When GPT-3 launched in 2020, its 2,048-token context window seemed impressive. Fast forward to 2025, and we’re seeing models that can process millions of tokens without forgetting what came before. The question is no longer whether LLMs can handle long contexts. It’s how they do it with finite memory.
The breakthrough isn’t just bigger context windows. It’s smarter memory systems that compress, retrieve, and maintain information across effectively infinite sequences while using fixed computational resources. At Dextra Labs, we help enterprises and SMEs across the UAE, USA, and Singapore implement these advanced context management techniques in production AI systems.
This isn’t academic curiosity, it’s a production necessity. The difference between an AI that forgets your requirements midway through a conversation and one that maintains perfect context across hours determines whether your AI initiatives succeed or fail.
Also Read: Context Engineering is the New Prompt Engineering
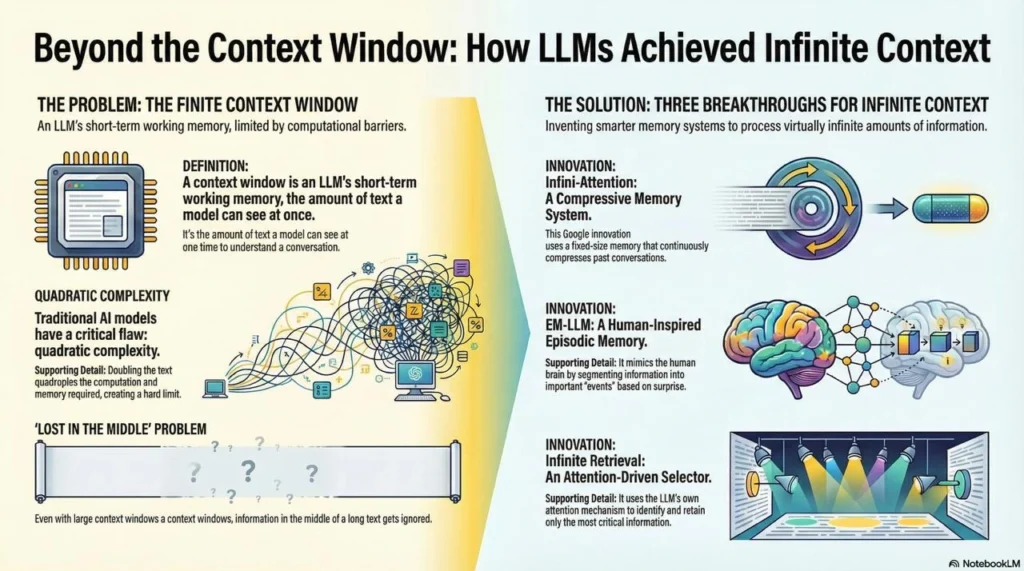
The Context Window Problem: Why Length Matters
Context window (or context length) is the amount of text an LLM can attend to at once. Think of it as the model’s working memory of how much of the conversation or document it can see at any given time.
The Traditional Limitations
Standard Transformer architectures (the foundation of most modern LLMs) suffer from a fundamental problem: quadratic complexity. The computational cost grows dramatically as you increase sequence length. Doubling the tokens quadruples the time and memory needed.
This creates hard limits:
- GPT-3: 2,048 tokens (roughly 1,500 words)
- GPT-3.5: 4,096 tokens
- Early GPT-4: 8,192 tokens
- Claude 2: 100,000 tokens
- Gemini 1.5: 1 million tokens
But raw context window size doesn’t tell the whole story. Research published in Transactions of the Association for Computational Linguistics found that models suffer from the “lost in the middle” problem (Liu et al., 2024).
