In 2025, enterprise AI has entered a new era. AI systems are no longer just text-driven. They are multimodal, contextual, and data-diverse, capable of understanding information from text, images, audio recordings, videos, charts, and structured datasets. This shift is reshaping how global enterprises operate, automate, and make decisions.
Traditional retrieval-augmented generation (RAG) systems relied mainly on text-based sources. But the modern enterprise environment contains far richer content. According to research by McKinsey, 70% of enterprise data is unstructured, and a significant portion of that data exists in multimodal formats such as images, PDFs, diagrams, video, and voice notes.
Organisations across the USA and UK are transitioning to multimodal RAG, integrating image and video retrieval into enterprise knowledge graphs. In the UAE and Singapore, multimodal grounding is powering innovations in healthcare diagnostics, surveillance analytics, and smart city governance. Meanwhile, rapid Enterprise AI adoption in USA drives enterprises to modernise their retrieval systems with greater accuracy and control.
Amidst this momentum, Dextralabs stands out as a trusted partner. The company helps organisations scale beyond text, designing and deploying enterprise RAG systems and multimodal RAG pipelines built for safety, precision, and observability. With expertise across AI consulting companies in USA, AI transformation consulting in UK, and AI consulting firms in Dubai, Dextralabs ensures enterprises deploy multimodal AI that is robust, trustworthy, and future-ready.
What is Multimodal RAG (Retrieval-Augmented Generation)?
Multimodal RAG extends the power of retrieval-augmented generation by allowing AI systems to search across multiple content types — text, tables, images, audio, and videos — before generating answers. Instead of relying on a single data source, the system uses a shared semantic space created through multimodal embeddings, enabling consistent meaning across different modalities.
Modern multimodal LLMs such as CLIP, Gemini, GPT-4o, Flamingo, and VILA interpret visual and auditory information alongside text. This capability gives enterprises a more complete understanding of their data.
The process begins with converting raw data into multimodal embeddings, aligning each modality into a shared space so the model can compare and retrieve relevant information. This creates more accurate and contextual enterprise insights.
As McKinsey‘s analytics research highlights, the explosion of multimodal content means enterprises can no longer rely solely on text inputs
For example:
- A retailer may need to combine product images, review text, and inventory charts.
- A manufacturer may require analysis across sensor logs, factory floor images, and QMS documents.
- A hospital may need combined insights from radiology scans and doctor notes.
This is where multimodal RAG becomes transformative, especially for data-heavy sectors such as retail, logistics, energy, healthcare, finance, and smart governance.
Also Read: Production RAG in 2025: Eval Suites and CI/CD
How Multimodal RAG Works in Enterprises?
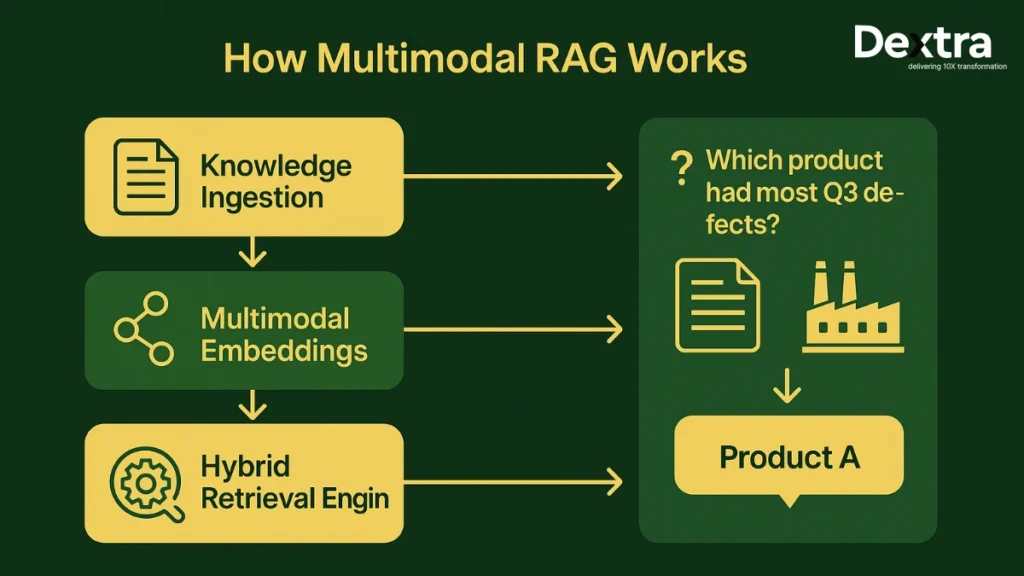
A complete multimodal RAG pipeline consists of four essential steps:
Step 1: Multimodal Knowledge Sources
Enterprise knowledge bases include:
- PDFs, SOPs, research papers
- Dashboards, charts, and diagrams
- Phone call transcripts and meeting recordings
- Security camera footage
- Product imagery and manufacturing videos
Step 2: Multimodal Embedding Generation
A multimodal encoder generates multimodal embeddings, representing text, images, or audio in a comparable mathematical format. This enables unified comparison across all content types.
