| For CTOs, CIOs and Enterprise Architects the core challenge of enterprise AI integration isn’t the AI, it’s the 20-year-old infrastructure underneath it. This article covers how OpenClaw’s agentic model bridges legacy systems like SAP, Salesforce, Oracle and internal platforms without requiring you to modernize them first. We cover integration architecture, security frameworks, orchestration patterns and where this model breaks down, because it does break down and you should know where before you commit. |
The Problem Isn’t the AI. It’s Everything Underneath It.
Every enterprise CTO we talk to has the same story. The AI pilots worked. The demos impressed the board. The vendor presentations showed clean integrations, smooth data flows, happy agents humming through workflows that used to take your team three days.
Then the pilot hit the actual infrastructure.
Suddenly there’s a SAP instance from 2009 that has no public API and seventeen custom ABAP modules nobody fully understands anymore. There’s an Oracle ERP that the vendor technically supports but practically speaking is frozen in place because any schema change requires a six-month approval cycle. There’s a CRM that was built in-house in 2014, runs on a server in the basement and is the single source of truth for your entire sales operation — and nobody has touched the codebase since the engineer who wrote it left the company.
Digital transformation doesn’t fail because AI isn’t good enough. It fails because the infrastructure underneath it wasn’t designed to evolve at the speed modern AI demands.
APIs that don’t exist. Vendor lock-in that prevents modification. Monolithic systems with undocumented dependencies. Rigid schemas that break if you breathe on them wrong. Modernization roadmaps measured in years, not quarters.
This is the enterprise reality that AI vendors tend to gloss over in their sales decks. And it’s exactly the problem that agentic integration — done properly — is positioned to solve.
Not by replacing your legacy systems. By making them participate in AI workflows without being touched.
Also Read: Top 5 Secure and Lightweight Alternatives to OpenClaw
The Systems You’re Actually Dealing With
Before we get into architecture, it’s worth naming the specific systems that show up in almost every enterprise integration engagement we run at Dextralabs. Because “legacy systems” is an abstraction. The reality is a lot more specific and a lot more painful.
Here’s what the enterprise stack actually looks like:
- Salesforce — heavily customized, often with thousands of custom fields, process builder automations and Apex code that nobody wants to touch. APIs exist, but they’re rate-limited, schema-heavy and require OAuth flows your security team has opinions about.
- SAP ERP / SAP BI — the system that runs your actual operations and was never designed to be queried by anything other than SAP’s own tools. BAPI interfaces, RFC calls, IDoc formats. Not hostile to integration, but not friendly either.
- Oracle ERP / Databases — mission-critical, change-averse and sitting behind a firewall that your network team guards with religious devotion. PL/SQL stored procedures, tablespace configurations and a DBA who will not look kindly on your new AI agent reading production tables.
- Jira and internal project tooling — usually has APIs, but they’re used inconsistently, the data model is project-specific and extracting meaningful workflow state requires understanding six months of undocumented configuration.
- Internal CRMs and admin portals — the scariest category. Built in-house. No documentation. No API. Just a web interface that works, has always worked and will keep working until the day it doesn’t.
- On-premises databases and terminal systems — IBM AS/400 systems, mainframe terminals, databases that predate REST APIs by a decade. The data is there. Getting to it cleanly is another matter entirely.
The common thread: almost none of these systems were designed for AI-native integration. They were designed to be operated by humans through interfaces built for humans. Which, as it turns out, is exactly where the agentic model has an advantage.
