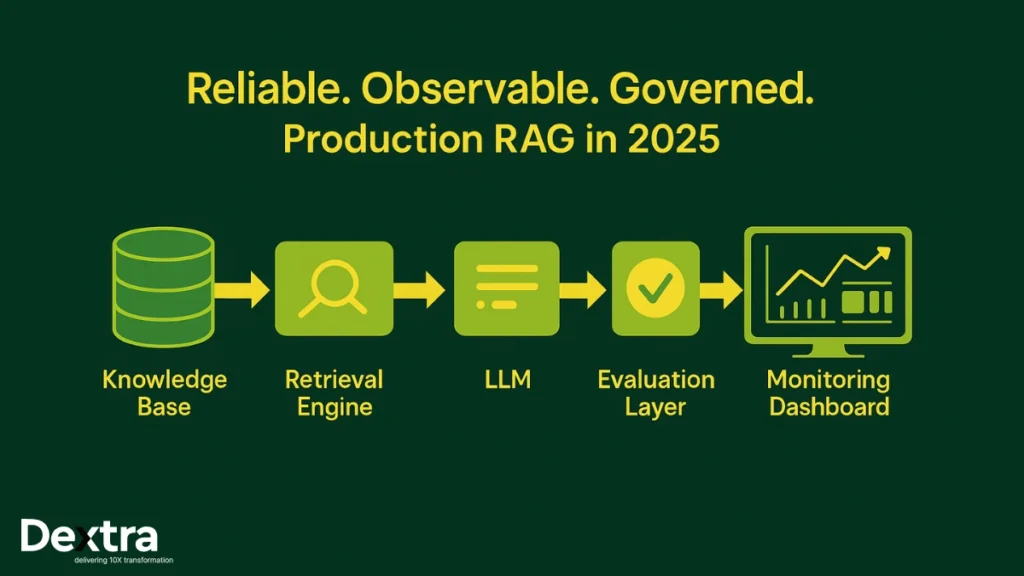
It’s 2025, yet the majority of enterprise AI projects are still using demo-grade RAG instead of the reliable, solid systems that businesses need for daily operations. Despite 88% of organizations now reporting regular AI use in at least one business function (McKinsey, 2025), only a small fraction have truly production-ready systems. The difference between a promising prototype and a true production system is vast—and in high-stakes environments, that gulf can mean the difference between delivering business value and undermining user trust.
As an AI Consulting firm, Dextralabs has helped hundreds of organizations bridge this divide, supporting enterprises across the USA, UK, UAE, India, and Singapore. The secret? Recognizing early success with production RAG 2025 demands far more than “better retrieval.” It’s about consistent reliability, granular safety controls, and enterprise-grade governance.
This article delivers a technical, actionable path for achieving a credible enterprise RAG deployment. It will also guide about its evaluation suites, automated CI/CD quality gates, and end-to-end AI observability for RAG systems—while keeping the conversation practical, not just theoretical. Whether you’re a CTO, AI architect, MLOps engineer, enterprise developer, or product leader, the details here are designed to take you beyond platitudes and straight into actionable strategy.

What is RAG in the Enterprise Context?
If you’re considering RAG systems 2025 for your organization, you already know the promise: combining state-of-the-art LLMs with your organization’s proprietary knowledge base for dramatically improved factuality and context. But when you move from concept to enterprise-scale application, the theoretical promise of retrieval-augmented generation best practices meets a world of engineering, governance, and operational realities.
Key Technical Elements of RAG in 2025:
- Retrieval Model: Modern stacks require low-latency semantic search across diverse formats (PDFs, emails, structured records); compliance and access-control filters are applied pre- and post-retrieval for regulatory integrity.
- LLM Response Synthesis: The LLM must interpret context windows that can change dynamically, filter out irrelevant or unauthorized data, and generate answers that map to internal data schemas or API contracts.
- Indexing Complexity: Today’s enterprise RAG implementation often means handling billions of documents, near-real-time indexing for streaming data, and document re-chunking as knowledge sources evolve.
- Observability and Auditability: Every retrieval, ranking, and generation carries audit trails to satisfy internal audit, regulatory, and user trust requirements.
Why Does This Architecture Matters?
- Factual Accuracy: If your LLM fails to use the current policy document or misses nuance in compliance guidelines, you could expose your business to real risk—legal, operational, or reputational. According to ISG’s State of Enterprise AI Adoption Report (2025), only 31% of AI initiatives reach full production, even as organizations scale pilots across business units (ISG, 2025). This production gap highlights why structured evaluation and observability aren’t optional—they’re foundational to achieving reliability at scale.