Step 3: Retrieval Layer
Enterprises require hybrid retrieval that combines:
- Vector search (semantic matching)
- BM25 keyword search (exact matching)
- Reranking mechanisms
This ensures accuracy, especially in high-compliance domains.
Step 4: Augmented Generation
In this stage, the multimodal LLM synthesises all retrieved text, image, audio, or video evidence to generate a final response. It cross-verifies the retrieved context to ensure the answer is accurate, consistent, and grounded in real data. This prevents hallucinations and enables the model to deliver reliable, context-aware insights for enterprise use cases.
Also Read: Is RAG Dead? The Rise of Context Engineering and Semantic Layers for Agentic AI
The Challenge: Cross-Modal Hallucinations and Retrieval Drift
As enterprises expand their multimodal AI infrastructure, one challenge stands out above all: cross-modal hallucinations. These occur when AI incorrectly links information across modalities — such as connecting the wrong image to a text description, misinterpreting audio context, or pulling unrelated video snippets into the retrieval window. Retrieval drift further complicates this issue, causing precision to drop as the index grows and embeddings lose alignment over time.
As Dextralabs often emphasises to global enterprises, AI hallucination prevention isn’t optional — it’s the foundation of enterprise-grade AI reliability. This principle guides how enterprise RAG systems must evolve in 2025 and beyond, especially when dealing with multimodal data sources.
The root causes of hallucinations include:
- Misaligned multimodal embeddings
- Incomplete dataset structuring
- Semantic noise or irrelevant retrievals
- Overly broad fine-tuning
- Weak evaluation cycles
- Lack of retrieval observability
With multimodal LLMs now powering high-stakes use cases in healthcare, finance, retail, logistics, and government, addressing this challenge is essential for safe and explainable enterprise AI.
[Top Causes of Cross-Modal Hallucinations in Enterprise AI]
What are the Main Causes of Hallucinations in Multimodal RAG?
Hallucinations in multimodal RAG occur when AI systems generate incorrect, mismatched, or fabricated insights across text, images, audio, or video. These problems emerge when models fail to maintain consistent semantic grounding across different modalities. One major contributor is data alignment issues, where multimodal embeddings drift apart, leading the system to misinterpret relationships between textual, visual, and auditory signals. Another common cause is information bottlenecks, created when complex visuals, charts, or videos are compressed into short captions or simplified summaries. This loss of essential context forces the model to fill in gaps, increasing the likelihood of hallucinations.
Noisy or irrelevant retrievals also play a significant role. Overly broad or weak vector matches can contaminate the context window and introduce misleading information. In addition, latency and scalability limitations affect accuracy, as processing heavy media formats increases computational strain and lowers retrieval precision under high load. Many enterprises also struggle with weak governance metrics, lacking standard measures to evaluate grounding accuracy, multimodal drift, and retrieval consistency.
According to Forbes Technology Council (2024), companies adopting multimodal AI pipelines achieve more accurate predictions than those relying solely on text-based systems—highlighting the value of well-aligned, high-quality multimodal infrastructure.
Key Causes of Multimodal Hallucinations
- Data Alignment Issues – Misalignment between text, image, and audio embeddings
- Information Bottlenecks – Missing context when complex media is overly compressed
- Noisy Retrievals – Irrelevant or shallow vector matches entering the pipeline
- Latency & Scalability Limits – Reduced retrieval accuracy under media-heavy workloads
- Weak Governance Metrics – No standard measurement of grounding or cross-modal drift
How to Prevent Cross-Modal Hallucinations — Dextralabs’ Framework?