A Different Way to Think About Integration Architecture
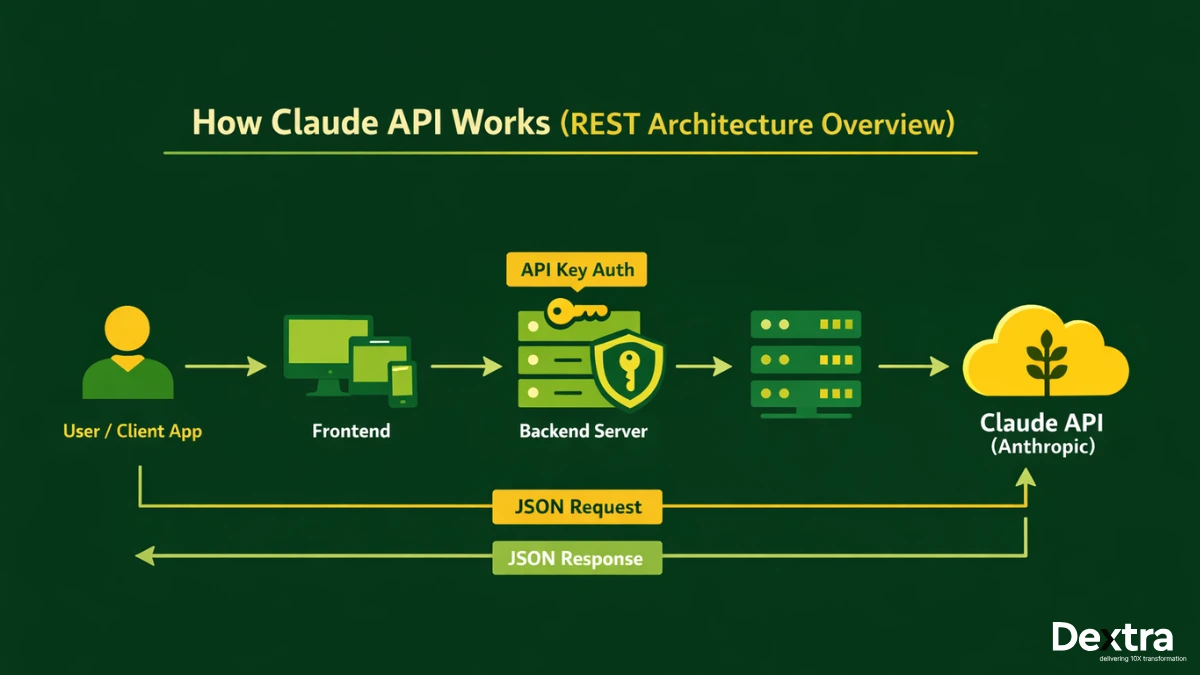
Traditional enterprise integration assumes you’re connecting systems through their data layers. You hit an API, transform the payload, route it somewhere, write it to a database. The integration layer is a plumbing layer.
The agentic model flips this assumption.
OpenClaw doesn’t connect to your systems through their data layer. It connects through their behavioral layer — the same layer a human operator uses.
That’s a more radical shift than it sounds. Let’s look at both models side by side.
The Traditional Integration Model
Legacy System
↓
API / Data Layer
↓
Middleware / ETL
↓
Integration Platform
↓
AI / Application LayerThis model works when systems have clean APIs, stable schemas and cooperative vendors. In many enterprise environments, that’s a fantasy. You spend months building and maintaining the plumbing before AI can touch any of it.
The Agentic Integration Model
Legacy System Interface (web UI, terminal, portal, report)
↓
OpenClaw Agent Layer (perceives, decides, acts)
↓
AI Orchestration Layer (reasoning, memory, tool invocation)
↓
Workflow Execution Layer (task scheduling, state management)
↓
Enterprise Process Layer (business outcomes, audit, reporting)The agent doesn’t need a clean API. It needs an interface — any interface a human can use. A web form. A report screen. A search field. A button that triggers a workflow. The agent operates at the same layer a trained employee would operate, which means the integration point is the user interface rather than the data schema.
This is the architectural insight that changes the enterprise integration conversation: if a human can do it through a screen, an agent can do it through that same screen. And unlike an API integration, it requires no changes to the underlying system whatsoever.
Also Read: Moltbook: Best Social Network for AI Agents in 2026
What are the Integration Strategies (and When to Use Each)?
Not every system calls for the same approach. Here’s how we think about matching integration strategy to system characteristics at Dextralabs.
Strategy A: Browser-Based Automation — The No-API Integration Model
This is the one that raises eyebrows in architecture reviews until people realize it actually works.
When a system has no API, a closed vendor platform, or a schema so fragile that touching it requires a change request and a prayer — OpenClaw’s browser control capability becomes the integration path. The agent opens a browser, navigates to the system’s web interface, reads what’s on the screen, interacts with forms and buttons and completes the task.
It sounds inelegant. In practice, it’s often the fastest path to getting a legacy system into an AI workflow and in many cases it’s the only path that doesn’t require vendor approval, schema migration, or a multi-month development cycle.
| What this unlocks in practice → Your internal admin portal built in 2013 can feed data into an AI workflow without anyone touching the codebase. → A vendor-locked SaaS platform your procurement team has used for a decade can be automated without API access. → A terminal-based ERP system can be read and written by an agent operating through its web interface. → All of this without a single line of middleware, a single API contract, or a single schema change. |
The caveats are real. Browser-based automation is more fragile than API-based integration — UI changes can break workflows and maintaining scripts requires ongoing attention. It’s also slower. But for systems where the alternative is “modernize first,” it’s often the bridge that makes everything else possible.
