GPT-3’s release was not merely a technological advancement; it redefined the way we perceive human-computer interaction. AI was no longer merely data processing or equation solving. With the capacity to create stories, provide humor, and converse, models such as ChatGPT demonstrated a new intelligence. But mimicking human behavior is one thing; understanding human emotion, humor, and intent is something else entirely.
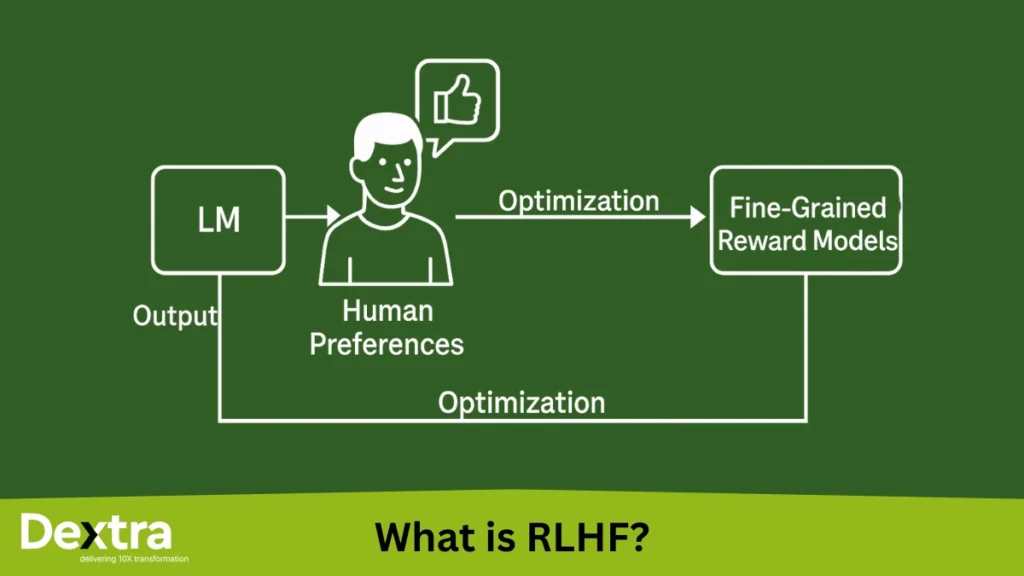
Enter RLHF, or Reinforcement Learning with Human Feedback, a revolutionary method in AI. So, what is RLHF in AI? Simply, it’s an approach wherein language models such as ChatGPT are trained based on human preferences to generate more natural, helpful, and aligned responses. Or referred to as AI RLHF, the method fills the gap between artificial intelligence and actual human communication.
At Dextralabs, we specialize in building AI systems that prioritize human context and clarity. By leveraging ChatGPT RLHF and other fine-tuning techniques, we’re helping businesses create smarter, more intuitive AI experiences.
In this post, we’ll explore how RLHF works, the tools that power it, and alternative methods shaping the future of aligned, human-centric AI.
What is RLHF? A Simple Yet Technical Explanation
RLHF is short for Reinforcement Learning from Human Feedback. It’s a machine learning approach that makes big language models such as ChatGPT more useful, safe, and human-value-aligned, not merely by being trained on data, but by being trained on humans.
RLHF Meaning: Breaking It Down
At its core, RLHF combines two powerful ideas:
- Reinforcement Learning (RL): A method where an agent learns to make decisions by receiving rewards or penalties.
- Human Feedback: Instead of using a pre-programmed reward function, humans guide the model by ranking its outputs based on quality, usefulness, or correctness.
This feedback is then used to fine-tune the model’s behavior through reinforcement learning, making the AI better at responding the way a human would expect.
So, when someone asks “What is RLHF?” or “RLHF explained”, the short answer is:
“It’s a way to train AI using human preferences to produce more natural and aligned responses.”
RLHF vs Traditional Reinforcement Learning
In traditional reinforcement learning, agents interact with an environment and learn from predefined rewards, like a robot learning to walk or a program mastering chess. The system knows exactly what outcomes are good or bad based on hard-coded rules.
With RLHF, the environment is far more complex (like human language), and the “right” answer is subjective. There’s no fixed reward function; humans provide guidance by ranking AI-generated outputs. This makes RLHF more flexible and ideal for training models like ChatGPT to behave safely and responsibly in open-ended conversations.
How RLHF Differs from Supervised and Unsupervised Learning?
