Retrieval-Augmented Generation, better known as RAG, has proven to be one of the greatest advances in large language model (LLM) development. It has provided a possible solution to one of the first-order problems of generative AI, namely, the inability to retrieve real-time and/or domain-specific information.
By linking models to an external data source, RAG enables a model to answer questions, incorporating facts or context. Accordingly, RAG will reduce hallucinations, become increasingly reliable, and provide a more useful and better service for business purposes.
Yet, as companies began to scale these systems, the limitations with traditional RAG became apparent. RAG pipelines often exhibit difficulties with context fragmentation, relevance, and reasoning. While they serve to retrieve information, they cannot interpret, rank, or reason with it.
This gap has given rise to a new phase of AI evolution — Context Engineering and Semantic Layers, where systems do more than just fetch data, they understand and reason with it. At Dextralabs, our AI consulting is helping enterprises to scale beyond RAG to conceptualize agentic AI systems that can think, retrieve, and reason on their own.
Understanding RAG: The Foundation of Contextual AI
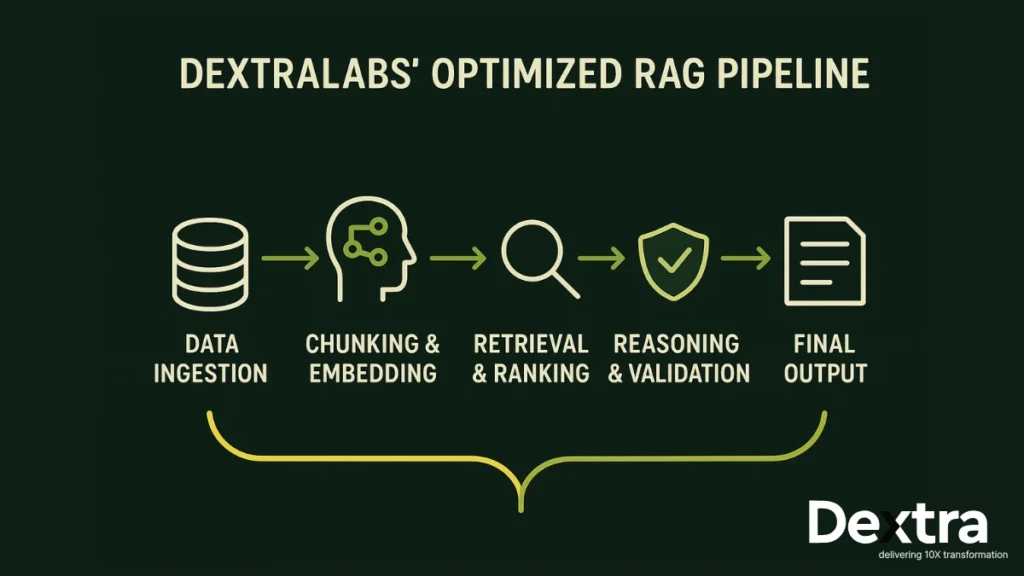
To understand why RAG needed evolution, we need to first define it. In really simple terms, RAG is a combination of two stages of intelligence – retrieval and generation.
When a user enters a query, the system converts the query into vector embeddings (i.e. the numerical representation of meaning). The vector embeddings are used to find the most relevant chunks of information. then the relevant context is added to the query prompt on the large language model for final generation.
This process allows the model to provide factually accurate responses without the need to retrain. RAG has many important benefits: it reduces hallucinations, allows updates to knowledge dynamically, and provides a more scalable and cost-effective AI system.
Dextralabs collaborates with organizations to design and implement an efficient RAG architecture using frameworks like LangChain, Pinecone, and FAISS. Each step of the retrieval pipeline is optimized by its consultants — document chunking, embedding generation, query expansion, and prompt engineering — to get enterprises at high recall while minimizing latency.
Drawbacks of Naïve RAG
Despite the significant advancement made in AI functionality through Retrieval-Augmented Generation (RAG), it is important to recognize the fundamental drawbacks of naïve RAG that organizations should think about.
Context Loss from Document Chunking:
Taking a larger document and chunking it into smaller pieces to store in a vector database can inherently destroy contextual relationships that are meaningful to retrieval. Related information may not be chunked together and won’t be retrieved together. The retrieval is far less likely to produce a quality-generated response.
Semantic Similarity Without Relevance:
RAG systems rely on mathematical similarity for retrieval. However, the existence of high semantic similarity does not guarantee textual relevance. The system may return text that appears to be relevant, but which fails to accurately answer the user’s intent, ultimately providing responses that are partially correct or not relevant at all.
Absence of Reasoning Ability:
Conventional RAG frameworks are based solely on retrieval and presentation. It is unable to synthesize, substantiate, or reason about the retrieved information. It cannot plan, evaluate, or improve its process, which is paramount for enterprise-grade reliability.
Dextralabs addresses these barriers through advanced orchestration and optimization frameworks. Consulting peak integration for multi-layer reasoning, enhanced retrieval filters, and ranking models to ensure the right data reaches the model at the right time.
In addition, the governance and validation layers are built to continuously monitor and confirm data replicability, compliance, and model runs. This converts RAG from a static retrieval process to a dynamic, adaptive intelligence loop capable of retrieving reliable data in context.
Beyond RAG — The Next Level of Intelligence Systems
AI’s next level should not be a simple retrieval and generation task. Instead, it will focus on developing reasoning-augmented, agentic AI systems that can understand context, achieve autonomous decision-making, and reason across multiple steps.