Strategy B: Skill-Based Extensibility — Building a Governed Capability Layer
This is where OpenClaw transitions from an integration tool into an enterprise platform.
Think of skills as controlled capability units. Each skill is a containerized, task-specific execution module that gives the agent a defined capability — “read from the Salesforce opportunity record,” “submit a PO in SAP,” “extract the week’s closed tickets from Jira.” The agent doesn’t get broad access to these systems. It gets precise, auditable access through approved skill modules.
The enterprise governance model this enables is significant:
- Internal skill marketplace — your platform team maintains a registry of approved skills that agents are permitted to use, rather than giving agents open-ended system access
- Private skill registries — skills are built internally, reviewed internally and never pulled from public repositories without going through your standard software supply chain controls
- Code signing and versioning — every skill deployed to production is signed, versioned and can be rolled back in exactly the same way you’d roll back any other production software
- Controlled deployment pipelines — skills go through the same CI/CD processes, security scans and approval workflows as your other enterprise software. No exception for AI.
OpenClaw Core Agent
↓
Skill Registry (internal, approved, versioned)
↓
Execution Sandbox (containerized, least-privilege)
↓
Enterprise Systems (Salesforce / SAP / Oracle / Internal)This architecture transforms OpenClaw from a flexible automation tool into something that looks and behaves like a regulated enterprise platform. Which is what your compliance team actually needs it to be.
Strategy C: Local-First Processing — For Data That Cannot Leave the Building
Some data simply cannot be processed outside your perimeter. Not because your security team is being difficult, but because the law says so, or because your contracts say so, or because the consequences of a breach are severe enough that the risk calculus doesn’t support external processing under any circumstances.
Healthcare patient records. Financial trading data. Government classified systems. Legal privileged communications. Defence infrastructure. Enterprise IP in industries where competitive intelligence is existential.
The local-first model means OpenClaw and the AI models it invokes run entirely within your infrastructure. On-premises servers or private cloud environments. Internal network isolation. Zero data leaving your perimeter. The agent processes, reasons and acts entirely within a boundary you control.
| What this makes possible → A hospital system running patient data analysis with AI agents entirely on-prem, with zero external API calls to any third-party AI service. → A financial institution running trading workflow automation where the model and the data both stay inside the regulated perimeter. → A government agency using agentic AI for internal document processing without any data crossing the air gap. → A law firm using AI agents for discovery and research with full control over every data access point. |
The tradeoff is capability. On-premises models are typically less capable than frontier cloud models. You’re accepting a capability ceiling in exchange for a sovereignty floor. For the use cases listed above, that’s usually the right tradeoff. For general enterprise automation, it may not be.
Strategy D: Gateway Integration — Building the Human-AI Interaction Fabric
This one is underappreciated and, in our experience, dramatically underestimated in terms of enterprise impact.
Your organization already has communication infrastructure: Slack, Microsoft Teams, internal portals, WebSocket-based dashboards. People are in these channels all day. Decisions happen there. Escalations happen there. Status updates happen there.
The gateway integration model puts OpenClaw at the intersection of your communication infrastructure and your enterprise systems. Employees interact with the agent through the channels they’re already in. The agent reaches into the systems they need to touch.
Employee → Slack / Teams / Internal Portal
↓
Agent Gateway Layer (authentication, routing, context)
↓
OpenClaw AI Agent (reasoning, tool invocation, memory)
↓
Enterprise Systems (Salesforce / SAP / Jira / Internal)The practical result: a sales rep types “update the Acme opportunity to Closed Won and notify the CSM” in Slack. The agent updates Salesforce, finds the CSM in the org directory and sends the handoff message — all without the sales rep touching a CRM. An operations manager asks for the week’s open POs in Teams. The agent queries SAP, formats the response and replies in the thread.
This isn’t science fiction. It’s a deployment pattern we run for enterprise clients today. The challenge is in the gateway architecture — authentication, authorization, context management — and in ensuring the agent has the right permissions for the right systems for the right person who asked the question.
What are the Microservices and API Orchestration Patterns?
