In 2025, we’re witnessing an accelerating shift from generic GPT APIs to highly personalized large language models (LLMs). Enterprises want more control, greater privacy, and tailored performance, and that’s pushing a surge in custom LLM implementation.
According to McKinsey (2024), 56% of AI-first companies are now adopting custom LLMs. At Dextralabs, we specialize in helping companies build, fine-tune, and deploy scalable custom LLMs. This guide is for tech teams ready to go from MVPs to scalable production systems, especially founders, CTOs, AI engineers, and DevOps specialists.

💡 Still Relying on Traditional Dev Workflows?
Discover how LLMs can automate, optimize, and scale your engineering team—without replacing them.
Book a Free AI ConsultationThe Prototyping Phase: Laying the Foundation
Every successful custom LLM implementation begins with a well-planned prototype. This phase enables you to verify concepts, evaluate viability, and match the design of your AI model with actual business requirements. It establishes the foundation for AI that is ready for production, from picking the best use case to selecting an adaptable framework.

a. Defining the Use Case
Before writing code, define what you want your LLM to do:
- Legal assistant: Summarize contracts and suggest revisions.
- Medical chatbot: Provide triage based on symptoms.
- Code copilot: Auto-complete functions using internal repositories.
Clearly identifying the use case helps you match model capability with task complexity. Poorly defined goals are the #1 reason why prototypes fail, according to the State of AI Development Report (2023).
b. Choosing the Right LLM Framework
Frameworks simplify the LLM implementation process and give structure to your MVP.
| Framework | Best Use Case | Unique Value |
| LangChain | Modular pipelines | LangChain custom LLM endpoint support |
| CrewAI | Multi-agent systems | CrewAI custom LLM orchestration |
| Haystack | Document Q&A, RAG | Easy integration with Elasticsearch |
| LlamaIndex | Data connectors + RAG | Light and customizable |
LangChain custom LLM example: Use LLMChain to simulate a structured legal Q&A process.
CrewAI: Useful when your application involves agents with different roles (e.g., researcher, summarizer, and reviewer).
c. Building an MVP (with Examples)
Leverage GPT APIs for fast iteration. MVPs typically include:
- Prompt engineering using few-shot learning
- Chain building with LangChain
- Early logic testing with FastAPI or notebooks
Pro tip: Use the LangChain custom LLM API with mocked endpoints to test pipelines. You can explore multiple custom LLM implementation GitHub repositories for inspiration.
From Prototype to Custom LLM: Making the Shift
Moving from AI prototyping to a full-scale custom LLM implementation is a pivotal step in the AI development lifecycle. This stage is where organizations graduate from MVPs built with APIs to robust, production-ready AI systems. Here, customization becomes essential to unlock performance, scalability, and compliance benefits.
Why Move to a Custom Model?
While prototyping with GPT APIs is quick, moving to a custom LLM offers:
- Better performance for domain-specific tasks
- Privacy and compliance with data regulations
- Reduced hallucinations and higher reliability
- Scalability with predictable costs
Custom LLM implementation enables deeper control over output generation, ensuring that models perform in line with company expectations.
Model Selection & Pretraining Considerations
Choose from leading open-source models:
| Model | Parameter Size | Ideal For | License |
| LLaMA 3 | 8B to 65B | General purpose | Meta (custom) |
| Mistral 7B | 7B | Lightweight fine-tuning | Apache 2.0 |
| Falcon | 40B to 180B | Conversational agents | Permissive |
You can also build LLM from scratch in Python using HuggingFace Transformers:
from transformers import GPT2Tokenizer, GPT2LMHeadModel
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
inputs = tokenizer("Hello, world!", return_tensors="pt")
outputs = model(**inputs)
Custom Training Pipelines
Building a robust training pipeline involves:
- Tokenization (using SentencePiece or HuggingFace)
- Dataset formatting (JSONL format with instruction pairs)
- Fine-tuning LLMs using LoRA or full-model training
Evaluation metrics:
- BLEU/ROUGE for summarization
- Perplexity for fluency
- Exact Match / F1 for QA systems
Tools like Weights & Biases and MLflow can help track experiments. Refer to Custom LLM implementation PDF resources or GitHub examples for reproducible pipelines.