- Supervised Learning teaches models using labeled data (e.g., correct answers for questions). It works well for tasks with clear answers.
- Unsupervised Learning explores patterns in unlabeled data, great for clustering or dimensionality reduction.
- RLHF goes a step further. It starts with a supervised phase (using good human examples), then adds reinforcement learning driven by human preference rankings to teach the model nuanced behavior.
That’s what sets RLHF apart: it learns not just from examples, but from judgments about quality and appropriateness.
Let’s look at the comparison table showing RLHF vs Supervised Learning vs Traditional RL:
| Feature | Supervised Learning | Reinforcement Learning | RLHF |
| Human in Loop | ✅ / ❌ | ❌ | ✅ |
| Feedback Type | Labels | Rewards | Ranked Responses |
| Model Adaptability | Moderate | High | Very High |
| Use in LLMs | Limited | Rare | Common |
The RLHF Process: How It Works in LLM Training?
To understand LLM RLHF (Reinforcement Learning from Human Feedback in Large Language Models), we need to look at the full training pipeline. Language models like ChatGPT don’t learn human-like behavior overnight; it’s a layered process that blends massive-scale data training with human-guided fine-tuning.
Here’s a simplified overview of how training language models to follow instructions with human feedback works.
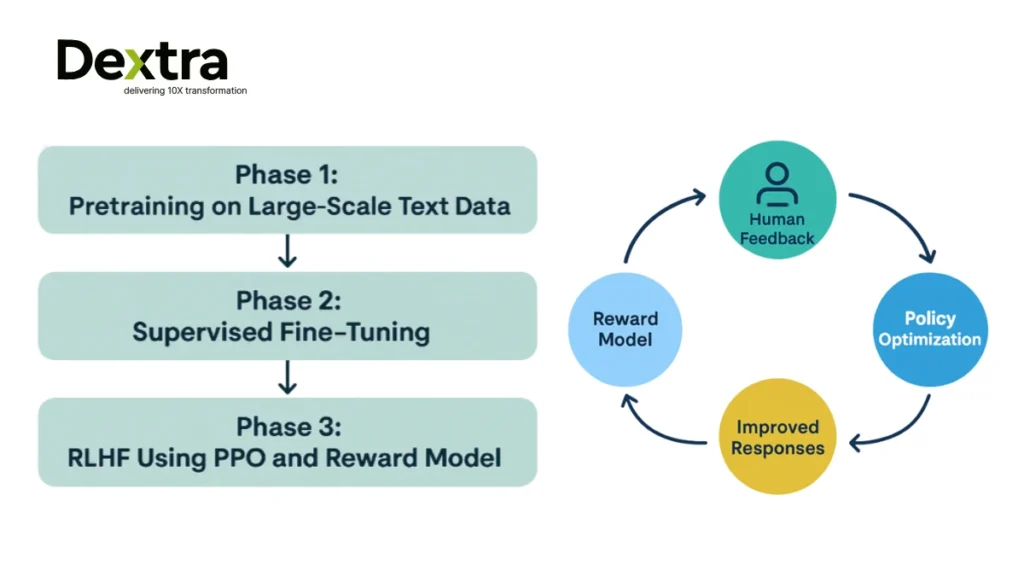
1. Pretraining: Building the Base Model
Everything begins with pretraining, where the LLM is exposed to vast amounts of text data from the internet. At this stage, the model learns the structure of language, grammar, facts, reasoning patterns, and more. However, it doesn’t yet know how to follow instructions or behave in a human-aligned way.
This is purely unsupervised learning: the model predicts the next word in a sentence based on context.
2. Supervised Fine-Tuning: Learning from Examples
Following supervised pre-training is supervised fine-tuning, in which the model is trained on a carefully selected dataset of human-created prompts and optimal human responses. This process trains the model to respond to prompts, making it more valuable for actual tasks.
Nevertheless, the model could output responses that are reasonable but do not meet user expectations or ethics. This is where LLM reinforcement learning is needed.
3. RLHF Phase: Optimizing with Human Feedback
The final stage is RLHF or reinforcement learning for LLMs using human preferences. This process introduces a reward model and a reinforcement learning algorithm (typically PPO, or Proximal Policy Optimization).
Here’s how it works:
- Generate Outputs: The fine-tuned model generates multiple responses to a given prompt.
- Human Ranking: Human annotators compare and rank the responses from best to worst.
