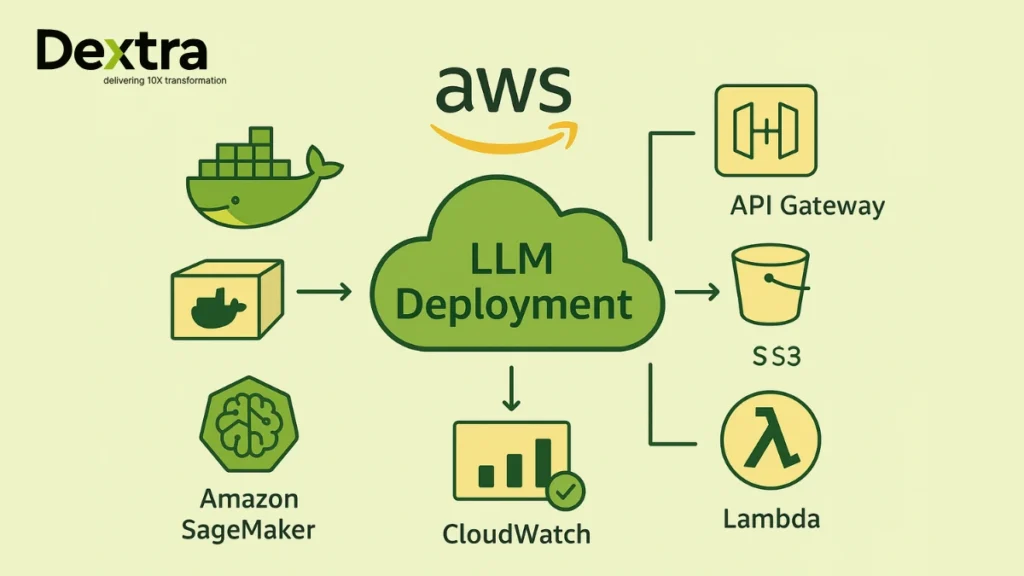
Let’s comprehend the deployment process:
- Containerizing the model with Docker makes it portable and ready for cloud ingestion.
- Creating SageMaker endpoints launch flexible, autoscaling LLM inference endpoints. The flexibility of SageMaker LLM deployment makes it ideal for teams experienced in MLOps workflows.
- Integrating with API Gateway for serving secure, scalable access to your LLM from anywhere.
- Storing model artifacts in S3 your well-organized digital closet for model files.
- Implementing autoscaling & monitoring with CloudWatch real-time scaling and alerting for smooth performance.
Ideal For:
- Teams with MLOps experience
- Use cases needing high control + scalability
Stat Break: SageMaker supports 1.2M + model endpoints monthly (AWS Blog, 2025).
LLM Deployment on Microsoft Azure: Azure ML, OpenAI & AI Studio
Enterprises leveraging Microsoft’s ecosystem can benefit from Azure Machine Learning LLM deployment for secure and scalable AI solutions. Hence, if your business works and breathes Microsoft, Azure is built for you. Security, compliance, and API access to the world’s favorite LLMs, it’s all here.
Services to Know
The tools provided by Azure Machine Learning LLM deployment simplify the process of training and fine-tuning models. Have a look at the services to know:
- Azure Machine Learning
- Azure OpenAI Service (access to GPT models)
- Azure AI Studio for GenAI apps
- Azure Container Instances for custom workloads
Deployment Process
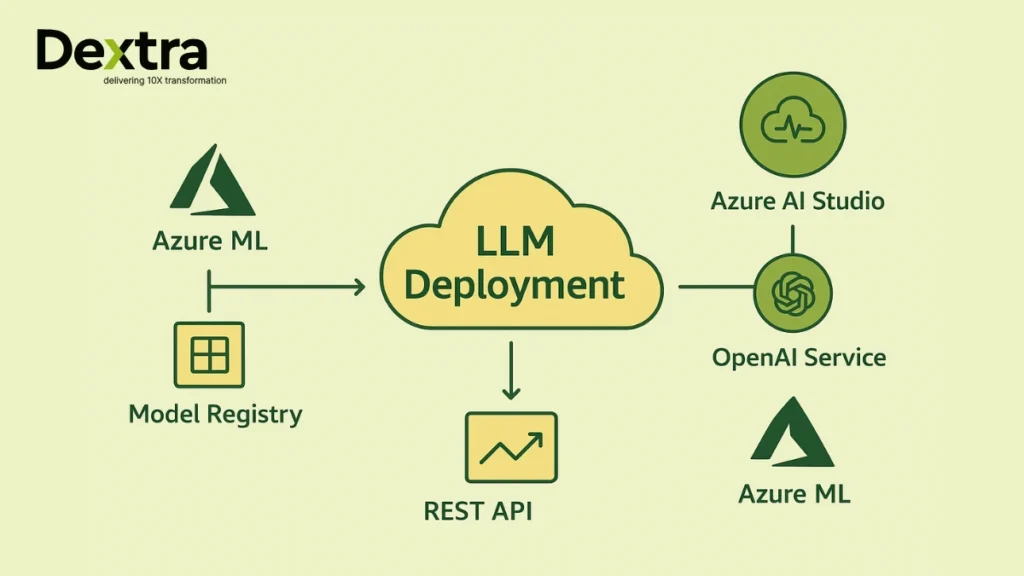
Let’s comprehend the deployment process:
- Training or fine-tuning via Azure ML gets your LLM ready for your unique data.