Also Read: The Art of Context Engineering: And How we Can Unlock True Potential of Large Language Models
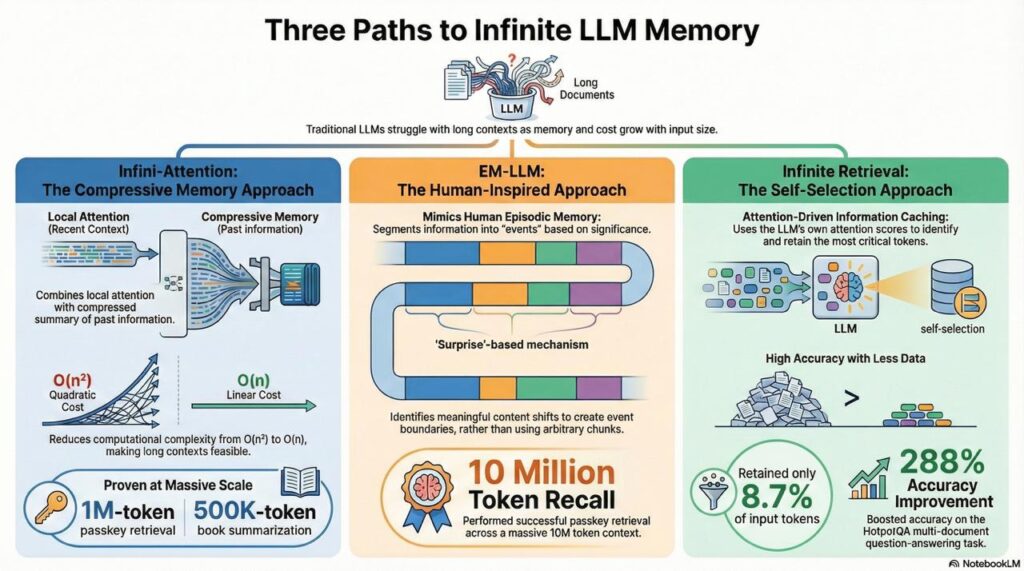
The Infinite Context Breakthrough: Core Innovations
Three major architectural innovations enable LLMs to handle effectively infinite context with finite memory:
1. Infini-Attention: Google’s Compressive Memory
In April 2024, Google Research published “Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention” (arXiv), introducing a mechanism that transforms context handling from finite to boundless.
How Infini-Attention Works?
Traditional attention mechanisms store all key-value pairs from every token, creating memory that grows linearly with input length. Infini-attention introduces compressive memory that maintains a fixed-size representation of unlimited history.
The architecture combines two attention mechanisms:
- Local Masked Attention: Focuses on nearby words in the current segment
- Long-term Linear Attention: Accesses compressed representations of all previous segments
As the model processes new segments, it continually updates a compressed memory state through recurrent updates. This means memory parameters remain bounded even as input grows to millions of tokens.
Proven Performance
Google’s experiments demonstrated remarkable results:
- 1M-length passkey retrieval: Models fine-tuned on just 5K-length sequences successfully solved 1M-token retrieval tasks
- 500K-length book summarization: Achieved state-of-the-art results on the BookSum dataset
- Quadratic to linear complexity: Reduced computational cost from O(n²) to O(n), where n is sequence length
The paper showed that Infini-Transformers even outperform models with full attention on much shorter contexts, proving that the approach not only handles length but also improves comprehension (arXiv).
2. EM-LLM: Human-Inspired Episodic Memory
Published at ICLR 2025, “Human-inspired Episodic Memory for Infinite Context LLMs” (ICLR 2025) takes a different approach: modeling how human memory actually works.
The Cognitive Science Foundation
Human brains don’t store every word we read with equal weight. Instead, we segment experiences into events based on surprise and significance, then retrieve related memories when needed. EM-LLM replicates this cognitive architecture.
The system divides context into three groups:
- Initial tokens: The beginning of the conversation or document
- Evicted tokens: Compressed representations of processed segments
- Local context: The current working window
Surprise-Based Event Segmentation
Rather than arbitrary chunking, EM-LLM uses surprise metrics to identify event boundaries—moments where the content shifts meaningfully. This aligns with research showing humans segment experiences when predictions are violated.
The model then applies temporal contiguity and asymmetry effects during retrieval, matching patterns from human free recall studies. Information temporally close to important events is more likely to be retrieved, just as in human memory (ICLR 2025 Paper).