Infrastructure Setup for Production-Ready AI
It’s time to consider delivering your customized model to users in the real world after you’ve optimized and assessed it. In order to make your optimized LLM scalable, dependable, and secure, infrastructure is essential. The essential elements of a production-ready AI stack are covered in this section, including observability, API management, and backend hosting.
A. Scalable Backend & Model Hosting
For hosting your model:
- Self-hosting with NVIDIA A100s (on-prem or Paperspace)
- Cloud options: AWS SageMaker, GCP Vertex AI
Production AI stack tip: Use containerization (Docker) + orchestration (Kubernetes) for elasticity.
B. API Serving and Routing
Use REST or gRPC to expose endpoints.
- Implement LangChain custom LLM endpoints for integration
- Enable load balancing and canary releases
Use NGINX or Istio to manage traffic routing and retries.
C. Observability & Monitoring
Essential for production-ready AI:
- Log token usage and latency
- Visualize metrics in Grafana or LangSmith
- Build feedback loops using Vectorstore integration
Set alerts for error spikes and usage anomalies.
DevOps & MLOps Best Practices for LLM Deployment
DevOps and MLOps procedures make sure that everything functions properly, updates consistently, and scales with ease after your model is hosted and your APIs are operational. Maintaining high availability, ongoing development, and protecting your LLM from failures all depend on this phase.
Skip the Guesswork. Build Custom LLMs with Experts
Turn your prototype into production-ready AI with Dextralabs.
Explore Our Custom AI Implementation Services1. Continuous Integration & Continuous Deployment (CI/CD)
Automate your training-to-deployment workflow using:
- GitHub Actions
- Jenkins pipelines
- MLflow for model tracking and deployment versioning
CI/CD allows you to test new model versions in staging environments before pushing to production.
2. Secrets and Access Management
Manage sensitive information securely:
- Use HashiCorp Vault, AWS Secrets Manager, or GCP Secret Manager
- Restrict access via IAM roles and API gateways
This prevents unauthorized access to model weights, training data, and environment configurations.
3. Auto-scaling & Model Rollbacks
Handle varying workloads with:
- KEDA or Horizontal Pod Autoscaler (HPA) in Kubernetes
- Auto-scaling GPU clusters on cloud platforms
Ensure system resilience with:
- Blue-green deployments
- Model rollback strategies triggered by performance thresholds
4. Observability & Feedback Loops
Use tools like LangSmith or Prometheus + Grafana to monitor:
- Token usage
- Latency per endpoint
- Accuracy trends over time
Enable continuous learning by integrating user feedback into your retraining pipelines.
- Secrets management via Vault or AWS Secrets Manager
- Auto-scaling with KEDA on Kubernetes
- Model rollback strategies for safe deployment
Integrate tools like LangSmith for continuous evaluation.
Case Study Example: How [Company X] Went from Prototype to Scale
This real-world case study demonstrates how an AI-first fintech startup successfully transitioned from an experimental prototype to a scalable, production-ready AI product using a custom LLM implementation.