- Creating online endpoints plug your models into web apps with secure REST APIs.
- Inference via REST APIs serve predictions to users worldwide.
- Versioning and model registry integration handle upgrades safely and efficiently.
- Performance monitoring using Azure Monitor spot issues fast.
Ideal For
Take a look:
- Enterprises already in Microsoft ecosystem
- Scenarios requiring Azure OpenAI access
Did You Know? Azure OpenAI use grew 3x in EMEA from 2023 to 2025, that’s serious momentum. The demand for Azure OpenAI deployment has surged, especially in EMEA markets, as businesses seek seamless access to GPT models.
LLM Deployment on Google Cloud: Vertex AI & GCP Custom Infra
Google Cloud is the go-to playground for engineers who love TensorFlow, JAX, and rapid innovation.
Services to Know
Have a look at the services to know:
- Vertex AI: Unified ML ops platform
- Vertex AI Model Garden: Use foundation models
- Google Cloud Storage (for artifacts)
- Google Compute Engine (custom GPU-backed VMs)
Deployment Process
Google Cloud’s Vertex AI LLM offers a seamless way to deploy and manage large language models. For startups, Vertex AI LLM provides an intuitive platform for rapid prototyping and deployment.
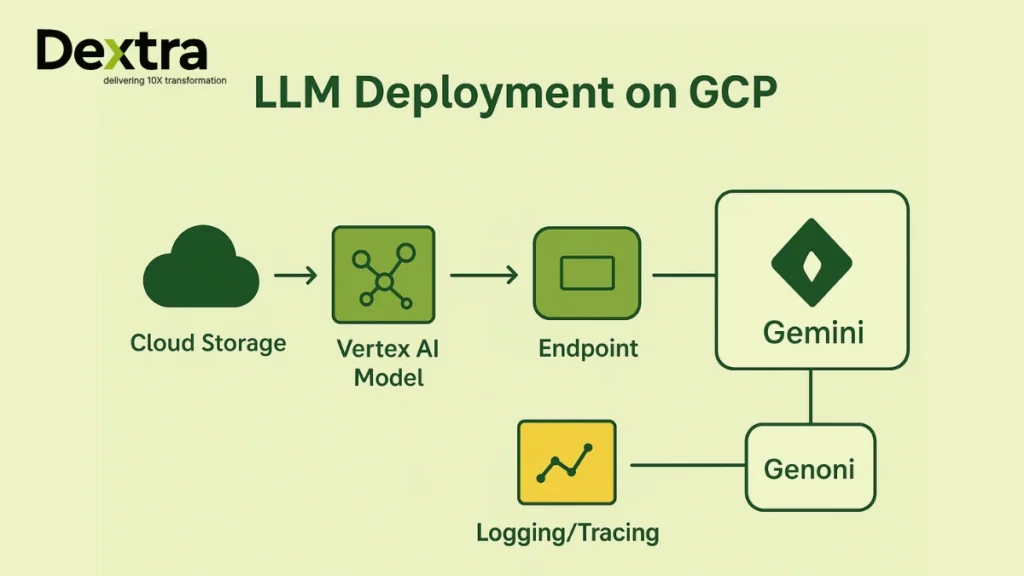
Let’s comprehend its deployment process:
- Upload model to Cloud Storage: an easy, secure storage for all your model assets.
- Create a Vertex AI model resource: ready your LLM for deployment and management.
- Deploy version for prediction: integrate with Vertex AI Endpoint for inference.
- Use Vertex AI Endpoint for inference: real-time, scalable, and reliable predictions.
- Monitor performance with Cloud Logging & Tracing: stay ahead of issues, always.
