Running advanced artificial intelligence on a Raspberry Pi was once an academic curiosity rather than a practical option. Limited memory, modest processing power, and strict energy budgets forced most serious workloads into the cloud. That landscape has shifted.
Recent advances in model design, training efficiency, and inference optimization have made it possible for compact language and vision systems to operate directly on low-power devices For example, benchmarks show that compact language models can run on a Raspberry Pi 5 at 15+ tokens per second, enabling practical on-device AI without the cloud (learn.arm.com)
With careful quantization and efficient runtimes, models measured in billions of parameters—not tens of billions—can now perform reasoning, summarization, structured generation, and multimodal interpretation entirely on CPU-based hardware.
The Raspberry Pi has become a proving environment for this transition. Models that function reliably within their constraints tend to scale cleanly across embedded systems, offline deployments, and edge infrastructure. This blog examines seven AI models that demonstrate strong performance on Raspberry Pi–class devices, selected for operational usefulness rather than theoretical scale.
Also Read: Production-Grade Generative AI in 2026
What Qualifies an AI Model for Raspberry Pi Deployment?
Edge hardware introduces constraints that reshape model evaluation criteria. Parameter count alone is irrelevant without architectural efficiency.
Models suitable for Raspberry Pi deployments typically exhibit the following:
- Compact memory usage after INT8 or INT4 quantization
- Stable inference behavior on ARM CPUs
- Efficient handling of extended input
- Predictable output structure
- Compatibility with tool execution or constrained generation
The following models meet these requirements in distinct ways, each optimized for a different class of edge workload.
The 7 Tiny AI Models That Actually Work on Raspberry Pi
The following seven models stand out because they are architecturally efficient, quantization-friendly, and capable enough to support real workloads on Raspberry Pi–class hardware.
1. Qwen3 4B: The Best All-Around Tiny Language Model
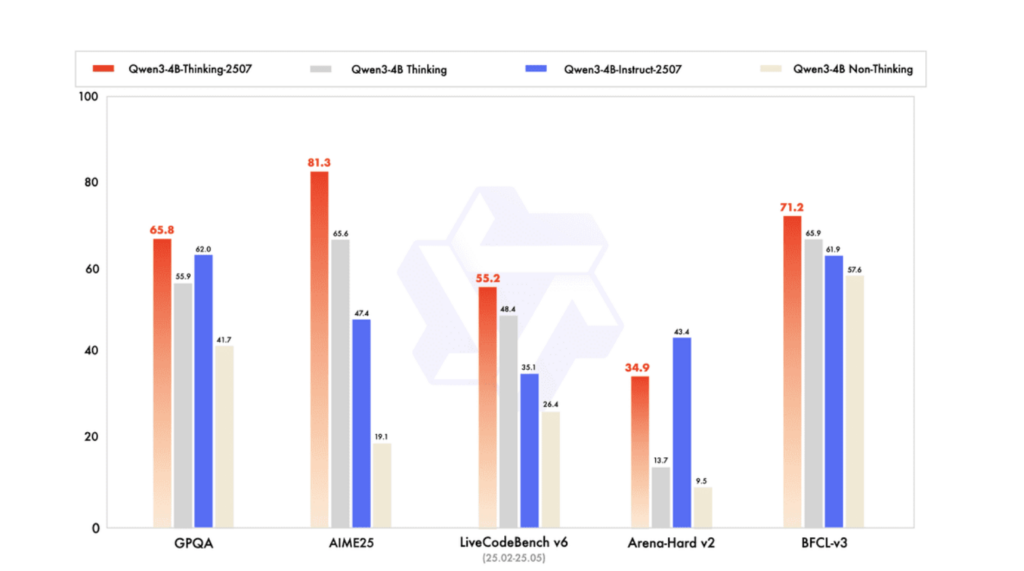
Qwen3 4B represents a major milestone for compact language models. It demonstrates that strong instruction following, reasoning, and tool usage are no longer exclusive to large-scale systems.