- Train Reward Model: These rankings are used to train an RLHF reward model, which predicts a score for any given response based on its alignment with human preferences.
- Optimize with PPO: Using the reward model’s scores, RLHF PPO is applied to adjust the model’s parameters, reinforcing behaviors that humans prefer.
This iterative loop continues until the model consistently produces helpful, harmless, and honest outputs.
Why RLHF Matters in LLMs?
Without reinforcement learning LLM methods such as RLHF, even the latest models can provide responses that make sense but are deceptive or of little use. With human feedback in the loop, LLM RLHF makes sure AI systems have a better grasp of nuance, tone, context, and intent.
Human-in-the-Loop: Role of Feedback in RLHF
At the heart of RLHF lies one crucial ingredient: human judgment. While large language models can generate endless responses, deciding which response is best requires human understanding. This makes human-in-the-loop reinforcement learning a defining characteristic of RLHF.
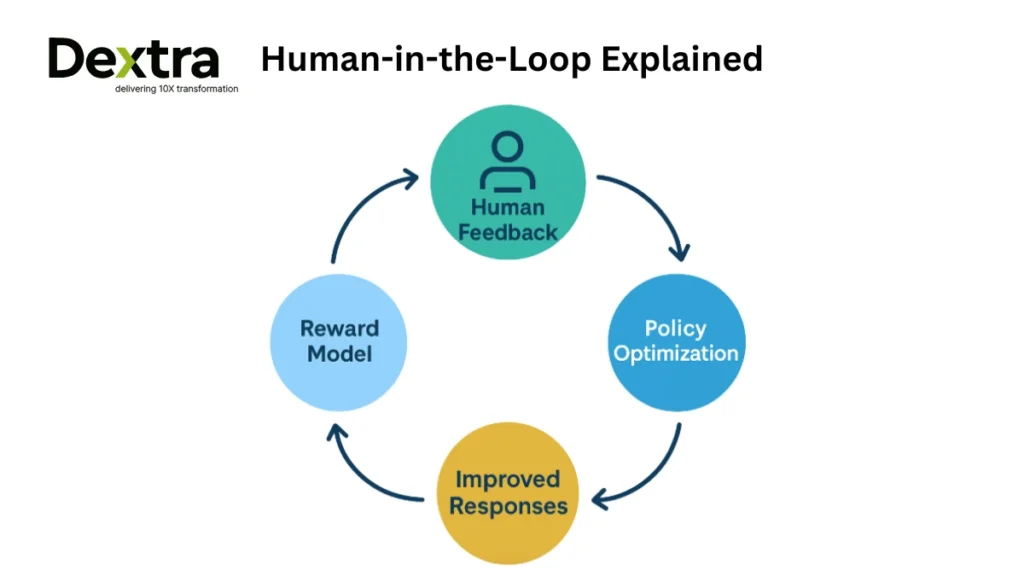
Human Evaluators: Ranking Model Responses
In human feedback reinforcement learning, real people, often called annotators, are tasked with evaluating the quality of model outputs. For example, given a user prompt, the model might generate 3–5 possible replies. Human evaluators rank them based on clarity, helpfulness, correctness, and tone.
This ranking process is repeated across thousands of samples, producing valuable training data for the next step: the reward model.
Reward Modeling: Turning Judgment into Training Signals
The ranked outputs are used to train a reward model, which learns to predict which responses are most aligned with human preferences. This model acts as a proxy for human judgment in future iterations, allowing for scalable human reinforcement learning without needing a human to review every new output.
Once the reward model is ready, the language model is further fine-tuned using reinforcement learning algorithms like PPO. This closes the feedback loop, reinforcing responses that reflect high-quality human preferences.
Ethical and Quality Challenges in Human Annotation
Despite its benefits, human-in-the-loop reinforcement learning introduces some serious challenges:
- Bias and inconsistency: Different annotators may have varying opinions, cultural backgrounds, or ethical standards, which can affect the consistency of the training signal.
- Scalability: Annotating at scale is expensive, time-consuming, and mentally demanding for human evaluators.
- Alignment risks: Overfitting to human preferences can cause models to become overly safe, evasive, or politically biased.
To mitigate these risks, developers often use clear guidelines, diverse annotator pools, and constant monitoring of model behavior post-training.
Technical Deep Dive: Algorithms and Implementation
Having covered the human and conceptual levels of RLHF, let’s dive into the technical engine that drives it. The focus of this section is on how RLHF implementation operates in the real world, which algorithms are employed, how the reward model works, and the type of RLHF datasets that are a part of the process.
