
OpenAI launched GPT-5 in August 2025. It is the newest flagship generative model in the GPT versions.
GPT-5 replaces earlier generative models: GPT-4, GPT-4o, o3, and “mini” versions. Where users previously had to select one of many models, now users ultimately choose “GPT-5,” and the system computes and determines whether quick or in-depth reasoning is required for the task.
In this case study, we evaluate:
- New features in GPT-5
- How it was tested and benchmarked
- The results: strengths & weaknesses
- What this means for companies and developers
Challenges / Problem Statement
Before GPT-5, users and developers had a number of problems:
1. Multiple Models, Confusing
With GPT-4, GPT-4o, GPT-4 mini, o3, etc., users often struggled to distinguish the “right” model to utilise for speed vs depth in Chatgpt.
2. Trade-offs Between Speed and Quality
Sometimes, quick responses meant less deep reasoning; high reasoning meant more latency. This made it hard to balance real-world needs.
3. Benchmarks and Practical Trustworthiness
The last few language models have had deficits in succeeding on various tasks such as code generation, multimodality (text + image), medical/scientific reasoning, etc. In the prior models, errors were often hallucinated or there was fabrication of inaccuracies based on formatting and/or more complicated prompting.
Solution: What OpenAI did with GPT-5?
OpenAI has designed GPT-5 to fix these problems. Major new features and design choices include:

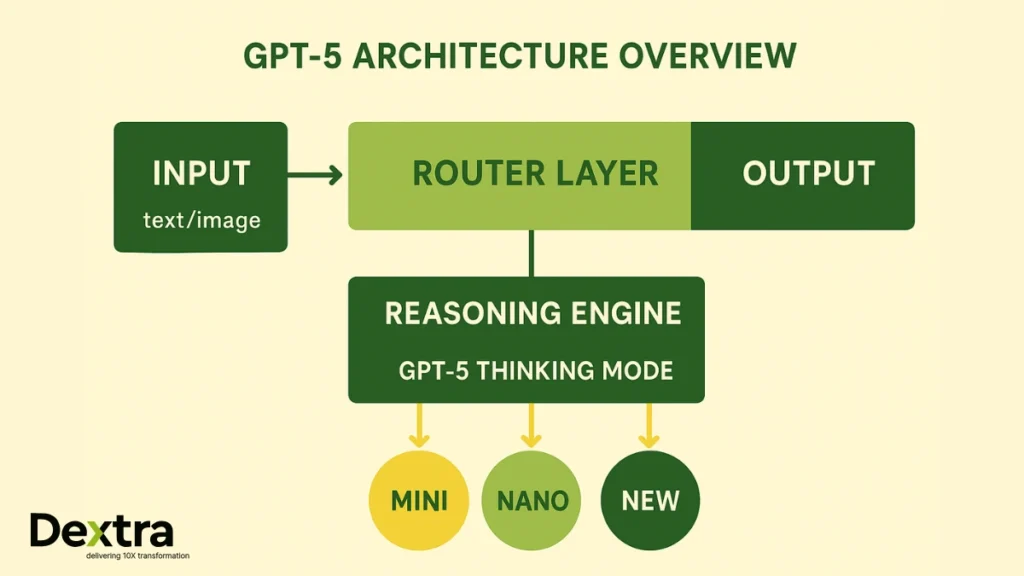
Unified Model Architecture with Intelligent Task Routing
Rather than have many different models, GPT-5 uses a router model that signifies in real-time whether your prompt needs a slow, deep, reasoned answer, or a quick, light response. The smart part allows you to direct the model to employ “GPT-5 Thinking,” if you want more thorough work.
New Parameters for Control
Developers can use parameters like reasoning_effort (minimal, low, medium, high) to control the effort and reasoning the model puts into it, and the related verbosity parameter (low, medium, high) to control the response’s verbosity.
Model Variants for Cost/Speed Trade-offs
Beyond GPT-5, there are GP-5 mini or GP-5 nano, with these frameworks, you should be able to select what works best for you in terms of cost, speed, and resource choices.
Stronger Multimodal Reasoning and Tool Use
GPT-5 works better because it has cognitive capabilities for both text and image input, and it can execute longer chains of tool calls while holding context over more tokens. This means it will work better for mixed content (text + image) and more complicated workflows.
Tests & Benchmarks
OpenAI and other researchers conducted numerous assessments to determine GPT-5 performance. Areas of testing include:
| Test Area | What was measured | Results / Findings |
|---|---|---|
| Coding Benchmarks | Benchmarks such as SWE-bench Verified, Aider Polyglot, etc. | GPT-5 scored highly: ~74.9% on SWE-bench Verified; ~88% on Aider Polyglot. It outperformed prior models on many coding tasks. |
| Biomedical / Medical Reasoning | Performance on medical exams, multimodal question answering, integrated image + text, etc. | On multiple medical reasoning benchmark tests, GPT-5 excelled beyond GPT-4 and others. In one study, on MedXpertQA (text + multimodal), reasoning and understanding improved by ~29-36%. |
| NLP Tasks | Named entity recognition, relation extraction, summarisation, classification, etc, in BioNLP / other domains | GPT-5 showed strong performance, beating GPT-4 / GPT-4o in many circumstances. But there are select tasks (e.g., summarising very dense documents or extraction in rare domains) where performance lagged behind domain-specific models. |
| Context Length / Memory | How many tokens of prior content the model can “remember” in a series of chats or documents | GPT-5 supports longer context window options, so it can deal with longer documents or conversations without losing track. However, limits are applicable and determined by the plan/variant. |
Results: Strengths & Limitations
From the testing we performed, here are the things that GPT-5 does well, and where it has some room to improve.