Despite its relatively small parameter count, Qwen3 4B performs consistently well across a wide range of tasks, from conversational assistance to structured output generation. Its training emphasizes alignment and practical usability rather than raw benchmark chasing, which shows in real-world deployments.
Why it works well on Raspberry Pi?
- The architecture scales down efficiently under INT8 or INT4 quantization
- Inference remains stable under CPU-only execution
- Latency is predictable, even with longer prompts
Key strengths
- High-quality text generation across technical and non-technical domains
- Strong multilingual support, making it useful in global deployments
- Long-context handling suitable for real documents, logs, and reports
- Excellent performance-to-memory ratio when quantized
Best use cases
- Local assistants and copilots
- On-device knowledge agents
- Embedded automation and workflow support
For most Raspberry Pi deployments, Qwen3 4B is the safest and most versatile starting point, offering an excellent balance between speed, accuracy, and capability.
2. Qwen3-VL 4B: Multimodal Intelligence on the Edge
Qwen3-VL 4B extends the Qwen3 family into multimodal reasoning, combining language understanding with image and video perception in a compact form factor.
Unlike earlier vision-language models that were impractical outside GPUs, Qwen3-VL 4B is designed to operate efficiently under constrained environments, especially when vision workloads are selective rather than continuous.
What makes it notable
- Native multimodal reasoning grounded in both text and vision
- Strong image–text alignment for document and UI understanding
- Ability to support visual workflows locally without cloud dependencies
- Efficient handling of long multimodal contexts
Why it matters for edge AI
Running multimodal inference locally enables:
- Privacy-preserving image analysis
- Offline document understanding
- Reduced bandwidth and cloud costs
Best use cases
- Local document and image analysis
- Embedded visual assistants
- Edge-based UI or dashboard understanding
On Raspberry Pi–class hardware, Qwen3-VL 4B enables practical multimodal intelligence, something that was previously unrealistic at the edge.

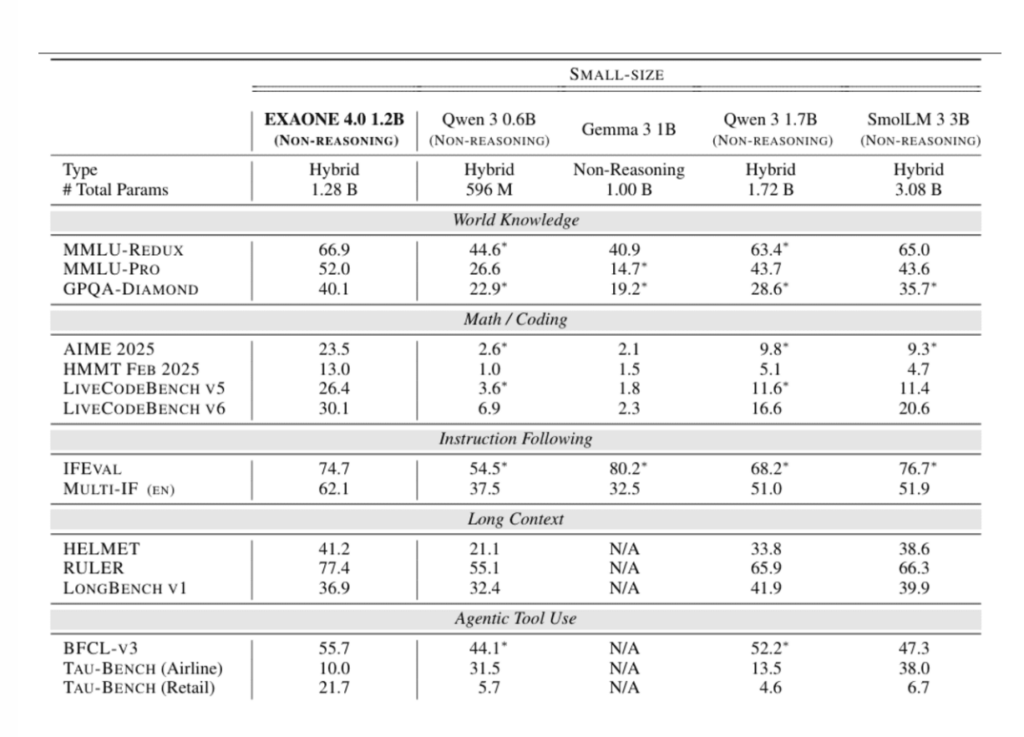
3. EXAONE 4.0 1.2B: Agentic Reasoning in a Minimal Footprint
EXAONE 4.0 1.2B proves that agentic behavior does not require large models. Designed specifically for efficiency, it introduces flexible reasoning depth within a very small memory footprint.