- Contextual Relevance: In a global supply chain or multimodal enterprise, the “right answer” depends on region, workflow, and user. RAG lets you encode these dependencies using programmable context.
- Cost Efficiency: Retraining LLMs is cost-prohibitive for most organizations. By leveraging RAG, you ensure the generative component uses up-to-date source material without constant (and expensive) model retraining.
Dextralabs’ Approach to Enterprise RAG Architecture

Our enterprise RAG architecture is founded on three technical pillars:
- Reliable Knowledge Retrieval:
- Hybrid Search: Combine dense vector (semantic search), sparse (keyword/BM25/TF-IDF), and graph-based traversal for high recall and relevance. For compliance, integrate filtering (PII/PHI detection) before retrieval.
- Enterprise Security: Integrate attribute-based access control at the query and document level, maintaining separation of duties and permissioned data throughout the retrieval process.
- 2. Context-Aware Response Synthesis:
- Dynamic Windowing: Smartly allocate token budget: automatically compress less relevant supporting docs, rerank based on business logic (e.g., regulatory docs over wikis), and use response templates where required.
- Audit-Friendly Generation: All context/input IDs and output/confidence scores are logged per-request, offering downstream traceability essential for regulated industries like finance and health.
- 3. Real-Time Monitoring & Evaluation:
- Per-Query Observability: Every retrieval, every LLM token, every user feedback event is logged. Metrics are continuously reported on dashboards and SLOs, with alerts if drift or anomalies are detected.
Also Read: Agentic AI Maturity Model 2025
The RAG Production Journey: From Prototype to Deployment
Transitioning from a Jupyter proof-of-concept to a mission-critical application involves far more than integrating a vector search with GPT. The process requires following retrieval-augmented generation best practices, from versioned data and evaluation pipelines to observability and CI/CD quality gates.

Let’s break down the phases and their core technical requirements.
Stage 1: Prototyping
- Goal: Validate feasibility for your workflow/business unit.
- Tactics:
- Use local stores (FAISS, ChromaDB) for embeddings.
- Tune queries; test prompt formats; integrate a handful of domain-specific documents.
- Technical Advice:
- Version even your test data; many teams waste days tracking mysterious regressions traced to untracked input changes.
Stage 2: Evaluation
- Goal: Quantitatively characterize strengths and weaknesses.
- Tactics:
- Assemble “golden” QA datasets (real-world queries + ideal answers).
- Establish automated evaluation pipelines—using an LLM-as-a-judge or traditional heuristics for exact-match/fuzzy scoring.
- Common Tools:
- Ragas, Trulens, LangChain evaluation, custom scripts for edge-case detection.
- Key Insight:
- Data diversity matters: coverage should span core use cases and intentionally difficult examples (ambiguous queries, conflicting sources).
Stage 3: Integration
- Goal: Connect RAG to the real world—APIs, internal apps, CRMs, and even customer-facing chatbots.
- Tactics:
- Use robust APIs (FastAPI, REST/gRPC), enforce strict authentication (JWT/OAuth), and hook into internal event and alerting systems.
- Map LLM responses into business objects or ticketing systems; auto-trigger human review for low confidence answers.
Stage 4: Observability & Scaling
- Goal: Achieve “set-and-forget” resilience.
- Tactics:
- Instrument real-time dashboards for AI pipeline monitoring, showing per-query latency, success/failure, accuracy, and hallucination rates.
- Deploy drift detection: when query distributions or source data change, raise alerts.
- Schedule automated retraining or re-indexing based on content update frequency.
- Integrate user feedback loops for continuous improvement, and surface metrics in business reporting tools.
Also Read: Best LLM leaderboard in 2025
Building a Robust LLM Evaluation Suites: Laying the Foundation of Trust
A solid LLM evaluation suite is the only way to move from wishful thinking to a production RAG pipeline you can trust. Modern LLM evaluation suites go far beyond simple precision/recall scores—they include automated checks for retrieval quality, hallucination rates, and latency under real-world load.
Evaluation Dimensions
A well-designed LLM evaluation suite should measure these dimensions continuously, ensuring that retrieval, synthesis, and generation stay reliable across time and data changes.
- Context Recall: Can you prove the RAG engine found all key relevant docs for tough queries? Use automatic recall scoring and manual audits for difficult/ambiguous queries.