Once you move beyond individual system integrations, you hit a more interesting architectural challenge: how does the agent coordinate across multiple systems simultaneously? How does it manage state across a multi-step workflow? How do you prevent it from becoming a single point of failure in a process that spans six different systems?
Three patterns address this in practice.
Pattern 1: Agent-as-Orchestrator
The agent doesn’t execute the work. It coordinates the things that do.
In this pattern, OpenClaw acts as a workflow conductor. It receives a high-level instruction — “process the end-of-month close” — and then coordinates the microservices, APIs, data pipelines and task queues that actually do the computation. The agent decides what to invoke, in what order, with what parameters and what to do when something fails.
The advantage of this separation is that the coordination logic lives in the agent, but the execution logic lives in your existing infrastructure. If a microservice changes behavior, you update the microservice. You don’t need to rewrite the agent’s coordination logic.
Pattern 2: Hybrid Integration Fabric
Most enterprises end up here eventually, because most enterprises have both modern systems and legacy systems — often running side by side.
| The Hybrid Model Modern systems (Salesforce, Jira, cloud APIs) → Direct API integration where clean contracts exist Legacy systems (SAP, Oracle, on-prem databases) → Agent automation where no clean API is available Result: One coherent AI-driven workflow spans both worlds. The agent uses APIs where they exist and browser/skill automation where they don’t. From the user’s perspective, it all looks the same. |
This dual fabric approach means you don’t have to choose between “modernize everything before we can use AI” and “build brittle screen-scraping workarounds forever.” You build appropriate integration for each system type and let the agent layer unify them.
Pattern 3: AI as the Control Plane
This is the mature end-state of enterprise agentic integration and it’s worth naming clearly because it changes how you think about enterprise architecture.
In the traditional model, workflow logic lives in your workflow engine, business rules live in your BPM platform and AI lives in a separate layer that gets consulted occasionally.
In the AI control plane model, OpenClaw is the workflow engine. It holds the decision logic, the routing logic, the task assignment logic and the exception handling logic. Your existing systems become execution targets that the AI coordinates, rather than independent systems that coordinate with each other.
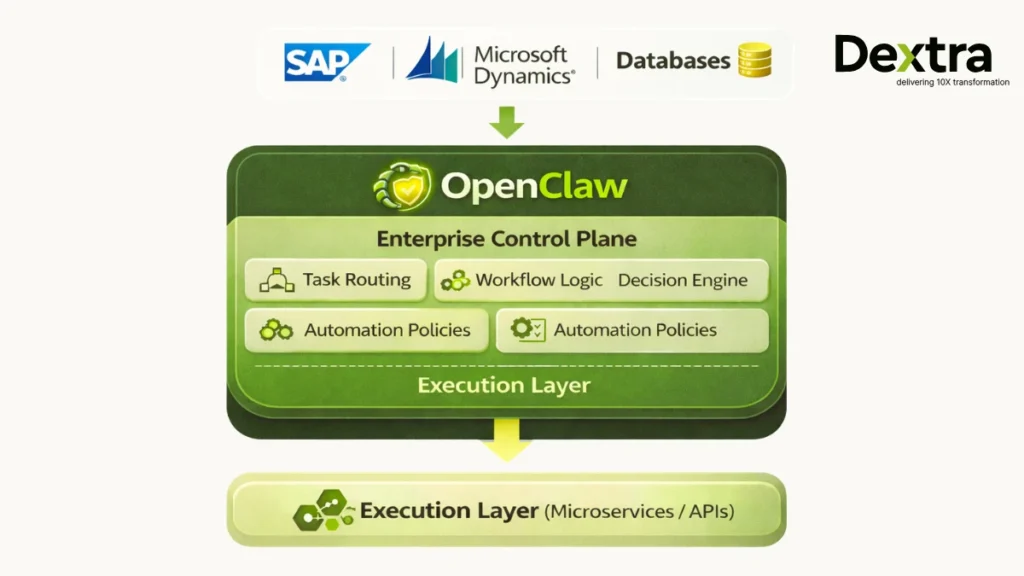
This is a significant architectural commitment. It means your AI layer is no longer advisory — it’s operational. Which brings us to the part of this conversation that doesn’t get enough airtime.
Enterprise Security and Governance: The Part That Actually Determines Success
We’ve seen more enterprise AI integrations fail in governance reviews than in technical implementation. Not because the technology didn’t work, but because the security team looked at what the agent could do and said no.