Dextralabs applies a multilayer AI hallucination prevention and governance strategy.
Layer 1: Data Quality & Multimodal Processing
Dextralabs ensures:
- OCR quality scoring
- Audio-text synchronization
- Vision-text structural mapping
- Hierarchical chunking
- Noise reduction and metadata cleanup
This ensures cross-modal alignment and reduces drift.
Layer 2: Retrieval & Generation Mechanisms
Dextralabs implements:
- Hybrid retrieval (vector + keyword)
- Strong grounding verification
- Reranking pipelines
- Query decomposition for complex tasks
Models must cite:
- Document IDs
- Image URIs
- Source excerpts
This strengthens AI hallucination prevention.
Layer 3: Architecture & Governance
Dextralabs uses:
- Microservice-based RAG architecture
- Real-time hallucination monitoring
- Human-in-loop validation
How to Scale Multimodal RAG in the Enterprise?

Scaling multimodal RAG across large regions like the USA, UK, UAE, India, and Singapore requires. Dextralabs also supports AI strategy for startups in India, helping early-stage companies adopt multimodal RAG with strong governance and compliance.
- Distributed vector databases (FAISS, Pinecone, Milvus)
- Caching and sharding
- Horizontal scaling
- Low-latency cloud deployment
- Enterprise-wide AI observability dashboards
- Drift detection and lineage tracing
This approach strengthens enterprise AI scalability, ensuring multimodal RAG systems remain reliable even as data volume and media complexity increase. Dextralabs provides a comprehensive observability and governance framework that tracks:
- Retrieval drift
- Grounding precision
- Latency distribution
- Hallucination rate
Evaluation and Governance Metrics:
To ensure that multimodal RAG operates safely at enterprise scale, Dextralabs recommends a structured evaluation and governance framework grounded in four measurable metrics. These metrics are designed to provide visibility into alignment quality, grounding accuracy, retrieval performance, and human oversight effectiveness. Together, they form the backbone of responsible AI governance — especially important in regulated industries.
1. Cross-Modal Consistency Score (CMCS)
The Cross-Modal Consistency Score evaluates how well different modalities (text, images, audio, video) align with each other for a given query.
A high CMCS indicates that:
- The image accurately corresponds to the associated text segment
- Audio or video snippets support the retrieved written information
- Multimodal embeddings remain semantically synchronised
This metric is essential because multimodal LLMs often build meaning by comparing relationships across modalities. Any misalignment can lead to cross-modal hallucinations or misleading interpretations.
2. Grounding Precision
Grounding Precision measures how accurately the model’s final output is rooted in retrieved evidence.
It answers questions like:
- Did the system use the correct document chunk?
- Did it reference the right image or chart?
- Did it synthesise insights only from validated context?
High grounding precision is crucial for reducing hallucinations and ensuring factual reliability. It also reinforces evidence-based responses, which are required in fields like healthcare, finance, audit, and legal compliance.
3. Retrieval Recall Rate (RRR)
The Retrieval Recall Rate determines how much of the relevant information the system successfully retrieves out of all possible relevant data.
It evaluates:
- Whether the RAG pipeline captured enough evidence
- How diverse the retrieved multimodal content is
- Whether critical visual or textual components were missed
A low RRR often leads to incomplete or biased outputs. In enterprise RAG systems, this metric is significant for large document repositories, video archives, and multi-shard vector indexes.
4. Human Validation Accuracy (HVA)
The Human Validation Accuracy metric measures agreement between human experts and the model’s generated response.
It shows:
- How interpretable the system’s outputs are
- How well-grounded the model’s explanations appear
- Whether human reviewers identify inconsistencies
HVA is foundational for AI governance, especially in sensitive use cases such as medical diagnostics, financial advisory, policy analytics, and legal reasoning. High HVA reduces organisational risk and aligns with best practices followed in AI governance consulting in Singapore and global regulatory bodies.
Real-World Use Cases of Multimodal RAG :
Multimodal RAG applies across industries where information exists in multiple formats. Dextralabs helps enterprises integrate text, images, video, charts, and sensor data into unified, explainable AI workflows. Here are some in-depth use cases:
1. Healthcare
Modern hospitals generate massive multimodal datasets — radiology scans, pathology images, discharge summaries, EHR notes, ultrasounds, and lab reports.