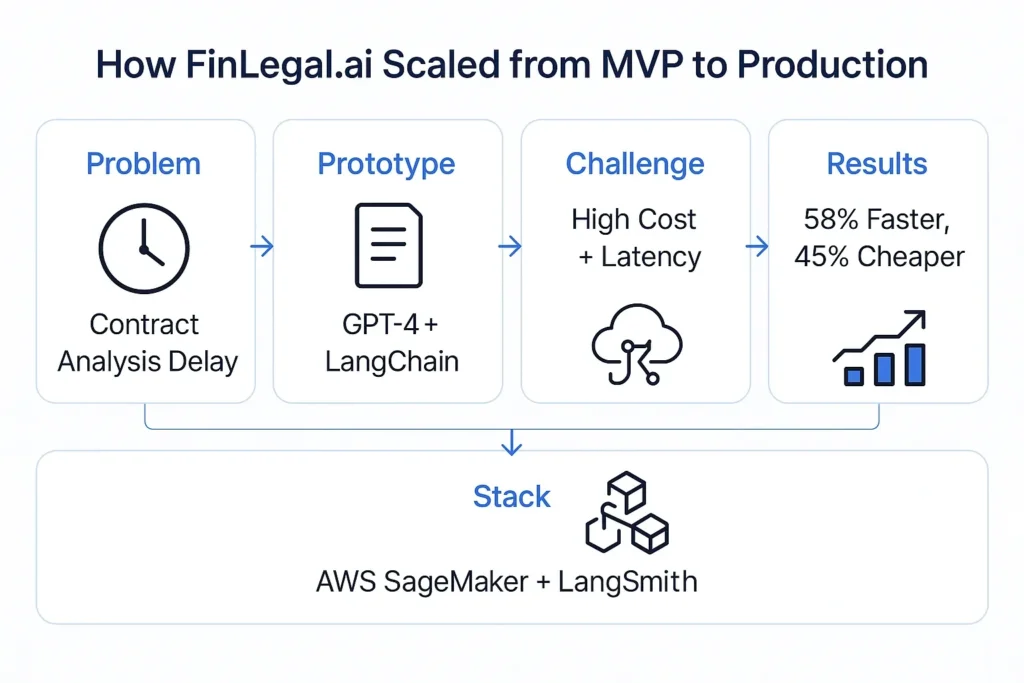
Challenge
FinLegal.ai, a contract analysis SaaS platform, faced mounting delays in reviewing lengthy, repetitive legal documents. Their goal was to build an AI-powered document summarizer that could match the speed and accuracy of legal professionals while maintaining data privacy.
Prototype Phase
They began by creating an MVP using LangChain and GPT-4 API, integrating LangChain chains to structure the prompt-response flow for contract clauses. While the prototype proved effective, API costs and latency raised concerns for long-term scalability.
Transition to Custom LLM
To address these limitations, the team partnered with Dextralabs to build a custom LLM. They selected Mistral 7B, an open-source model ideal for legal summarization, and fine-tuned it on a curated dataset of 40,000+ legal documents using LoRA (Low-Rank Adaptation) techniques.
Production Stack
- Training: HuggingFace Transformers + LoRA
- Framework: LangChain for chaining + CrewAI for multi-agent validation
- Storage & Hosting: AWS S3, AWS SageMaker (auto-scaled endpoint)
- Monitoring: LangSmith for LLM observability + Prometheus for latency
Results
- Time to review reduced by 58% across high-volume clients
- ROUGE score improved by 12% vs baseline GPT output
- Inference latency lowered to 1.2s per document page
- Cost reduced by 45% compared to API-based solution
This journey highlights the practical benefits of custom LLM implementation in production environments where accuracy, performance, and cost efficiency are critical.
- 58% time reduction in document review
- Improved output accuracy (ROUGE score +12%)
Common Pitfalls to Avoid:
Even the most well-planned custom LLM implementation can fail if certain risks are not proactively addressed. Here are the most common pitfalls that teams encounter and how to avoid them:
Overfitting During Fine-Tuning
One of the biggest risks in training custom LLMs is overfitting, especially when the dataset is too narrow or biased. This results in a model that performs well on training data but generalizes poorly in production.
How to avoid it:
- Use a diverse dataset
- Incorporate data augmentation techniques
- Monitor evaluation metrics like perplexity and F1 on a validation set
Ignoring Inference Latency in Production
Latency often becomes a bottleneck when deploying custom LLMs at scale. Slow responses degrade user experience and increase infrastructure costs.
How to avoid it:
- Benchmark models on real-world tasks
- Use quantization or model distillation
- Deploy models on optimized hardware (e.g., NVIDIA A100s, AWS Inferentia)
Security and Compliance Gaps
Without proper data handling protocols, custom LLM deployments can become non-compliant with privacy laws and security standards such as GDPR, HIPAA, or SOC 2.
How to avoid it:
- Implement secure data pipelines with encryption in transit and at rest
- Use role-based access control (RBAC)
- Regularly audit logs and monitor for unauthorized access
For a deeper dive, explore our guide on LLM Deployment Pitfalls and How to Avoid Them.
- Inference latency causing user frustration
- Non-compliance with security frameworks
Future-Proofing Your Custom LLM Stack
As LLM adoption continues to grow, future-proofing your AI stack is essential to remain competitive and ensure long-term sustainability. This means continuously adapting to technological advancements and building a modular architecture that can evolve with your needs.