- Context Precision: Is the retrieved content actually useful, or did it fill the window with tangential noise? Track relevance metrics using both LLMs and human feedback.
- Faithfulness & Consistency: Is every generative answer strictly grounded in the retrieved context? Use sentence-level comparisons, and score for “copy-paste” alignment when necessary (think: legal or scientific answers).
- Latency & Performance: Is your system responsive (<1s for 95% of queries) at scale? Instrument detailed timing (ingestion, retrieval, LLM generation, post-processing).
Actionable Practices
- Test Harness in CI: Run representative and edge-case queries every pull request. Fail the build if faithfulness, recall, or latency SLOs drop below thresholds. Integrate these tests directly into your LLM evaluation suite so results flow into your CI dashboards, making model regressions immediately visible.
- LLM-as-a-Judge: For ambiguous answers (e.g., summarization, complex Q&A), a secondary LLM can compare model outputs to gold standards with explainable failure reasons.
- Edge-Case Sampling: Routinely sample production traffic for new edge cases and add to your eval set.
- Metric Tracking Over Time: Store results in time-series DBs; regression in any dimension triggers an alert and investigation.
Also Read: From Copilots to AI Co-Workers: How Organizations Are Orchestrating Multi-Agent Workflows
What are CI/CD Pipelines for RAG Systems?
Discipline in AI deployment workflows is what allows enterprise RAG implementation to withstand real-world stress. Traditional dev pipelines aren’t enough—CI/CD for AI must gate on metrics, not just code syntax.

Essential CI/CD for AI Quality Gates for Production RAG
In a mature CI/CD for AI environment, every release of your RAG pipeline passes through automated gates that measure retrieval accuracy, faithfulness, and latency before it reaches production.
- Validation of Embeddings and Indexes:
- Pipeline Step: Validate data for duplicates, missing indexes, and malformed embeddings before indexing.
- Tools/Tech: DVC for versioned data, custom validation scripts, OpenAI/transformers models to check embed quality.
- Impact: Prevents silent failures; ensures only high-integrity knowledge enters search.
- Accuracy Thresholds and Metric Blocks:
- Pipeline Step: Run every release against curated golden sets as part of your AI deployment quality gates. Block merges automatically if faithfulness, recall, or latency deviates beyond defined thresholds.
- Tools/Tech: MLflow for experiment tracking, Ragas for eval, custom CI test runners.
- Impact: Prevents degradation, increases trust.
- Automated Rollbacks and Canary Deployments:
- Pipeline Step: Real-time metric or feedback anomalies (spike in hallucinations, drop in user ratings) can trigger auto-revert.
- Tools/Tech: GitHub Actions, custom scripts, flagged production endpoints.
- Impact: Blast radius limited—value and safety preserved.
- Continuous Retraining and Index Refresh:
- Pipeline Step: Scheduled (weekly/monthly) re-evaluation of underlying data, with auto-retriggered pipelines if new docs or schema changes are detected—fully automated through your CI/CD for AI workflow to ensure continuous freshness and reliability.
- Tools/Tech: MLflow, data freshness monitoring, vector DB auto-refresh.
Technology Stack Example
- Pipeline Orchestration: GitHub Actions, Jenkins, or Dagster.
- Experiment Tracking: MLflow.
- Audit & Version Control: DVC, Git.
- Automated Evaluation: Ragas, Trulens, and Dextralabs EvalOps libraries.
Also Read: Why Your AI Strategy Isn’t Delivering ROI
Observability: The Non-Negotiable for Production RAG
You can’t fix what you can’t see. AI observability is about making every part of your RAG pipeline legible, tractable, and actionable in real time. For modern AI pipeline monitoring, dashboarding and alerting are not optional.
Key Observability Metrics
- Retrieval Latency: End-to-end and per-engine (vector, keyword, graph, hybrid).
- Relevance/Recall Score: Percentage of queries where the retrieved context matches labeled gold answer.
- Response Drift Detection: Automated n-gram, length, or embedding-space drift measurement. Alerts on unexpected stylistic or thematic output changes.
- Hallucination Frequency: Running LLM-graded faithfulness checks (on N% of queries).
- Human Feedback Loop Score: User thumbs (up/down), “was this helpful” ratings, merged with answer accuracy for system-level NPS tracking.
- System Health: Monitoring for ingestion errors, index corruption, or security audit triggers.
Dextralabs Implementation
- Dashboards: Built with tools like LangSmith, Grafana, Arize or custom visualizations tied to OpenTelemetry.