Benchmark Results
EM-LLM outperformed previous state-of-the-art approaches:
- Beat InfLLM (the previous leader) across multiple benchmarks
- Surpassed RAG with state-of-the-art retrievers (NV-Embed-v2)
- Matched or exceeded full-context models while using far less memory
- Successfully performed passkey retrieval across 10M tokens—a length computationally infeasible for full-context models
3. Infinite Retrieval: Attention-Driven Selection
Published in February 2025, “Infinite Retrieval: Attention Enhanced LLMs in Long-Context Processing” (arXiv) introduced a training-free method that uses the LLM’s own attention mechanism to identify and retain critical tokens.
The Core Insight
Traditional RAG systems use external embedding models to retrieve relevant passages. Infinite Retrieval realized that LLMs already excel at determining which information is relevant through their attention scores. Why not use that capability directly?
The approach works by:
- Chunking: Splitting input into complete sentences (respecting semantic boundaries)
- Attention-Driven Selection: Using final-layer attention scores to identify the top-K most relevant tokens per chunk
- Sentence-Level Retention: Keeping full sentences containing important tokens, preserving context
- Iterative Processing: Sequentially processing chunks while maintaining a cache of retained information
Performance Gains
On HotpotQA (a multi-document QA task), Infinite Retrieval achieved 288% improvement (from 14.8 to 57.52 accuracy). The method retained only 8.7% of input tokens while maintaining high accuracy—proving you don’t need to store everything to remember what matters (arXiv).
Also Read: Real-Time Data Meets Agents: Designing Context Engines for Decision Automation
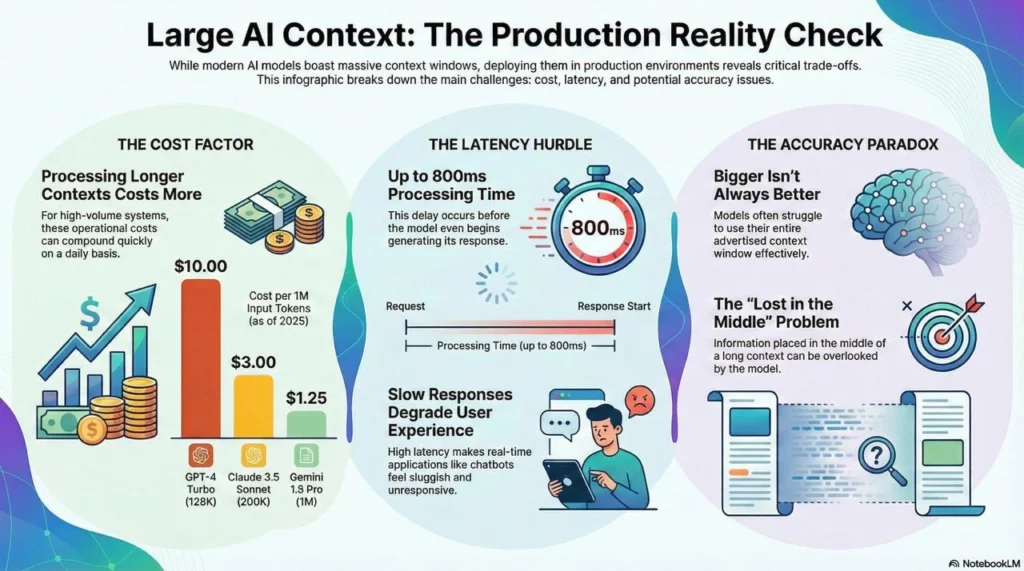
The Memory-Context Trade-off: Production Realities
While these techniques enable effectively infinite context, production deployments face practical constraints:
Computational Cost
Processing longer contexts costs more. As of 2025:
- GPT-4 Turbo (128K context): $10 per million input tokens
- Claude 3.5 Sonnet (200K context): $3 per million input tokens
- Gemini 1.5 Pro (1M context): $1.25 per million input tokens
For enterprises running high-volume AI systems, these costs compound quickly. A customer service bot processing 10M tokens daily incurs $12-100 daily in context costs alone, not counting generation.