Proximal Policy Optimization (PPO): The Algorithm Behind RLHF
At the core of RLHF fine-tuning lies an algorithm called Proximal Policy Optimization (PPO). PPO is a reinforcement learning technique that strikes a balance between improving the model and keeping it from diverging too far from its original behavior.
Here’s how PPO works in RLHF implementation:
- The pretrained language model generates several outputs for a given prompt.
- The reward model scores each output based on how well it aligns with human preferences.
- PPO updates the model’s parameters to increase the probability of high-scoring outputs, but with constraints to prevent overly aggressive changes that could harm stability or performance.
PPO is popular in RLHF code implementations (e.g., OpenAI’s and Hugging Face’s training pipelines) because it’s both efficient and robust for large-scale models.
Importance of the Reward Model
The reward model is the backbone of human-aligned training. It learns from thousands of human rankings and acts as a proxy for human feedback during RLHF fine-tuning.
This model transforms subjective judgments into scalar reward signals, which are then used by PPO to adjust the LLM’s responses. The reward model itself is typically trained using supervised learning on annotated rankings before being integrated into the reinforcement loop.
Datasets Used in RLHF
A good RLHF dataset is key to success. One of the most well-known examples is OpenAI’s InstructGPT dataset. It contains:
- Prompt–response pairs
- Ranked outputs (from multiple model completions)
- Ideal answers crafted by human labelers
Other notable RLHF datasets include:
- Anthropic’s HH-RLHF dataset (Harmlessness, Helpfulness)
- OpenAssistant Conversations Dataset (OASST1)
- Public contributions to platforms like OpenChat or LAION-AI
These datasets are used both to train the reward model and to validate the improvements made during RLHF implementation.
Open-Source RLHF Codebases
Developers looking to implement RLHF can explore several RLHF code resources:
- TRLX (by CarperAI): A popular library built for scalable RLHF with PPO.
- DeepSpeed-Chat: Microsoft’s framework for efficient training of chat models with human feedback.
- Hugging Face TRL (Transformers Reinforcement Learning): Great for experimentation with LLMs and PPO.
- OpenAI Baselines (for RL primitives and PPO reference code)
These frameworks support end-to-end RLHF fine tuning, from dataset loading to model optimization.
Applications of RLHF in Large Language Models (LLMs):
The application of reinforcement learning, specifically Reinforcement Learning from Human Feedback (RLHF) has redefined what large language models (LLMs) can do.
Today, some of the most advanced AI systems, like ChatGPT, Claude, and Gemini, rely heavily on GPT reinforcement learning techniques to make their interactions feel intelligent, helpful, and aligned with human expectations.
These models don’t just respond, they adapt, reason, and follow instructions with nuance. This capability is largely thanks to the final stage of the LLM training process: RLHF.
ChatGPT and GPT-Based Reinforcement Learning
OpenAI’s ChatGPT reinforcement learning pipeline is one of the most prominent examples of RLHF in action. After pretraining and supervised fine-tuning, ChatGPT is optimized using PPO-based reinforcement learning, guided by human feedback. This allows it to:
- Respond more safely to sensitive questions
- Avoid hallucinations and offensive outputs
- Follow user instructions more effectively
This approach has been extended and adapted by others in the field.
Other LLMs Using RLHF
- Claude (Anthropic) uses a safety-focused RLHF variant with emphasis on helpfulness, honesty, and harmlessness.
- Gemini (Google DeepMind) integrates RLHF to improve conversational flow and factual grounding in complex queries.
- Mistral, Cohere, and Meta’s Llama-3 models are also exploring RLHF in fine-tuning public and private versions of their open-source LLMs.
Each model’s application of GPT reinforcement learning is unique but rooted in the same goal: aligning AI behavior with human values.
Real-World Use Cases Powered by RLHF:
- Content Generation
- Writing blog posts, ad copy, social media captions with consistent tone and voice.
- RLHF ensures content is not just grammatically correct but aligned with brand intent.
- Writing blog posts, ad copy, social media captions with consistent tone and voice.
- Code Assistance
- Tools like GitHub Copilot and GPT-4 Code Interpreter provide real-time help with debugging, code generation, and refactoring.
- Reinforcement learning LLM strategies help these systems learn from developer feedback.
- Tools like GitHub Copilot and GPT-4 Code Interpreter provide real-time help with debugging, code generation, and refactoring.