Strengths
- A better trade-off between speed and accuracy: With the router and the parameters, it is possible to have faster answers when needed and deeper when needed.
- Better code generation and debugging: It can perform real code tasks more effectively, identify more issues, and handle larger codebases better.
- Strong multimodal reasoning: It integrates vision + language more smoothly. It performs well with mixed tasks.
- Good in medical/scientific reasoning: Tests show it outperforms previous models on many of the medical QA benchmarks. That suggests real potential in domains where precision matters.
- Flexibility for different user needs: Mini/nano versions, adjustable reasoning, and verbosity mean that this can be used even for users with limited resources.
Limitations
- Still not perfect in extraction/summarisation for very dense or specialised documents: Some NLP tasks connected to domain-specificity still perform better with fine-tuned models.
- Model size/cost trade-offs matter: Full model may just increase compute/cost; lighter versions have limitations.
- Hallucination / factual errors: Although improved, the risk of false or misleading outputs remains, especially in high-stakes / niche areas.
- Memory in terms of long-term conversation / personal context: While context windows are bigger, GPT-5 does not “truly” remember beyond a session in all variants.
What This Means to Businesses & Developers (Dextralabs-Style Insights)
For companies, organisations, startups, and developers, here’s how the advancements in GPT-5 can transition to value creation.
Quicker development cycles & more dependable automation
Better code definition and debugging mean tasks that might have taken numerous iterations can be done more quickly. Internal agents or workflows can be more ambitious.
Providing smarter tools with vision + text
If your product needs to understand images, charts, and scanned documents (medical, insurance, compliance), GPT-5 provides you with a better foundation.
Lower costs with variations of models
Not all tasks need the best model on the market. Mini or nano versions can perform a multitude of tasks at a lower cost, which aids scaling.
Greater control over the style of output & depth
You can choose between a summary, a detailed readout or a fast response. It provides meaningful customisation of the tools and support for different users (i.e. executive summary vs technical deep-dive).
Risk management remains important
Because there may be errors or hallucinations on various tasks, we recommend that any systems built in GP-5 in any area that is critical (e.g. healthcare, compliance, and/or finance) employ checks on critical outputs, for example, human verification, a contrived feedback loop, and/or domain-specific fine-tuning.
Takeaways & Recommendations
All in all, GPT-5 represents notable progress; there is a more holistic unified model, improved performance on task outputs, controllability, and also better multimodal capabilities. For many use cases, it will reduce friction and likely increase productivity.
Here are some takeaways for utilising GPT-5 in your projects:
1. Select the correct variant
Consider whether you need full GPT-5 or whether a mini/nano version is sufficient. For less critical use cases, you should feel free to think about using lighter versions.
2. Use reasoning efforts/verbosity wisely
If getting fast completion times is critical, set the reasoning effort to low/medium. If you’re working on complex tasks, settle for high effort. The same should be done for verbosity.
3. Combine with domain retrieval /-specific data
If you’re working on something in the healthcare industry or potentially law enforcement, combine GPT-5 with reference materials or fine-tuned data to avoid hallucinations.
4. Test thoroughly in your domain
Test extensively for your applications prior to rolling out, and ensure you benchmark on your own domain data. The academic results are promising, but every domain has quirks.
5. Monitor and include human oversight
Especially for critical outputs, a human check is important. Think of the model as an assistant instead of a fully autonomous system in sensitive areas.
Why Dextralabs Trusts Models Like GPT-5 (Experience & Expertise)
At Dextralabs, we believe tools like GPT-5 can make a genuine impact. Below are our experiences building agentic systems (for use in FinTech, scientific research, compliance, etc) that underscore the same lessons:
- Clarity in requirements early leads to no surprises later – knowing moments of depth, speed and types of input all help shape which model variant to deploy.
- When designing systems, you need to build not just technical quality, but also trust – users need to know what to rely on and where to intervene.
- Architectural & tooling refinements around the model that can matter: prompt design, error handling, chaining tools, context management – these are not “nice to haves”, these make a difference in quality.
Conclusion
GPT-5 represents a range of improvements: common model behaviour, adjustable reasoning & verbosity, improved performance on code & medical benchmarks, a better combination of vision + text, and more flexible cost/latency trade-offs.
But it isn’t flawless. For high-risk tasks, domain-specific tasks, or highly dense informational tasks, there are still some gaps. The key is to use GPT-5 safely: use the right model variant, build the right surroundings and pipelines, keep humans in the loop, and benchmark in your task or surroundings.
For companies like Dextralabs (or clients working with us), this means that we can now build more ambitious AI agents, better tools, and systems that better meet real needs. If you are considering using GPT-5 in a product, service, or workflow, this is the right time to do so, as it can provide you with gains – as long as you consider how to architect around its strengths and limitations.