That’s not a security team problem. That’s an architecture problem. The goal is to design an agent system that passes the security review before the security review happens — because you built the controls in from the start, not bolted them on at the end.
The Sandboxed Deployment Model
The core principle: agents never touch production systems directly.
Every agent runs in an isolated execution environment — a dedicated VM, a container, a service account with explicit permissions. Network segmentation ensures the agent can only reach the systems it’s been explicitly authorized to reach. No lateral movement. No ambient access. The agent’s operational boundary is defined by infrastructure, not by policy alone.
This matters because policy-based controls assume the agent behaves as designed. Infrastructure-based controls hold even if the agent behaves unexpectedly — because the network layer and the permission layer don’t care what the agent thinks it should be allowed to do.
Least Privilege, Applied Rigorously
“Least privilege” is a principle most enterprise security teams can recite in their sleep. Applying it to AI agents requires thinking through a few specifics that don’t come up in traditional software security:
- File-level access controls — the agent gets read access to the specific files it needs, not to the directory. Not to the filesystem.
- Database access segmentation — the agent’s service account has SELECT on specific tables, not on the schema. Certainly not DML privileges on anything production-critical.
- API scope limitation — OAuth scopes are declared explicitly and reviewed. The agent doesn’t get a token that can do everything the API allows.
- Function-level permissions — in skill-based deployments, each skill declares exactly what permissions it requires. The agent cannot invoke permissions it hasn’t declared.
Skill Whitelisting and Supply Chain Controls
This is the governance area that most organizations underestimate and it’s where the most serious enterprise AI security incidents have occurred.
OpenClaw’s skill ecosystem is powerful precisely because it’s extensible. Community-built skills can add capabilities quickly. But a skill that appears to integrate your project management tool might also be logging your API credentials or exfiltrating files through a side channel. This is not theoretical — it has happened.
The enterprise rule: treat skills like production software. Code review gates. Static analysis. Vulnerability scanning. Internal approval workflows. Version control. Signed deployments. If you wouldn’t deploy an unreviewed NPM package to production, you shouldn’t deploy an unreviewed skill to your AI agent.
At Dextralabs, we implement a zero-trust skill model — nothing is permitted until it has been reviewed, approved and signed by an authorized owner. The skill registry is internal. No public skills are ever pulled without going through the internal approval pipeline first.
Audit, Monitoring and Forensic Readiness
When — not if — something goes wrong, you need to be able to answer specific questions: what did the agent do, in what order, at what time, accessing what data and producing what output? That answer needs to exist before the question is asked, not be reconstructed after an incident.
Full action logs. Execution traces. Data access logs. Behavioral monitoring that can identify anomalies — an agent accessing systems it normally doesn’t touch, running at times it normally doesn’t run, consuming data at volumes it normally doesn’t consume.Compliance reporting should be a feature of the monitoring layer, not a separate effort. If your GDPR DPA or SOC 2 audit requires demonstrating control over AI agent data access, that report should be a query, not a project.
Where This Model Breaks Down (Because It Does)?
We’d be doing you a disservice if we presented agentic enterprise integration as a clean solution to every legacy problem. It isn’t. There are specific failure modes that matter and you should know what they are before you commit resources to this approach.
Autonomous Behavior in High-Stakes Workflows
The same autonomy that makes an AI agent useful in routine workflows makes it dangerous in high-stakes ones. An agent coordinating a financial reconciliation process that encounters an unexpected state has two options: ask a human, or make a decision. If it’s designed to minimize interruptions, it will make a decision. Sometimes that decision will be wrong in a way that’s expensive to unwind.
Human-in-the-loop checkpoints are not optional for workflows where the consequence of an incorrect autonomous decision is significant. This is an architectural requirement, not a user experience preference.
Plugin and Skill Supply Chain Risk
We mentioned this in the security section, but it deserves emphasis here: the skill ecosystem is the most significant risk surface in an enterprise OpenClaw deployment. Community skills are not vetted to enterprise standards. Credential leakage through malicious skills is a real threat. Shadow deployments — where a team installs skills that haven’t been approved — are how governance breaks down in practice.
This is a governance problem more than a technical problem. But governance problems have technical solutions: locked skill registries, deployment pipeline controls and monitoring that alerts when an unauthorized skill is invoked.
The Agentic AI Governance Gap
The most important thing we tell enterprise clients: agentic AI must be governed like production software, not like a productivity tool.