- Healthcare AI
- Assisting doctors with documentation, summarization of medical literature, or patient interaction simulation.
- Human oversight during training helps avoid critical factual errors.
- Assisting doctors with documentation, summarization of medical literature, or patient interaction simulation.
- Legal & Compliance
- Drafting contracts, summarizing legal cases, or interpreting policies.
- RLHF ensures responses stay within ethical and legal boundaries critical in high-stakes domains.
- Drafting contracts, summarizing legal cases, or interpreting policies.
RLHF vs Other Training Approaches
| Training Approach | Description | Strengths | Limitations | When to Use |
| Supervised Learning(RLHF vs supervised learning) | Models are trained on labeled data (prompt + correct response). | Simple to implement, requires less computing. | Lacks flexibility; can’t adapt well to subjective tasks like conversation. | Structured tasks with clear right/wrong answers (e.g., classification, summarization). |
| Fine-Tuning Without Human Feedback | Continuation of training using new datasets (instruction tuning or domain-specific corpora). | A quick way to adapt models to specific domains. | No alignment to human judgment; risks harmful or low-quality outputs. | Adapting models to specific tasks or industries. |
| RLHF(Fine-tuning language models from human preferences) | Combines supervised fine-tuning with deep reinforcement learning from human preferences (e.g., PPO + reward model). | Aligns model behavior with human expectations; improves safety, quality, and nuance. | Expensive; requires human annotators and large-scale infrastructure. | Open-ended tasks like dialogue, content generation, or any scenario requiring human-like understanding. |
Benefits and Limitations of RLHF:
In order to grasp the way RLHF functions at scale, it’s essential to consider both its benefits and drawbacks. As a method of aligning AI with human values, Reinforcement Learning with Human Feedback (RLHF) has advanced greatly in safety and utility, but at the cost of trade-offs.
Benefits of RLHF:
1. Better Instruction Following
Since RLHF is constructed based on true human preferences, it greatly enhances the model’s capacity to comprehend and abide by instructions in natural language. This results in interactions with RLHF AI systems being more productive and user-friendly.
2. Safety and Harm Reduction
Through human-guided feedback loops, RLHF reduces the chances of harmful, toxic, or biased outputs, key for real-world deployment in healthcare, education, and legal tech.
3. Human-AI Alignment
At its core, reinforcement learning human feedback ensures models behave in ways that are more aligned with human intent, values, and social norms, something traditional training methods can’t fully guarantee.
Limitations of RLHF:
1. Scalability Issues
The RLHF process relies heavily on human annotators to rank outputs. Scaling this human-in-the-loop approach is both resource-intensive and time-consuming.
2. Bias in Human Judgment
Since human feedback is subjective, it can introduce bias into the model, especially if the annotator pool lacks diversity. This can affect the neutrality and fairness of RLHF AI systems.
3. Annotation Fatigue
Ranking responses across thousands of samples leads to annotation fatigue, which may degrade feedback quality over time and introduce inconsistencies into the reward model.
RLHF in the Research Community
Reinforcement Learning from Human Feedback (RLHF) owes much of its success to the research community. From seminal papers to open-source toolsets, RLHF has rapidly emerged as a central domain of innovation in aligning large language models (LLMs) with human values and intentions.
Landmark RLHF Papers & Breakthroughs
The most influential work in this field is OpenAI’s 2022 paper: “Training language models to follow instructions with human feedback”, commonly known as the InstructGPT paper.