The model supports both:
- Fast, non-reasoning responses for routine tasks
- Optional deeper reasoning for more complex decisions
This makes it particularly well suited for edge scenarios where compute budgets fluctuate.
Key characteristics
- Dual-mode reasoning (speed vs. depth)
- Built-in support for tool calling and function execution
- Multilingual capabilities beyond English
- Long-context support relative to its size
Why it excels on constrained devices
- Low RAM requirements after quantization
- Quick cold starts
- Minimal inference overhead
Best use cases
- Lightweight autonomous agents
- Edge task orchestration
- Local decision-support systems
For environments where memory, power, and latency are tightly constrained, EXAONE 1.2B offers one of the best capability-to-footprint ratios available.
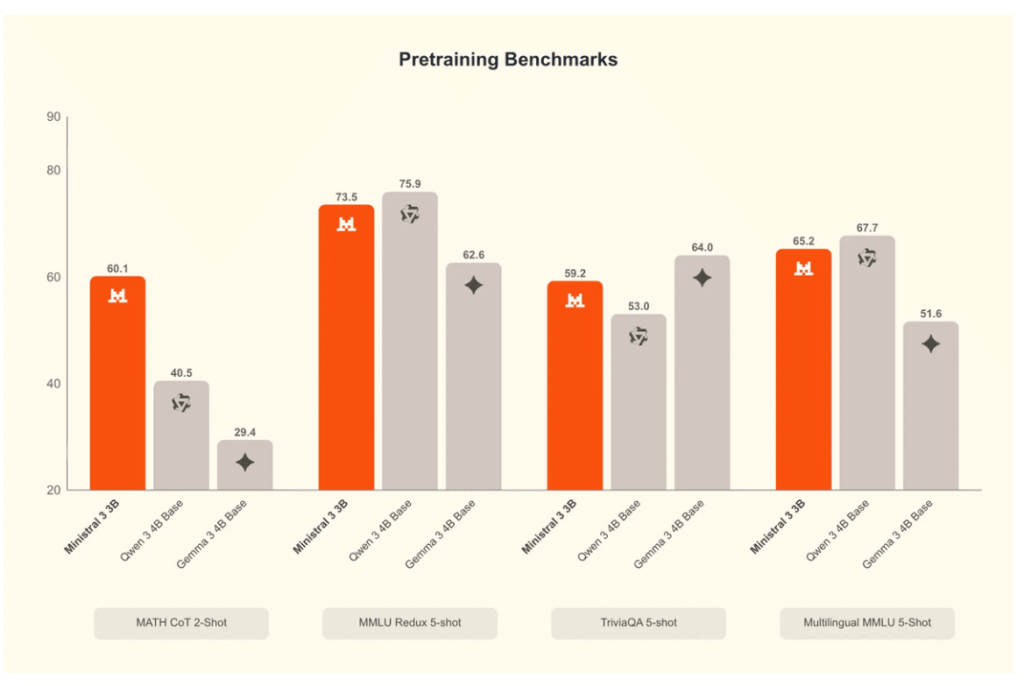
4. Ministral 3B: Efficient Multimodal Edge Assistant
Ministral 3B combines a compact language model with a lightweight vision encoder, enabling native multimodal understanding without the overhead of larger systems.
Its instruction-tuned design focuses on predictable behavior, structured outputs, and strong prompt adherence, which are critical for production deployments.