Ideal For
Google Cloud’s Vertex AI Prediction is designed to deliver production-ready LLM inference, making it ideal for real-time applications. It is ideal for:
- Teams using TensorFlow/JAX
- Teams valuing Google’s GenAI tools (e.g., Gemini integration)
Managed vs Custom Deployment: What Founders Need to Decide
Unsure whether to go ‘managed’ or get your hands dirty with custom setups? Here’s a no-nonsense table:
| Feature | Managed Services | Custom (VMs, Containers) |
| Ease of Use | ✅ High | ⚠️ Moderate to Hard |
| Cost Control | ⚠️ Limited | ✅ Full control |
| Performance | ✅ High | ✅ Highest (with tuning) |
| Time to Deploy | ✅ Fast | ⚠️ Slower |
| Flexibility | ⚠️ Moderate | ✅ High |
| Use Case | Rapid testing, MVPs | Production-grade, complex infra |
Managed is perfect for rapid starts, prototyping, and proof-of-concept. Go custom when you need to squeeze out every last drop of performance or integrate with complex infrastructure.
Cost, Performance & Scalability Considerations:
Cloud platforms like AWS, Azure, and GCP simplify the process of hosting large language models for businesses. Let’s look at their cost, performance and scalability considerations:
GPU instances vs CPU inference: Cost tradeoffs
GPU instances make LLMs fly, but they’re pricey. We’re talking 3–5x the cost versus CPUs for managed endpoints. Use them if you must, but for simple jobs, CPUs might be just fine (and cost a fraction as much).
Using spot instances (AWS, GCP) for cost savings
On AWS or GCP, spot instances can slash your bill, just watch out for sudden interruptions. Plan for resilience if you go this route.
Auto-scaling endpoints: When and how to use them
Let your app grow and shrink with user demand. Cloud-native autoscaling features mean you never pay for idle machines.
Cold start challenges in serverless LLM APIs
Serverless APIs are handy but can be slow to warm up. Persistent GPU-backed services fix this, but cost more.
Security & Compliance in Cloud-Based LLM Deployment:
Good fences make good neighbors, even in the cloud. Make sure you:
- Use strong IAM & RBAC best practices on each platform
- Protecting model weights and APIs
- Data encryption and storage policies
- Compliance standards: SOC2, HIPAA, GDPR , how the cloud platforms meet them
The big clouds take compliance seriously, but the final checklist is your responsibility.
Monitoring, Versioning & Ongoing Management
Launching your model is just the beginning. Keep it sharp and safe with:
- Tools: CloudWatch (AWS), Azure Monitor, Stackdriver (GCP)
- MLflow & custom dashboards for tracking versions
- A/B testing of model versions
- Real-time vs batch inference monitoring
- Detecting model drift in production
Did You Know? 60% of ML deployments fail due to lack of infra planning (McKinsey, 2024).
Which Platform Should You Choose? A Quick Guide for Founders
The process of deploying LLMs in the cloud involves selecting the right platform, such as AWS, Azure, or GCP, and ensuring proper resource allocation. Not sure where to start? Here’s a cheat sheet:
| Use Case | Best Cloud |
| Rapid Prototyping | GCP (Vertex AI) |
| Enterprise AI Deployment | Azure |
| Deep ML Infra Customization | AWS |
| Budget-sensitive MVP | GCP Spot Instances |
| API-based LLM Access | AWS Bedrock / Azure OpenAI |
And don’t forget, enterprise LLM deployment or custom LLM implementation is just a click away if you want expert help.
How Dextralabs Helps Startups with LLM Cloud Deployment?
The flexibility and scalability offered by LLM deployment on cloud platforms make it the go-to choice for startups and enterprises alike. However, not everyone needs (or wants) to go it alone.
Dextralabs has hands-on know-how in LLM infrastructure, across AWS, Azure, and GCP. We’re pros at everything from model hosting on cloud, LangChain cloud deployment, robust CI/CD for LLM ops, to security and compliance. Using a containerized LLM approach ensures portability and flexibility across platforms, making it easier to scale AI solutions. Want to build a production-ready LLM inference pipeline? Book a consultation and let’s talk shop!
Looking for broad support? Check out our full suite of AI Consulting services.
Conclusion: Moving Beyond Just “Hosting”
LLM deployment on cloud platforms is about more than just spinning up a virtual server. Whether you choose LLM deployment on AWS Azure GCP, the key is aligning the platform with your goals. It’s like balancing speed, control, and reliability to unlock next-gen business value. Choose the tools, and partners, that fit your needs. For example, AWS SageMaker and Google Cloud’s Vertex AI are excellent options for hosting large language models with scalability and reliability. By adhering to LLM deployment best practices, businesses can avoid common pitfalls and ensure a smooth deployment process.
As you plot your journey to smarter, scalable AI, remember: a little planning now means fewer headaches (and lower bills) tomorrow. Ready to deploy your custom LLM? Let’s build something remarkable together.