A multimodal RAG system can:
- Match radiology images with doctor notes for accuracy
- Retrieve related case histories
- Compare patient scans to past clinical outcomes
- Cross-reference symptoms with lab analytics
This reduces diagnostic delays and increases interpretability in clinical decision support.
2. Manufacturing & Industry 4.0
Factories generate complex datasets across machines and assembly lines:
- Production line video feeds
- Thermal imaging
- Sensor telemetry
- Maintenance logs
- SOP documents
A multimodal RAG system can:
- Detect defects by comparing logs with video snapshots
- Analyse equipment downtime using sensor visuals
- Fetch historical QC reports
- Highlight anomalies by overlaying sensor readings on images
This enables predictive maintenance, safer operations, and faster root-cause analysis.
3. Retail & E-commerce
Retailers manage large catalogues involving:
- Product photos
- Customer reviews
- Price charts
- Inventory tables
- Social media videos
Multimodal RAG can:
- Align customer reviews with product images
- Automate catalogue enrichment
- Identify visual or textual patterns in product defects
- Enhance search with multimodal queries (“show me the red version of this bag with leather straps”)
This results in smarter recommendations and streamlined product operations.
4. Legal & Compliance
Legal teams deal with enormous archives of:
- Contracts
- Case files
- Court transcripts
- Evidence photos
- Scanned documents
Multimodal RAG helps by:
- Matching evidence images with case transcripts
- Extracting relevant sections from lengthy legal PDFs
- Analysing handwriting or signature patterns
- Supporting e-discovery workflows
This improves accuracy and operational efficiency in legal research.
5. Finance & Banking
Financial institutions work with multimodal datasets such as:
- Market charts
- Earnings reports
- Regulatory filings
- Customer communications
- Credit documents
A multimodal RAG system can:
- Correlate charts with report summaries
- Analyse risk indicators visually and textually
- Generate grounded investment briefs
- Support audit workflows by pairing documents with historical benchmarks
Dextralabs’ Beyond-RAG™ deployments enable financial firms to produce safe, transparent, and explainable intelligence outputs.
Dextralabs’ Multimodal AI Framework
Dextralabs’ Beyond-RAG™ Multimodal Framework provides a powerful architectural foundation for enterprises looking to deploy safe, scalable, and governance-ready multimodal AI systems. It integrates text, images, audio, video, charts, and structured datasets into a unified intelligence layer, enabling seamless cross-modal understanding and highly reliable enterprise outputs. Designed for high-compliance sectors across London, Dubai, India, Southeast Asia, USA, and Singapore, the framework strengthens precision retrieval, enhances cross-modal alignment, supports real-time observability, and ensures long-term AI governance.

Key Components of the Beyond-RAG™ Framework:
- Unified Multimodal Data Layer: Ingests, organises, and structures all modalities with metadata tagging and hierarchical chunking.
- Contextual Retrieval Engine: Combines vector search and BM25 keyword search for fast, accurate multimodal retrieval.
- Multimodal Embedding Synchronisation: Aligns text, visual, audio, and video embeddings to reduce drift.
- Observability Dashboards: Monitor grounding accuracy, hallucination rate, and retrieval drift.
- Compliance-Focused Governance Architecture: Enforces audit logs, access controls, and regulatory safeguards for responsible enterprise AI use.
Conclusion
Multimodal RAG is shaping the future of enterprise AI, enabling organisations to extract deeper insights from text, images, audio, and video in a unified, intelligent workflow. As adoption accelerates across industries, precision retrieval, strong observability, and governance-first design are essential for ensuring reliability and trust. These capabilities play a crucial role in effective AI hallucination prevention, especially as enterprises expand multimodal use cases.
Dextralabs helps enterprises build multimodal RAG systems that remain grounded, compliant, and scalable, reducing hallucinations while improving decision quality. By integrating cross-modal alignment, robust retrieval pipelines, and continuous monitoring, Dextralabs empowers organisations to unlock the full value of their unstructured, multimodal data and deploy AI solutions with confidence and long-term resilience.


![What is an OpenAI API Key and How to Use It in 2025 [With Examples]](https://dextralabs.com/wp-content/uploads/2025/06/openai-api-keys.webp)