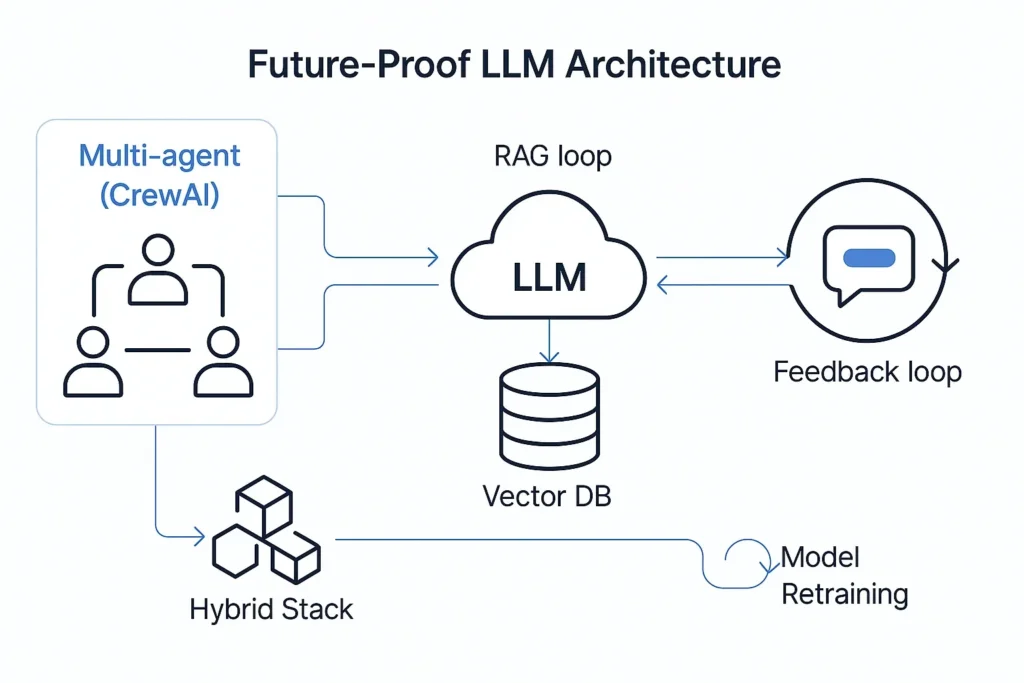
Incorporate Retrieval-Augmented Generation (RAG)
RAG combines LLMs with external knowledge sources like vector databases to produce grounded, factual answers.
Tools to consider:
- LlamaIndex
- Pinecone
- FAISS
RAG helps reduce hallucinations and improves accuracy by referencing up-to-date information during inference.
Adopt Multi-Agent Architectures
Tools like CrewAI custom LLM enable multiple AI agents to work together, mimicking collaborative workflows.
Use Cases:
- Research and summarization agents for publishing
- Planning and execution agents for task automation
This improves task decomposition, parallel processing, and model accountability.
Use a Hybrid LLM Stack
Instead of relying on a single model or provider, combine:
- Open-source models (for control and cost)
- Proprietary APIs (for edge-case coverage)
This gives you the flexibility to swap components, retrain submodules, and diversify your AI risk.
Embrace Versioning and Feedback Loops
Use tools like DVC or MLflow to version:
- Model weights
- Datasets
- Prompts and API configs
Maintain tight feedback loops from production logs to training pipelines to close the improvement cycle.
Conclusion
Custom LLM deployment is no longer an exclusive right of tech behemoths anymore. With the appropriate frameworks, scalable architecture, and a clearly laid out strategy, any tech-savvy organization can transition from MVP to production-quality AI.
No matter whether you are investigating building an LLM from scratch, improving performance by fine-tuning LLMs, or deploying through a LangChain custom LLM endpoint, the door is open.
Need expert guidance?
Book a free consultation with Dextralabs to explore our end-to-end custom LLM solutions from design to deployment.
Building a custom LLM from scratch is now achievable for startups and enterprises alike. The combination of open-source tooling, scalable cloud infra, and MLOps workflows makes it easier than ever to implement a production-ready AI system.
Want expert support? Book a consultation with our AI engineering team.
🚀 Ready to Cut Engineering Costs with AI?
Join Fortune 500 leaders already leveraging LLMs.
Book a Free AI Consultation