- Alerting: SLO breaches = immediate Slack/Teams alert, auto-ticket generation for engineering, and business-impact analysis for managers.
- Traceability: Query-to-answer traces, with all intermediate retrievals, context slices, LLM calls, and scoring.
The Maturity Journey for Production RAG Systems 2025
Have a look at the maturity journey for production RAG systems 2025:
| Stage | Key Activities | Tools / Best Practices | Pitfalls to Avoid |
| Prototyping | Local embedding, static docs, exploratory prompts | FAISS, OpenAI API, DVC | No versioning, manual tests, lack of trace |
| Evaluation | Test queries, LLM judge, hallucination checks | Ragas, custom graders, CI runners | Unbalanced datasets, ignored edge cases |
| Integration | API/ERP/CRM bridge, auth, feedback infra | FastAPI, MLflow, ZTA, audit logs | Weak permissions, missing logs |
| Observability & Scaling | Dashboards, drift, retraining, SLO/ROI review | LangSmith, Grafana, Dextralabs EvalOps, OTEL | Drifting KPIs, missed retrain, no rollback |
What are the Common RAG Pitfalls (and How to Avoid Them)?
Avoiding rookie mistakes takes a seasoned engineering playbook. Here’s how Dextralabs neutralizes common RAG issues:
- Context Window Overflow: If you push too much text into the LLM (often due to naive “max context” strategies), the model may overlook critical facts or hallucinate.
- Our Solution: Dynamic prioritization and context filtering with reranking, so only high-value chunks consume tokens.
- Poor Document Chunking: Arbitrary splitting disrupts semantic meaning; query/answer alignment suffers.
- Our Solution: Use recursive chunking with sentence boundary detection and redundancy for optimal retrieval.
- No Version Control: Impossible to diagnose regressions or explain outputs post-hoc.
- Our Solution: Aggressive versioning and lineage for every model, dataset, prompt, and index: full reproducibility is mandatory.
- No Real-Time Evaluation: Static eval sets cannot catch real-world distribution shifts.
- Our Solution: Live “EvalOps” pipelines integrated into monitoring; flag, sample, and quickly retrain on negative production trends.
Business KPIs: Connecting Technical and Strategic Success
A 2025 Enterprise AI Adoption Survey found that enterprises with a formal AI strategy are more than twice as likely to succeed (80% vs. 37%) (Writer.com, 2025). This reinforces why Dextralabs’ RAG governance and KPI frameworks are not just operational necessities; they’re strategic enablers of enterprise-wide success. Your enterprise RAG implementation only thrives if the boardroom sees evidence of value.
- Efficiency KPIs:
- Time Saved per Query: Track reductions across support, research, or compliance workflows.
- Retrieval Success Rate: Monitor how often queries are resolved end-to-end without escalation.
- Accuracy KPIs:
- Factual Precision Score: Human/LLM audits validate answers.
- Response Consistency: Same query, same (correct) output over time.
- Operational KPIs:
- Uptime/Availability: SLOs at 99.9%+ for critical flows.
- Cost per Inference: Tie infra and licensing back to real usage.
- ROI KPIs:
- Cost Reduction: Before/after studies vs. manual knowledge work.
- Accuracy vs. Scaling Costs: Does expansion penalize precision?
Dextralabs Insight:
“Our enterprise RAG deployments are benchmarked across 25+ KPIs—mapping technical precision directly to business ROI.” – CTO Dextralabs
These KPIs are surfaced in dashboards and C-suite management briefings, ensuring sustained support and demonstrating RAG business impact and the power of enterprise AI KPIs.
Dextralabs’ Beyond-RAG Implementation Framework
Ready for scalable, governed, and future-proof RAG? Here’s the four-tier framework Dextralabs delivers in every aggressive enterprise RAG solution project:
- Data Engineering & Indexing:
- Custom pipelines for ingesting, chunking, and hybrid indexing documents—scalable to tens of millions of docs. Preprocessors for cleansing, de-duplication, and filtering sensitive data.
- Support for multi-lingual and multimodal sources, ensuring global-scale applicability.
- Retrieval Optimization (Hybrid + Contextual):
- Algorithmic blending of semantic, keyword, and graph search.
- Context prioritization and real-time reconfiguration for workflow context (sales, support, engineering, etc.).
- Built-in policies for permissions and document freshness.
- Automated Evaluation Loops:
- Plug-and-play modules that execute EvalOps on every change: new docs, new models, or code updates.
- Integration with both CI/CD (pre-production) and live traffic (post-upgrade), ensuring alignment and rapid issue detection.