This RLHF paper by OpenAI introduced a three-stage process:
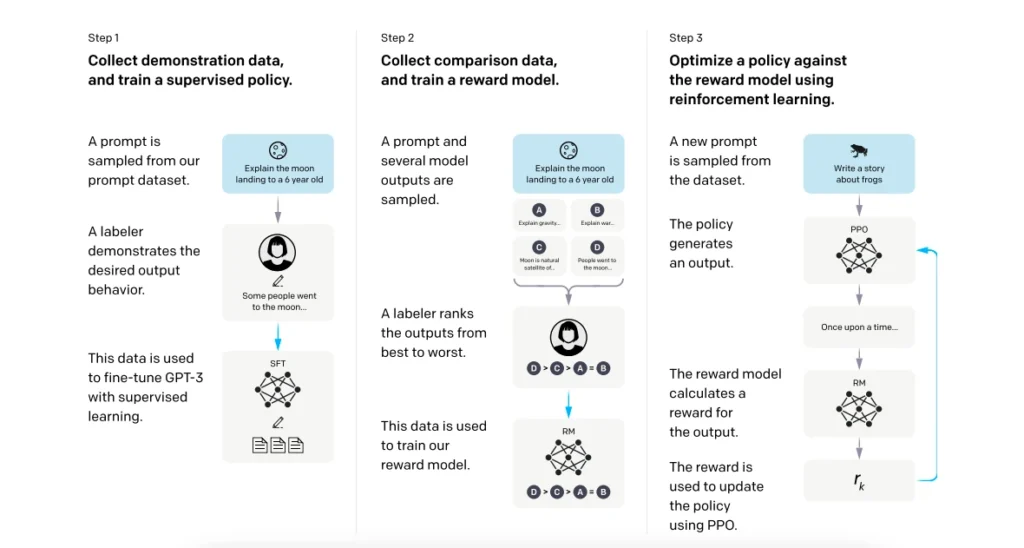
- Supervised Fine-Tuning (SFT): Using prompt–response pairs created by humans.
- Reward Modeling: Using human rankings to train a model that predicts preferred outputs.
- RLHF with PPO: Fine-tuning the LLM using Proximal Policy Optimization, guided by the reward model.
The paper demonstrated that smaller models trained with human feedback often outperformed much larger models trained only via traditional methods, redefining the field of instruction-following LLMs.
Other notable research efforts:
- Anthropic’s work on Constitutional AI, which blends rule-based oversight with RLHF.
- DeepMind’s Sparrow, an RLHF-trained chatbot with safety constraints.
- Meta’s LLaMA and OPT projects, which explore scalable RLHF for open models.
These studies continue to answer the question: How can we improve training language models with language feedback from real users?
Open-Source RLHF Initiatives & Toolkits
As demand for RLHF grows, the community has responded with a number of open-source tools to make experimentation easier:
| Toolkit | Description |
| TRL by Hugging Face | A Python library to implement PPO-based RLHF workflows on top of Transformer models. Great for research and prototyping. |
| TRLX by CarperAI | Designed to replicate the InstructGPT pipeline, this is one of the closest open-source approximations of the rlhf paper OpenAI workflow. |
| OpenChatKit (by Together.ai) | Combines supervised instruction tuning with human feedback loops for safer chatbot development. |
| DeepSpeed Chat | Microsoft’s framework for cost-efficient, scalable RLHF training with large models. |
These platforms allow developers and researchers to run training language models with language feedback at scale or even replicate parts of commercial RLHF workflows like those used in ChatGPT and Claude.
The Road Ahead
As models grow more powerful, the research focus is shifting to how we scale RLHF:
- Synthetic feedback using AI-generated rankings
- Preference modeling using fewer annotations
- Evaluating alignment through behavior and values, not just accuracy
RLHF is no longer an experimental afterthought; it’s a central pillar of responsible AI development. And the research community continues to refine both its scientific foundations and its practical applications.
Future of RLHF: Trends, Jobs & Open Questions
As AI becomes increasingly smart and multi-modal, Reinforcement Learning from Human Feedback (RLHF) is likely to extend significantly beyond text. The future of RLHF is determined by new applications, changing career trajectories, and urgent research questions that the community is just now grappling with.
RLHF in Multi-Modal Models
The next frontier is multi-modal RLHF training AI models that understand not just language, but also images, videos, and speech, with human feedback integrated across all formats.
Imagine training a video-generating AI to follow editorial tone, scene flow, or emotional cues guided by reinforcement learning standards of measurement rooted in human judgment. Multi-modal RLHF is already being investigated by the likes of OpenAI (Sora), Google DeepMind (Gemini), and Anthropic.
As these systems expand, knowing when to apply reinforcement learning becomes important. Not every problem is helped by it, but those that need open-ended generation, personalization, or safety often are.
RLHF Jobs: The People Behind the Model
With the rise of human-feedback-driven training, new career roles are emerging in the AI ecosystem:
| Role | Description |
| Data Labelers / Annotators | Rank model outputs based on clarity, relevance, and tone. Critical for building reward models. |
| AI Trainers | Provide high-quality example completions and instruction-following demonstrations. |
| RLHF Researchers / ML Engineers | Design, implement, and optimize the RLHF pipeline (PPO, reward modeling, etc.). |
| Prompt Engineers | Craft effective prompts and evaluate model behavior across tasks. |
Searches for RLHF jobs and RLHF tutorial content are rapidly growing, making it a promising space for tech professionals and educators alike.
