Large Language Models changed how businesses think about automation, intelligence, and decision-making. From chatbots to search systems, LLM embeddings nowadays sit at the core of many enterprise AI solutions. But while embeddings are powerful, using them “as-is” often limits real business impact.
This is where advanced feature engineering becomes critical.
While Dextralabs focuses on deploying LLMs, the real value comes from engineering task-specific features that turn raw embeddings into reliable, scalable, business-ready signals. This article discusses how advanced feature engineering bridges the gap between generic AI outputs and measurable enterprise outcomes.
From AI Consulting to Advanced LLM Feature Engineering
Organizations generally start their AI initiatives by implementing pre-trained models that generate embeddings. These vectors contain semantic meaning and remain pre-defined for business objectives such as prioritization, predication, and optimization.
Raw embeddings tell you what something means.
Feature engineering answers what to do with that meaning.
This distinction is critical for enterprise AI systems that must be accurate, informative, and cost-effective. Dextralabs assists organizations in moving beyond their basic embedding stage by developing feature-rich pipelines that allow for real-world use cases such as semantic search,predictive analytics, and agentic AI systems.
1. Semantic Similarity Features Using Concept Anchors
One of the most effective ways of using LLM embeddings is through “semantic similarity features.”
Rather than comparing every text input against all others, domain-specific concept anchors are defined to represent business-relevant concepts such as urgency, compliance risk, sales intent, and so on.
Measures of similarity between an input embedding and the anchors are then used to transform embeddings into understandable numerical features.
Why this matters for enterprises
- Converts abstract vectors into business-readable signals
- Improves the explainability to stakeholders
- Enables rule-based and ML-based decision systems
Real-World Example
In customer support systems, the automatic detection of urgent tickets is achieved by semantic similarity, where the messages closer to the anchor words, such as `high priority,’ will result in faster response.
This method makes the concept of semantic similarity a concrete feature rather than merely a vague metric.
2. Dimensionality Reduction to Remove Embedding Noise
Embeddings can have hundreds or thousands of dimensions. While this is useful for conveying meaning, it also contributes to some redundancy.
Techniques like this can reduce the dimensionality of embeddings while preserving valuable information.
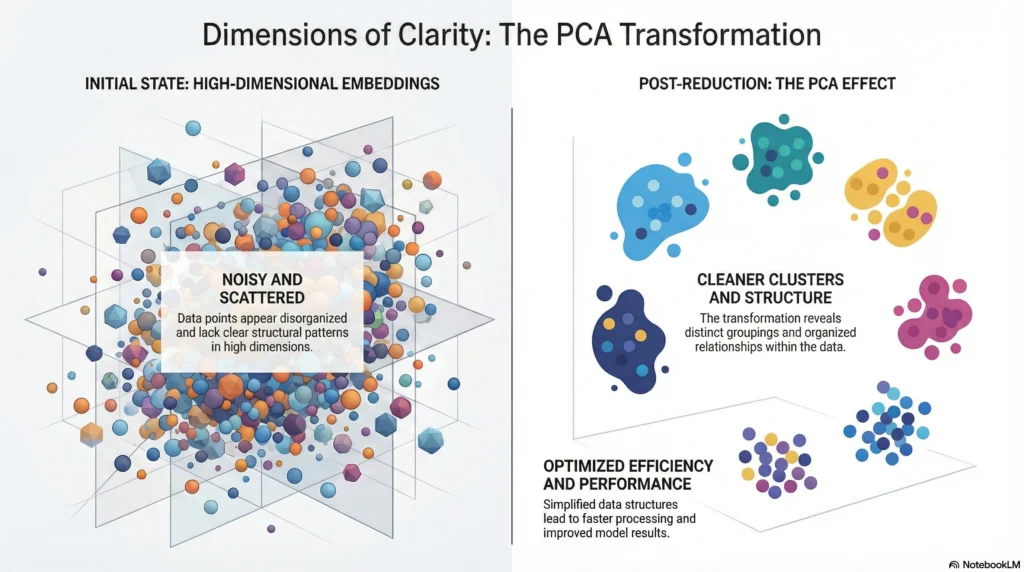
Common methods include:
- Principal Component Analysis (PCA)
- Singular Value Decomposition (SVD)
- UMAP for visualization and exploration
Business impact
- Faster model Inference
- Lower storage costs and computational costs
- Further stabilising downstream ML performance
For large-scale enterprise AI systems, reducing the embedding size directly improves efficiency without sacrificing accuracy.
3. Clustering & Distance-Based Feature Engineering
Another useful approach is to cluster the embeddings to identify an unseen pattern.
These embeddings may then form semantic clusters using techniques such as K-Means and DBSCAN.
From clustering, new features may be created:
- Cluster ID as a categorical feature
- Distance to cluster centroid as a confidence score
Why clustering matters?
- Adds structural context missing in the raw embedding
- Improves classification and recommendation systems
- Assists in identifying emerging topics or anomalies
Businesses that work with large amounts of unstructured data can benefit greatly from a clustering-based feature engineering approach.