- Observability & Governance Layer:
- Real-time monitoring dashboards, audit trails, and alerting. Reports for compliance and external regulators, secure by default and cloud-agnostic (AWS, Azure, GCP).
Real-World Application
Dextralabs has implemented these frameworks across finance (automated policy Q&A, fraud detection), manufacturing (line troubleshooting, standards compliance), and government (regulatory helpdesks, public-access document synthesis), always with measured risk controls and seamless cloud integration.
Call to Action (CTA)
Is your organization still running on “prototype” RAG, but staking critical outcomes on these systems? Don’t let a demo bottleneck your business.
Dextralabs partners with enterprises to deliver reliable, monitored, and compliant RAG deployments—engineered for scale, security, and measurable business value. We’ll benchmark, blueprint, deploy, and operate your production RAG so you can focus on unlocking the full promise of AI.
Connect with Dextralabs AI experts and assess your RAG production readiness. Together, we’ll take your LLM from concept to world-class solution.
FAQs on Production RAG:
Q. What is a RAG system in production?
A production RAG system is a retrieval-augmented generation pipeline that has moved beyond demos and POCs. Instead of static prompts and local embeddings, it runs on evaluated, monitored, and governed retrieval workflows. In production, a RAG system must ensure:
– consistent retrieval relevance
– factual accuracy
– low latency
– real-time drift detection
– observability and feedback loops
Enterprises rely on production RAG to answer business-critical queries with reliability, not just “AI-assisted guesses.”
Q. What is a RAG system used for in enterprises?
RAG systems help organizations deliver accurate, context-aware answers grounded in their internal knowledge. Typical use cases include:
– customer support automation
– enterprise search
– sales enablement
– policy/document querying
– internal knowledge copilots
– compliance assistants
Essentially, RAG is used wherever factual precision and domain awareness matter.
Q. How do you deploy a RAG system in production?
Deploying RAG in production means following a disciplined engineering workflow:
1. Data Engineering & Indexing
2. Hybrid Retrieval Optimization
3. Evaluation Suite Setup (recall, precision, hallucination tests)
4. CI/CD Quality Gates
5. Monitoring & Observability Layer
6. Continuous Feedback & Retraining
Dextralabs follows a Beyond-RAG™ framework where reliability, governance, and automated evaluation are built into every deployment.
Q. What are the four types of production systems in AI?
In enterprise AI, production systems generally fall into four categories:
1. Rule-based Systems – deterministic logic, no learning
2. ML Model Serving Systems – classifiers, regressors, embeddings
3. LLM/Prompt-based Systems – instruction following, generation
4. RAG/Agentic Pipelines – retrieval + generation + evaluation + monitoring
Most enterprises in 2025 are migrating from standalone LLMs to RAG or agentic systems for better accuracy and governance.
Q. What is the 30% rule in AI?
The 30% rule suggests that AI should automate at least 30% of a workflow to create meaningful ROI. Anything less typically results in:
– marginal cost reduction
– heavy human-in-the-loop dependence
– weak productivity impact
For RAG specifically, hitting the 30% threshold usually happens when organizations add evaluation, observability, and workflow integration, not just chat-like interfaces.
Q. What are the four pillars of observability in AI?
AI observability expands the classic DevOps pillars to include model-specific signals:
1. Logs – system activity, routing, errors
2. Metrics – latency, retrieval scores, cost per query
3. Traces – full request journey across retriever → LLM → evaluation
4. Drift & Quality Signals – hallucination frequency, context mismatch, response deviation
In enterprise RAG deployments, the fourth pillar is crucial — without quality signals, hallucinations go undetected.
Q. What are the four types of AI systems?
AI systems are broadly categorized into:
1. Reactive AI – no memory, responds to current input
2. Limited Memory AI – ML models, LLMs, most modern systems
3. Theory of Mind AI (future) – contextual understanding of humans
4. Self-Aware AI (theoretical) – consciousness-level reasoning
Most enterprise systems today operate at Level 2, enhanced by RAG pipelines for better factual grounding.
Q. What is GenAI observability?
GenAI observability refers to the continuous monitoring of generative AI systems across both retrieval and generation layers. It answers critical questions:
– Is the model hallucinating?
– Are retrievals relevant?
– Is the system drifting from expected behavior?
– Are outputs compliant with business rules?
Enterprise GenAI observability combines metrics, quality checks, human feedback, and automated evaluation — all essential for safe scaling.