Standards & Open Research Questions
As RLHF matures, the field faces key challenges:
- Standardized Evaluation: How do we define success in RLHF? Metrics like helpfulness, harmlessness, and honesty are subjective. The field is moving toward consistent reinforcement standards of measurement yet the “answer key” remains elusive.
- Annotation Efficiency: Can models help train themselves? How do we reduce human effort without losing quality?
- Cross-Cultural Feedback Models: How can we avoid bias and represent global diversity in human feedback?
These questions aren’t just academic; they directly impact how safe, fair, and generalizable tomorrow’s AI systems will be.
Conclusion: Is RLHF the Key to Safer AI?
As large language models grow more powerful, so does the urgency to align them with human values, expectations, and ethical boundaries. Reinforcement Learning from Human Feedback (RLHF) sits at the heart of this transformation—bridging the gap between raw computational intelligence and meaningful, human-centric interaction.
From OpenAI’s InstructGPT to today’s most advanced multi-modal models, RLHF is redefining how AI systems are trained, trusted, and deployed. By embedding human feedback directly into the LLM training loop, we’re not just teaching models to generate words—we’re guiding them to understand nuance, context, and consequence.
But RLHF isn’t a silver bullet. While it improves instruction-following, reduces toxic outputs, and enhances user satisfaction, it also raises real concerns around bias, consistency, and scalability. After all, human judgment, while invaluable, is inherently imperfect.
At Dextralabs, we recognize both the promise and complexity of RLHF. As part of our AI Consulting services, we help businesses deploy enterprise-grade LLMs, build custom models, design AI agents, and refine results through prompt engineering—ensuring your AI not only performs but aligns with your users and your values.
Because building safer AI isn’t just about better models—it’s about putting humans in the loop, thoughtfully.
FAQs on Reinforcement Learning with Human Feedback:
Q. What is the RLHF method?
RLHF (Reinforcement Learning with Human Feedback) is a technique where human feedback is used to train language models by ranking outputs and optimizing them using a reward model and reinforcement learning loop.
Q. What is RLHF in ChatGPT?
RLHF in ChatGPT helps the model learn to follow instructions better by fine-tuning responses based on human preferences, using methods like PPO. This makes ChatGPT reinforcement learning more aligned and useful.
Q. What is the difference between SFT and RLHF?
SFT (Supervised Fine-Tuning) uses labeled data to guide model behavior, while RLHF involves a human-in-the-loop approach where feedback helps train a reward model, allowing deep reinforcement learning from human preferences.
Q. What is reinforcement learning with human feedback for LLM?
It’s a way to train LLMs like GPT by collecting human rankings on outputs, building a reward model, and using reinforcement learning (like PPO) to align outputs with user intent. It improves the LLM training process significantly.
Q. What technique helps improve LLMs through human feedback?
RLHF is the primary technique, especially effective in training language models with language feedback and ranking outputs based on usefulness or safety.
Q. What is the human feedback loop in LLM?
It involves generating model outputs, getting human feedback, training a reward model, and optimizing the policy — creating a feedback loop for continuous improvement in LLMs.
Q. What is the difference between RLHF and RLAIF?
RLHF uses explicit human rankings, while RLAIF (Reinforcement Learning with AI Feedback) uses AI-generated feedback. RLHF is more aligned with human values, but RLAIF can scale faster.
Q. What is reinforcement learning with human feedback?
It’s a method of aligning AI outputs with human intent by using feedback from people to fine-tune how models respond — a key factor in fine-tuning language models from human preferences.
Q. Is reinforcement learning based on our feedback?
In RLHF, yes. Human feedback is used to train a reward model which guides the model to generate better, more human-like responses, enhancing the application of reinforcement learning in AI.
Q. Is RLHF offline RL?
Yes, RLHF is often considered a form of offline reinforcement learning, where the model learns from static datasets of human feedback instead of real-time interactions.
Q. When to use reinforcement learning?
Use it when the goal is to optimize behavior over time with rewards, especially when user preferences or dynamic tasks are involved — perfect for chatbots, robotics, or game AI.
Q. What is reinforcement learning used for?
It’s used in AI for decision-making tasks, from ChatGPT reinforcement learning and game-playing agents to recommendation engines and robotics, making it vital to the application of reinforcement learning.