Latency Considerations
Longer contexts mean slower inference:
- Vector search retrieval: 50-200ms
- Attention computation: 100-500ms per segment
- Memory compression: 50-150ms per update
- Full pipeline: 200-800ms for context-heavy queries
For real-time applications, this latency matters. A chatbot that takes 800ms just to process context before generating a response feels sluggish.
The Accuracy Paradox
Research from 2025 found that the maximum effective context window (MECW) varies by task and model. Some models struggle to use their full advertised context window effectively, particularly for tasks requiring integration of information from different positions (arXiv).
This means having a 1M-token window doesn’t guarantee the model will actually use all 1M tokens effectively. Production systems must test whether their specific use case benefits from extended context or suffers from the “lost in the middle” problem.
RAG vs. Infinite Context: When to Use Each
The question isn’t whether to use RAG or infinite context—it’s when to use which approach:
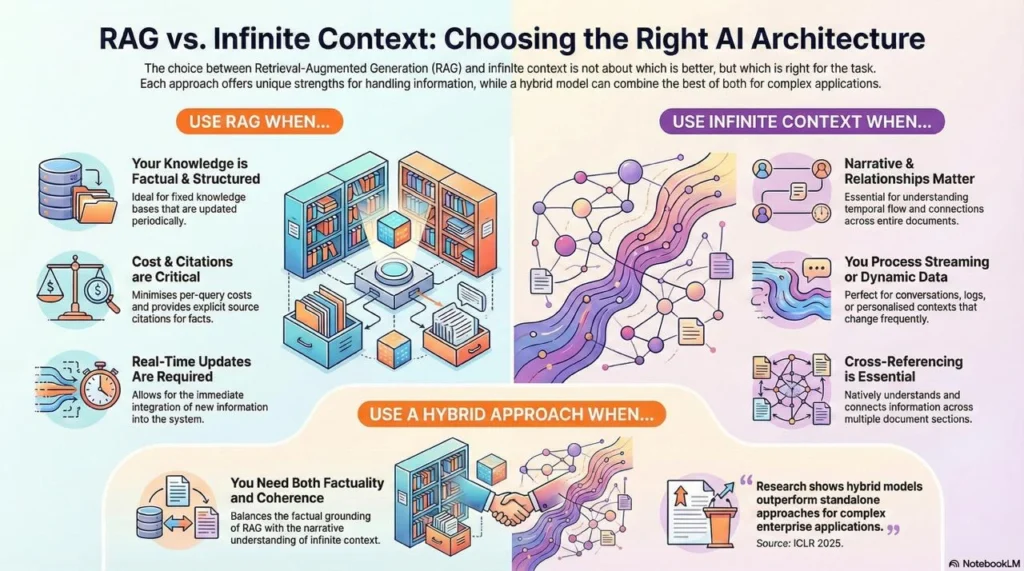
Use RAG When:
- You have a fixed knowledge base that updates periodically
- Information is factual and well-structured
- You need explicit source citations
- Cost per query must be minimized
- Real-time updates to knowledge are required
Use Infinite Context When:
- Tasks require understanding relationships across entire documents
- Temporal ordering and narrative flow matter
- You’re processing streaming data (conversations, logs)
- Cross-referencing multiple sections is essential
- Context changes frequently (personalized conversations)
Use Hybrid When:
- You need both factual grounding (RAG) and narrative coherence (infinite context)
- Cost-sensitive but accuracy-critical applications
- Tasks span multiple documents with complex relationships
Research shows that combining RAG with extended context handling outperforms either approach alone for complex enterprise applications (ICLR 2025).