Most organizations have well-established processes for deploying production software. Change management. Security review. Rollback procedures. Incident response. These processes exist because production software can affect real business outcomes when it fails.
AI agents affect real business outcomes when they fail. They need the same governance structures. The fact that they look like helpful tools rather than deployment artifacts doesn’t change that calculus. Shadow AI deployments — teams spinning up agents outside the approved pipeline because it’s faster, are the equivalent of shadow IT, with all the same risks and a few new ones.
How Dextralabs Approaches Enterprise AI Integration?
The framing we use internally is simple: we don’t deploy tools. We deploy AI systems.
The distinction matters. A tool is something you configure and hand off. A system is something with defined architecture, security controls, operational procedures, monitoring infrastructure and a governance framework. The difference between an AI pilot that worked and an AI deployment that scales is almost always the difference between those two things.
Here’s how that translates to what we actually do with enterprise clients.
Architecture Design — Before Anything Else
Every engagement starts with architecture, not with deployment. We map the target systems, identify the integration strategy for each (API, browser automation, local-first, gateway), design the skill governance model and define the security perimeter before a line of code is written.
This phase typically surfaces the constraints that pilots ignore: the compliance requirement that prevents cloud processing, the database access policy that limits what the agent can read, the vendor contract that prohibits automation against a specific API. Better to find these in the design phase than after you’ve built the integration.
Secure Deployment Infrastructure
Zero-trust AI infrastructure means every agent runs with the minimum necessary permissions, in an isolated environment, with network access limited to explicitly authorized destinations. We implement this for on-premises deployments, private cloud environments and hybrid configurations where different systems have different sovereignty requirements.
For regulated sectors — healthcare, financial services, government, legal — we design specifically for compliance requirements first and build the AI capabilities within those constraints. Not the other way around.
Legacy System Bridging
This is the work most AI vendors don’t want to do because it’s slow, specific and unglamorous. Mapping the actual interface of a 2009 SAP instance. Understanding the ABAP function modules that expose the data you need. Building browser automation that survives UI updates. Writing and reviewing skills that connect to internal APIs documented only in tribal knowledge.
We do this work because without it, the AI layer is impressive in a demo and useless in production.
Governance and Compliance Mapping
Agent policy frameworks. Skill governance. Access control models. Compliance mapping against SOC 2, ISO 27001, GDPR, HIPAA, or whatever regulatory framework your industry requires. Audit log architecture that produces the reports your compliance reviewers will actually accept.
And ongoing monitoring — because a system that was compliant when it launched needs to stay compliant as it evolves. Agent behavior drifts. Permissions accumulate. Skills get added. Without monitoring, governance is a snapshot rather than a guarantee.
Productionization: The Gap Between Pilot and Scale
The hardest phase is almost never the prototype. It’s the journey from “this worked in the pilot” to “this runs reliably in production at scale.”
Error handling for the edge cases the pilot never encountered. Load testing that simulates actual enterprise usage rather than demo conditions. Operational runbooks for the on-call team that didn’t build the system. Rollback procedures for when an agent deployment introduces a regression. Incident response plans for when an agent takes an action it shouldn’t.
We’ve productionized enough enterprise AI systems to know exactly what breaks between pilot and scale and to build for it before it happens.
The Future Enterprise Stack Won’t Replace Everything. It Will Bridge Everything.
There’s a version of the enterprise AI conversation that goes: legacy systems are the problem, therefore we need to replace them. Rip and replace. Modernize the whole stack. Start fresh.
This version is wrong and most CIOs who’ve been in the industry long enough know it’s wrong. You don’t replace a SAP instance that took seven years and hundreds of millions of dollars to customize to your specific operational model. You don’t replace the CRM that your entire sales operation has built its muscle memory around. You don’t replace the database that is the single source of truth for your financial reporting because someone read a Gartner report about modernization.
What you do — what the organizations that are actually making progress on enterprise AI are doing — is build an intelligent layer on top of what exists. Not connecting systems through their data APIs, but connecting them through an agent layer that operates the way a skilled employee would operate: reading the interface, understanding the context, taking the action, reporting the outcome.
OpenClaw’s role in this architecture isn’t to modernize your legacy systems. It’s to make them participants in modern AI workflows without requiring them to change. That’s a meaningfully different value proposition — and in many enterprise contexts, it’s the only one that’s actually achievable in a reasonable timeframe.