Highlights
- Native multimodal input (text + images)
- Strong instruction following and output consistency
- Structured outputs and function calling support
- Broad multilingual coverage
Why it fits edge deployments
- Optimized for performance per watt
- Works well under aggressive quantization
- Stable behavior in continuous operation
Best use cases
- Embedded assistants
- Kiosks and terminals
- Distributed edge environments
Ministral 3B is particularly well suited for real-time, user-facing edge systems where reliability matters more than creative output.
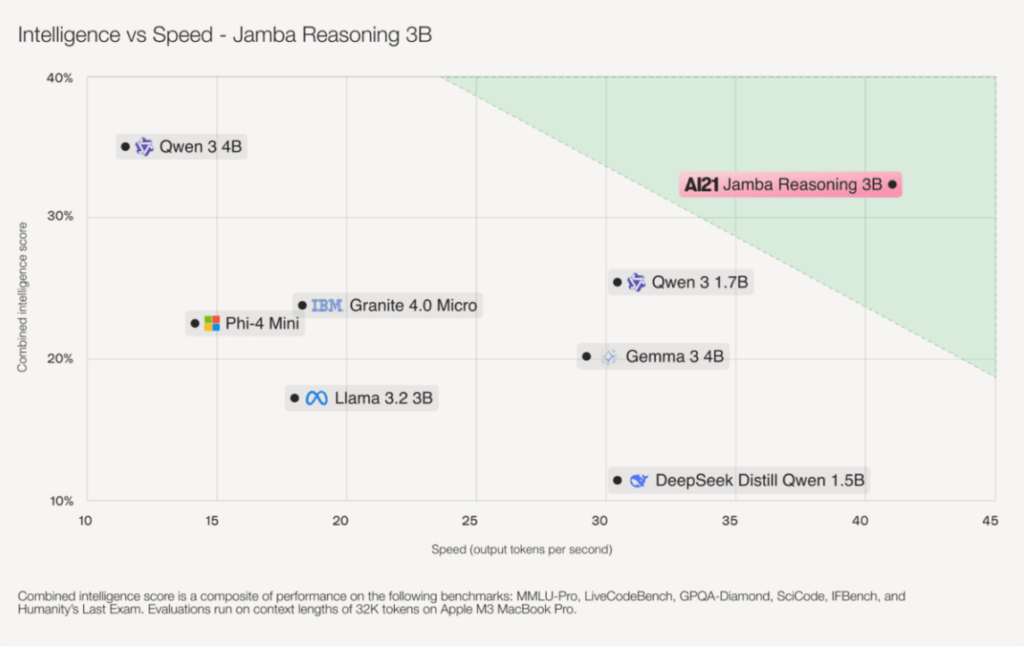
5. Jamba Reasoning 3B: Long Context Without Heavy Attention
Jamba Reasoning 3B introduces a hybrid Transformer–Mamba architecture designed to solve one of the hardest problems in edge AI: long-context processing without excessive memory use.
Instead of relying entirely on attention mechanisms, Jamba uses state-space models for most layers, dramatically reducing memory overhead while maintaining reasoning capability.
Why it stands out
- Extremely efficient long-context handling
- Reduced memory and attention cache requirements
- Strong reasoning performance for its size
- Predictable and controllable inference costs
Why this matters on Raspberry Pi
Long documents, logs, or streams quickly overwhelm traditional transformers on small devices. Jamba’s architecture makes these workloads feasible.
Best use cases
- Log analysis
- Long-document summarization
- Continuous data stream interpretation
For edge workloads involving large or continuous inputs, Jamba Reasoning 3B is uniquely well matched.