4. Interaction Features for Text Pair Intelligence
Many enterprise use cases involve comparing two pieces of text:
- Query and record
- User question and chatbot answer
- Product description and user intent
Advanced systems engineering focuses on the interaction between embedding pairs, rather than on simple single-vector similarities.
Common methods are:
- Vector differences
- Elementwise multiplication
- Combined similarity metrics
Where this works best
- Relevance scoring in search engines
- Recommendation systems
- Ranking and matching workflows
These features of interaction capture more profound relationships, and they are more accurate when alignment is more important than meaning itself.
5. Embedding Normalization & Whitening Techniques
Similarity scores may not be accurate, especially when embedding dimensions have different variances. Here, embedding normalization and whitening are useful techniques.
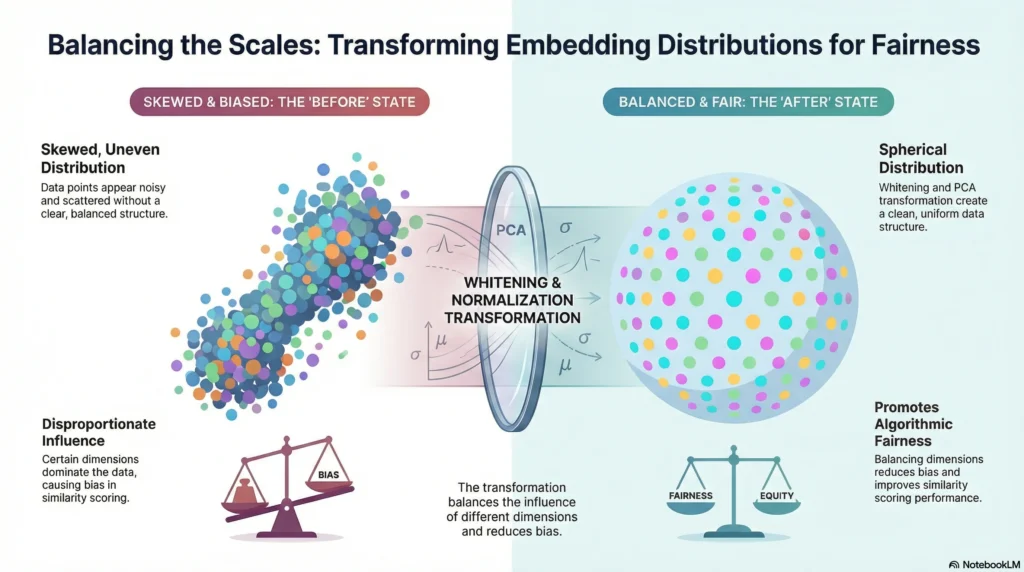
Such as:
- PCA Whitening
- ZCA Normalization
Make sure all dimensions are represented fairly in similarity calculations.
Why Enterprises Care
- More consistent cosine similarity scores
- More reduced bias in vector comparisons
- Improved trust in AI-driven decisions
For enterprise-grade LLM systems, normalization is an important step towards reliability and fairness.
6. Feature Rich Embeddings for Enterprise Use Cases
Advanced feature engineering makes sense only when applied to real-world business problems.
- Semantic Search & RAG Systems
In the retrieval-augmented generation (RAG) pipeline, the designed features improve document ranking and context selection. This will further lead to more accurate answers with a reduced level of hallucination.
- Intelligent Classification & Tagging
Semantic clusters and similarity features enable the automatic tagging of documents, emails, and support requests.
- Predictive Analytics with Embeddings
When combined with more traditional ML models, these features could enable predictions of churn risk, content relevance, and customer satisfaction scores.
- Agentic AI Systems
Feature-level context will help agents reason, retrieve, and act in agentic AI. Feature engineering provides the signals agents need to drive informed decisions across workflows.
These case studies demonstrate well how feature engineering for LLM transforms experimentation into production-ready systems.
7. Metrics, Evaluation & Tech Stack for Scalable AI
Measurement is necessary for success.
Key Evaluation Metrics
- Improvements to precision and recall
- Latency and inference speed
- Compute and cost efficiency
- Feature interpretability
Balancing performance with cost ensures sustainable AI deployment.
Common tools used
- LangChain, FAISS, Pinecone for vector workflows
- Scikit-Learn for reduction and normalization
- K-Means, HDBSCAN for clustering
- TSNE, UMAP for visualization
A well-defined stack facilitates scalability, governance, and is even essential for a strong ROI
Conclusion
Raw embeddings are just the beginning. The real business value comes from feature-engineered LLM systems that are accurate, interpretable, and efficient.
Using techniques like semantic similarity, dimensionality reduction, clustering, and embedding normalization, AI experiments are converted into practical AI solutions.
This method converts raw data into useful inputs that can actually be learned from, providing:
- Better model performance
- Faster systems
- Lower operational costs
- Specific, quantified ROI
Feature engineering is not an optimization task; it is a necessity for enterprises.
Ready to move beyond basic embeddings?
Partner with Dextralabs to design, deploy, and optimize embedding-driven enterprise AI solutions. Dextralabs, with their expertise in feature engineering for LLMs, RAG systems, and agentic workflow execution, help organizations realize AI potential.
Connect with Dextralabs today to build AI systems that scale, perform, and produce measurable results.