The bridge is agentic AI architecture. The question isn’t whether to build it. It’s whether you build it with controls, governance and architecture that will hold at production scale — or whether you build it fast and deal with the consequences later.
At Dextralabs, we’ve seen both. The second approach is never actually faster.
If your organization is exploring AI integration with legacy systems, As an Ai Consulting Firm, Dextralabs helps enterprises design secure, scalable, and production-grade OpenClaw deployments across: USA, UK, Singapore, India, UAE. From architecture to deployment to governance to enterprise-scale execution. Not tools. Not demos. Not experiments.
Frequently Asked Questions (FAQs):
Q. How does OpenClaw integrate with legacy enterprise systems that have no API?
A: Through browser-based automation — OpenClaw’s agent controls a web browser, navigates to the system’s interface, and interacts with it the same way a human operator would. This means no API, no schema migration, and no vendor approval required. The tradeoff is that browser automation is more fragile than API-based integration and requires maintenance when the UI changes. For systems where “modernize first” isn’t an option, it’s often the most practical path to integration.
Q. Can OpenClaw integrate with SAP, Salesforce and Oracle enterprise systems?
Yes, but the integration approach differs by system. Salesforce has documented APIs and OAuth flows, making API-based integration the cleaner path. SAP integration typically requires a combination of BAPI/RFC interfaces and browser automation for workflows that don’t expose clean API contracts. Oracle integrations are highly environment-specific — the approach depends on how your Oracle instance is configured, what network access is available, and what your DBA team will permit. At Dextralabs, we assess each target system individually before recommending an integration strategy.
Q. What security controls should enterprises put around an OpenClaw deployment?
Four controls are non-negotiable: sandboxed execution environments (isolated VMs or containers with network segmentation), least-privilege service accounts with explicitly declared permissions, a skill whitelisting framework that treats every skill as production software subject to code review and signing, and a comprehensive audit and monitoring layer that produces compliance-ready logs. Agents should never touch production systems directly — every interaction should go through a controlled execution environment.
Q. What is the difference between API-based AI integration and agentic AI integration?
API-based integration connects systems through their data layer, you hit an endpoint, transform a payload, write to a database. Agentic integration connects systems through their behavioral layer — the agent operates the interface the way a human would, reading screens, filling forms, navigating workflows. API integration is more reliable and performant when clean APIs exist. Agentic integration is the only viable path when they don’t. Most enterprise deployments use both: APIs where available, agent automation where they’re not.
Q. How does a local-first OpenClaw deployment work for regulated industries?
In a local-first deployment, OpenClaw and the AI models it invokes run entirely within your infrastructure perimeter — on-premises servers, private cloud, or an air-gapped environment. No data leaves your network. This meets data sovereignty requirements for healthcare (HIPAA), financial services, government, and other regulated sectors. The capability tradeoff is that on-premises models are typically less capable than frontier cloud models. The governance tradeoff is that you own the full operational responsibility for the AI infrastructure.
Q. What is the agent-as-orchestrator pattern and when should it be used?
In the agent-as-orchestrator pattern, OpenClaw doesn’t execute workflow steps directly — it coordinates the microservices, APIs, and task queues that do. The agent receives a high-level instruction, decides what to invoke and in what order, manages state across the workflow, and handles exceptions. This pattern works well when you have existing execution infrastructure you want to preserve, and you want the coordination logic to live in the AI layer without rewriting your underlying services.
Q. What are the biggest risks of deploying AI agents in enterprise environments?
Three risk categories dominate: autonomous behavior in high-stakes workflows (agents making incorrect decisions in situations that are expensive to unwind), skill supply chain risk (malicious or vulnerable community-built skills introducing security exposure), and governance gaps (shadow deployments that bypass approval processes and compliance controls). The mitigation for all three is the same: treat AI agent deployments with the same governance rigor as production software, because that’s what they are.
Q. How does Dextralabs approach OpenClaw enterprise integration?
We start with architecture before any deployment: mapping target systems, selecting integration strategies, designing the skill governance model, and defining the security perimeter. We then implement secure deployment infrastructure (zero-trust, least-privilege, sandboxed), build the legacy system integrations (including browser automation for systems with no API), establish governance and compliance frameworks, and productionize with error handling, monitoring, and operational runbooks. The goal is a system that runs reliably at scale — not a pilot that worked once under controlled conditions.