Dextralabs refers to this new paradigm as Context Engineering: The design and implementation of intelligent context layers that dynamically shape how an AI model understands and reasons about data. While previous methods retrieved chunks, systems applying context engineering build knowledge, filter noise, and reason through context in order to generate actionable insights.
The progression beyond RAG hinges on several essential capabilities:
- Knowledge Graph Integration: Connecting structured relations and unstructured sources while retaining meaning and context.
- Hybrid Retrieval Systems: Merging vector-based semantic search with symbolic or rule-based reasoning to improve correctness.
- Autonomous Reasoning Agents: Developing agents built upon LLMs that plan, test, and refine answers as opposed to simply returning text.
- Feedback and Reinforcement Capabilities: Allowing the system to learn from human use and provide self-assessments of performance.
- Explainable AI Frameworks: Ensuring outputs are transparent, accountable, and comply with enterprise governance processes.
Dextralabs uses these features to help organizations develop AI systems that are smart, adaptable, and trustworthy. These solutions are more than just responding to inquiries; they are supporting human decision-making at scale.
Dextralabs’ Approach to Advanced RAG Architecture
As one of the top AI consulting firms, Dextralabs works in a structured and end-to-end way to implement advanced RAG and semantic reasoning architectures. Their approach uniquely blends exceptional technical knowledge with thorough enterprise strategy understanding. A typical process includes:
Data Engineering and Knowledge Graph Design
- Cleansing, labeling, and linking the enterprise data into structured and unstructured knowledge formats. Creating knowledge graphs that maintain the relationships between data points for improved retrieval accuracy.
Vector Store & Index Optimization
- Choosing the right vector databases and fine-tuning the embeddings for better semantic precision.
- Implementing hybrid indexes using keyword and vector search to balance relevance and performance.
LangChain-style Orchestration of Retrieval and Reasoning
- Using LangChain and similar frameworks to create orchestrated pipelines where retrieval, reasoning, and validation live together.
Multi-Agent Collaboration Frameworks
- Developing intelligent agents capable of independent communication, reasoning, and knowledge sharing outside the confines of the workflow.
Governance, Monitoring, and Safeguards:
- Embedding monitoring for observability, security, and compliance to enable responsible AI operations.
Dextralabs seeks to deliver 10x transformation from disconnected AI experiments to interoperable, scalable, and measurable enterprise systems.
Use Cases — Where “Beyond RAG” Creates Value
The emergence of agentic, context-aware AI systems presents new opportunities across industries. Dextralabs is helping organizations use these capabilities in several real-world use cases:
- Enterprise Knowledge Assistants: Developing internal AI copilots knowledgeable about the organization’s knowledge bases, policies, and workflows to provide accurate information.
- Customer Support Automation: Creating intelligent bots that can reason through customer interactions, link to verified sources, and reduce reliance on humans.
- Healthcare & Legal Systems: Developing AI systems that comply with regulations, retrieve and reason over private information, and provide full traceability.
- Market Intelligence & Investments: Building analytical agents that constantly scan, understand, and combine financial or market data to enable strategic decision-making.
In all of these use cases, Dextralabs serves as a strategic AI partner – not just implementing technological solutions, but understanding and aligning those solutions to business outcomes, compliance, and longer-term scalability.
Safety, Governance, and Trust in Agentic AI
As AI systems become increasingly autonomous and capable of reasoning, ensuring safety and governance becomes critical. Trust is no longer merely a feature; it is a requirement for enterprise AI deployment.
Dextralabs builds safety into every phase of the AI lifecycle. Its consultants have a strong focus on bias mitigation, hallucination management, and traceability of every response to an AI. Validation and feedback are used continuously to keep those systems accurate, ethical, and aligned with human oversight.
They also bring in AI layers of audit, monitoring the reasoning steps, data sources, and compliance parameters, to ensure every actionable decision or output is explainable and accountable. Organizations can responsibly adopt agentic AI because of this ethical approach to AI governance.
Conclusion
Retrieval-Augmented Generation was a significant milestone in the advancement of AI. However, it is no longer adequate for the demands of modern-day enterprises. The AI of the future will consist of systems that eventually extract data, reason with that data, adapt, and learn new context – not just retrieve data.
Through the combination of context engineering, semantic layers, and principled reasoning architectures, Dextralabs is supporting organizations in developing intelligent, autonomous, and trustworthy AI systems. Their consulting practice provides teams with the confidence and framework to innovate and implement, laying the foundation for organizations to be ready for the next phase of the AI revolution: Agentic AI.
As organizations move from retrieval-based systems to context-aware intelligence, Dextralabs stands ready as a trusted partner in the design and deployment of the next generation of AI – smarter, safer, and more capable.
FAQs:
Q. Why is traditional RAG limited?
Naive RAG struggles with context loss, semantic irrelevance, and lack of multi-step reasoning.
Q. What is Context Engineering in AI?
It’s the creation of intelligent context layers that help AI systems understand, reason, and make better decisions.
Q. How are semantic layers transforming RAG systems?
Semantic layers link data intelligently, enabling reasoning beyond simple retrieval.
Q. How does Dextralabs enhance RAG architectures?
By integrating reasoning agents, knowledge graphs, and hybrid retrieval for enterprise-grade performance.
Q. In which industries can beyond-RAG AI be applied?
It benefits enterprise assistants, customer service, healthcare, legal, and market intelligence systems.