The Future: Toward Context-Unlimited AI
Several trends are shaping the next generation of context handling:
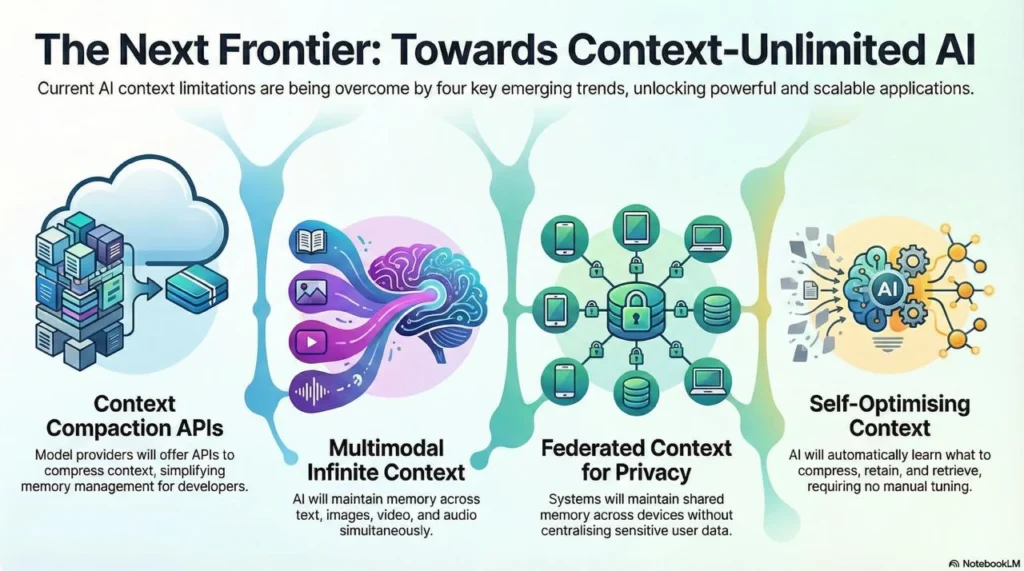
1. Context Compaction APIs
OpenAI’s GPT-5.2-Codex introduced dedicated context compaction endpoints that perform server-side compression. This offloads memory management from the application to the model provider, simplifying implementation for enterprises.
Expect more providers to offer similar APIs, letting developers specify compression ratios and retention policies rather than implementing compression themselves.
2. Multimodal Infinite Context
Current infinite context research focuses on text. The next frontier is multimodal memory, maintaining context across images, video, audio, and text simultaneously.
This enables applications like:
- Video analysis that remembers content from hours earlier
- Multimodal conversations that reference images from days ago
- Document processing that handles mixed media (charts, diagrams, photos)
3. Federated Context
For enterprises concerned about data privacy, federated context systems will maintain compressed memories across distributed systems without centralizing sensitive data.
Research on privacy-preserving memory mechanisms is accelerating, with techniques like differential privacy and secure multi-party computation enabling shared context without exposing raw data.
4. Self-Optimizing Context
Future systems will automatically learn which information to compress, what to retain in full fidelity, and when to retrieve from long-term memory which means no manual tuning required.
By training specialized compression models on your specific domain, context management becomes adaptive: legal documents get different treatment than code, customer conversations follow different patterns than technical documentation.
Conclusion: Memory as the New Frontier
The race for longer context windows is over—infinite context is here. The new challenge is using it effectively: compressing what can be compressed, retaining what matters, and retrieving the right information at the right time.
Infini-attention, EM-LLM, and Infinite Retrieval represent different philosophical approaches to this problem. Google’s compressive memory prioritizes efficiency. Human-inspired episodic memory prioritizes biological plausibility. Attention-driven selection prioritizes precision.
The best production systems don’t pick one—they combine multiple techniques based on task requirements, cost constraints, and performance needs.
At Dextra Labs, we help enterprises and SMEs across the UAE, USA, and Singapore navigate these architectural decisions. Whether you’re building AI agents, implementing RAG systems, or deploying conversational AI, we bring hands-on experience in production context management that actually works at scale.
The question isn’t whether your AI system should handle infinite context. It’s how you’ll architect memory systems that are efficient enough for production, accurate enough for your domain, and maintainable enough to evolve as models improve.