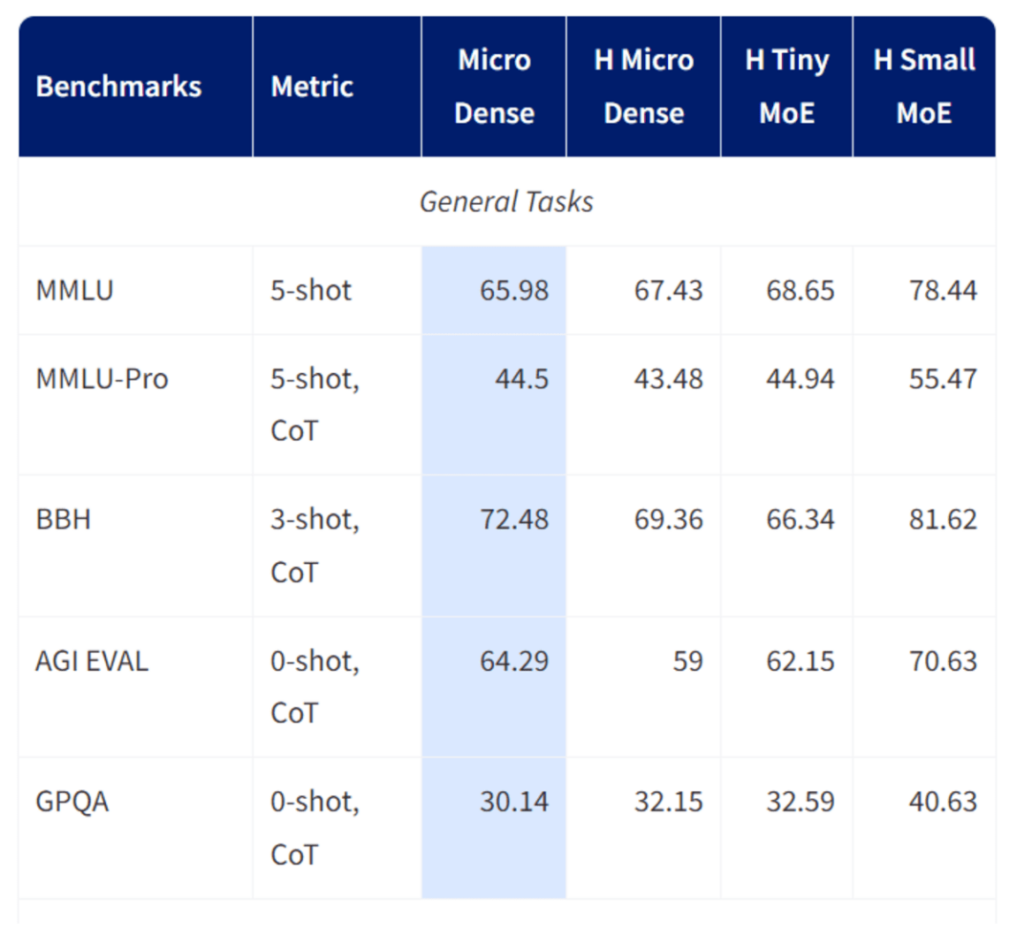
6. Granite 4.0 Micro: Enterprise-Grade Tiny Assistant
Granite 4.0 Micro is designed for enterprise environments where reliability, safety, and consistency are more important than raw creativity.
It emphasizes predictable output, strong system prompt adherence, and clean integration with external tools.
Core strengths
- Professional and stable response style
- Strong tool execution and function calling
- Long-context support for enterprise documents
- Open licensing suitable for commercial deployment
Why enterprises choose Granite Micro
- Lower risk of erratic behavior
- Better alignment for business workflows
- Easier governance and compliance
Best use cases
- Internal enterprise assistants
- Edge-based business tools
- Knowledge management systems
Granite 4.0 Micro is ideal when trust and consistency matter more than expressive flexibility.
7. Phi-4 Mini – Reasoning-Dense and Memory-Efficient
Phi-4 Mini focuses on reasoning quality per parameter, rather than broad factual coverage. Its training strategy emphasizes structured, textbook-like data, resulting in strong logical consistency and instruction adherence.
This makes it particularly effective in constrained environments where efficiency and correctness are critical.
Notable features
- High reasoning density per parameter
- Long-document understanding uncommon at this size
- Robust safety and alignment behavior
- Efficient inference under tight memory constraints
Why it works well on Raspberry Pi
- Stable performance when heavily quantized
- Low hallucination tendency relative to size
- Clear, structured responses
Best use cases
- Technical assistants
- Educational tools
- Structured analysis and reasoning tasks
For applications that demand clarity, structure, and correctness, Phi-4 Mini is a strong choice.

Where These Models Deliver the Most Value?
On Raspberry Pi–class devices, these systems enable:
- Offline summarization and analysis
- Local document review
- Embedded decision-support tools
- Edge diagnostics and monitoring
- Privacy-preserving AI assistants
Such deployments reduce reliance on remote infrastructure while maintaining functional intelligence.
Why Architecture and Systems Matter as Much as the Model?
Selecting a capable model solves only part of the problem. Edge deployments frequently fail due to unmanaged context growth, uncontrolled inference loops, or insecure tool execution.
Reliable operation depends on:
- Context regulation
- Reasoning depth limits
- Memory lifecycle control
- Execution safeguards
Without these elements, even well-designed models behave unpredictably under real workloads.
Also Read:- Real-World Agent Examples with Gemini 3: Why Production-Grade Cognitive Agents Are the Future
Dextralabs: Engineering Edge AI for Real Environments
Dextralabs approaches edge intelligence as a systems challenge rather than a model showcase. The focus remains on predictable behavior, resource efficiency, and operational safety.
Dextralabs’ work in this area includes:
- Optimized inference pipelines for low-power devices
- Structured reasoning control to manage latency
- Memory governance to prevent context drift
- Secure integration with external tools and services
- Scalable orchestration across distributed edge nodes
This methodology ensures that compact models deployed on devices such as Raspberry Pi remain reliable beyond experimental use.
Also Read: How LLM become genius with RAG? Dextralabs blueprint 2026?
Conclusion
The assumption that meaningful AI requires massive infrastructure no longer holds. With the right architectures and disciplined system design, Raspberry Pi–class hardware can support language understanding, visual reasoning, and autonomous behavior.
The seven models outlined above demonstrate that compact AI systems have matured into practical tools. Their value lies not in scale, but in efficiency, adaptability, and suitability for real-world constraints.
For teams exploring local inference or edge deployments, these models provide a strong foundation for building intelligent systems that operate where the data lives.
At Dextralabs, this shift toward practical edge intelligence is approached as an engineering challenge rather than a model showcase. By combining efficient models with controlled reasoning, memory governance, and secure execution, we enable organizations to deploy reliable AI systems where computation, data, and decisions must live locally.
FAQs:
Q. Can AI models really run on a Raspberry Pi?
Yes. Modern compact AI models can run on a Raspberry Pi using CPU-only inference when properly quantized (INT8 or INT4). Advances in model architecture and optimization allow language and vision tasks to execute locally without GPUs or cloud access.
Q. What makes an AI model suitable for Raspberry Pi deployment?
An AI model must be memory-efficient, stable on ARM CPUs, support quantization, and produce predictable outputs. Models designed for edge environments also handle long inputs efficiently and avoid excessive compute or attention overhead.
Q. Which AI models work best on Raspberry Pi?
Models such as Qwen3 4B, Phi-4 Mini, EXAONE 1.2B, Jamba Reasoning 3B, and Granite 4.0 Micro perform well on Raspberry Pi–class hardware. They balance reasoning capability with low memory and CPU requirements.
Q. Can Raspberry Pi run multimodal AI models?
Yes. Lightweight multimodal models like Qwen3-VL 4B and Ministral 3B can process text and images locally on Raspberry Pi when workloads are optimized. This enables privacy-preserving document analysis and visual assistants without cloud dependence.
Q. Do Raspberry Pi AI deployments require a GPU?
No. All models discussed in this article run on CPU-only hardware. With efficient runtimes and quantization, Raspberry Pi devices can support local AI inference without GPUs or accelerators.
Q. What are the main use cases for AI on Raspberry Pi?
Common use cases include offline document summarization, local assistants, edge diagnostics, embedded decision-support systems, privacy-first AI tools, and on-device monitoring or analysis.
Q. Why is architecture more important than model size for edge AI?
Large models often fail on edge devices due to memory and latency constraints. Efficient architectures, controlled reasoning depth, and memory governance determine real-world reliability more than parameter count alone.









