
The rapid rise of Generative AI has transformed Large Language Models (LLMs) from experimental tools for research into strategic assets within enterprise technology. According to McKinsey’s 2024 Global AI Survey, 65% of organizations are now using generative AI to support at least one business function—almost double that in 2023. For CTOs working in technology startups and mid-sized firms in the USA, UAE, and Singapore, this trend signals an urgent call to action. Early adopters of generative AI deployments are already benefiting from improved operational efficiency, product differentiation in the market, and improved innovation velocity. Meanwhile, late movers risk extinction.
With many more organizations seeking scalable, secure, and cost-efficient infrastructure to deploy their Generative AI, Dextralabs is the AI consulting partner of choice that assists technology leaders in overcoming the complexity of deploying enterprise LLMs through a personalized and methodical strategy, trusted architecture, and proven experience.
Understanding Enterprise LLM Deployment: A High-Level Overview
Let’s start by understanding what LLMs are! Large Language Models (LLMs) are advanced AI systems trained on vast datasets in order to interpret and produce human-like language. They are the engines underlying applications like ChatGPT, but when designed for enterprise applications, they can be far more than chatbots.
In real-world enterprise settings, LLMs are already streamlining customer support, generating code, drafting legal documents, summarizing research, and powering internal knowledge assistants. These use cases aren’t hype—they’re live, measurable, and delivering ROI today.
With that said, using an LLM in a business setup is another game altogether, unlike with conventional AI. There is even more on the line, data security, inference cost, latency, versioning, compliance, and customization. Unlike off-the-shelf AI models, enterprise LLMs require deliberate planning: picking the right architecture, deciding between cloud vs. local deployment, integrating LLMOps tools, and managing ongoing fine-tuning.
You don’t need to reinvent the wheel. Follow the same high-level path —adapt it to your context, and you’ll be in a strong position to roll out a scalable, low-risk LLM system. And if you hit a roadblock, Dextralabs is always there to help simplify the complex.

Ready to Deploy LLMs at Scale?
Talk to our experts about LLM deployment architecture, inference optimization, and compliance-ready pipelines.
Book Your Free AI ConsultationKey Deployment Strategies for LLMs
When planning your enterprise LLM deployment, the first decision is how you want the model to interact with data. You can run a native model as-is, which is fast to set up but limited in accuracy and customization. On the other end, internet-connected models offer dynamic responses with live data—but introduce security and compliance risks, especially in regulated industries. For most enterprise AI deployments, curated content models strike the right balance. These are fine-tuned or prompt-engineered on internal data, reducing hallucinations and making outputs far more relevant to your business.
Another effective approach is integrating plugin-based LLMs into your existing enterprise systems. These allow you to inject language intelligence directly into workflows—like CRMs, internal wikis, or ticketing systems—without a major overhaul. And if your use case depends on real-time or evolving content (like support docs or product specs), Retrieval-Augmented Generation (RAG) becomes essential.
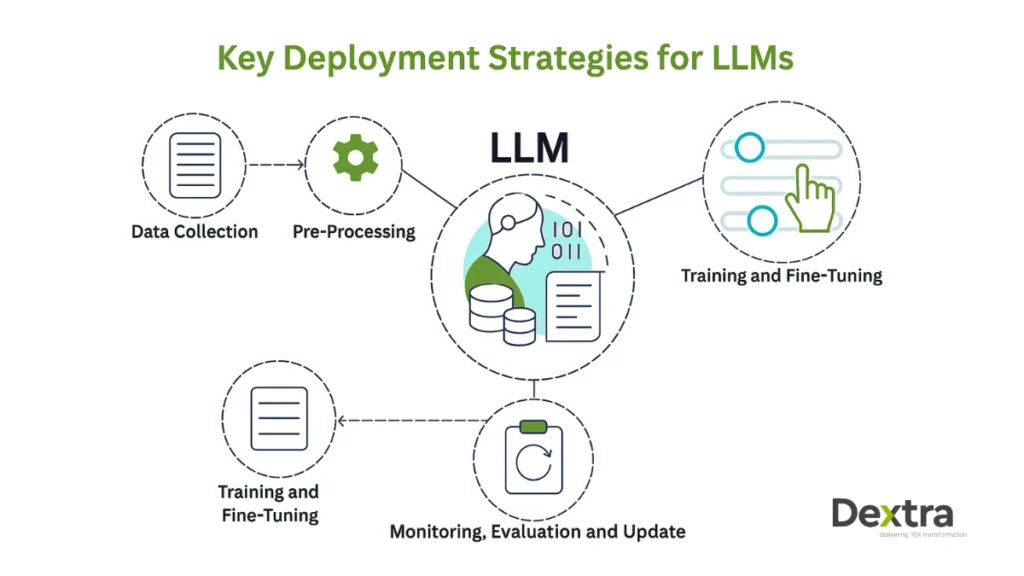
RAG enhances performance by retrieving relevant data at runtime, making it ideal for LLM local deployment where retraining is too slow or costly. The right LLM deployment architecture—modular, secure, and scalable—will determine whether your LLM stays in pilot mode or becomes a true operational asset. For startups unsure about the right LLM architecture, our AI Consulting for Startups service helps you assess trade-offs and deploy intelligently from day one.
Security and Compliance: Non-Negotiables in LLM Deployment
If you’re deploying an LLM in an enterprise setting, security isn’t something you can afford to overlook. You’re not only producing outputs, you’re managing sensitive data, customer data, possibly even regulated healthcare and financial records. This is why data governance, encryption at all levels, and trusted DLP (Data Loss Prevention) tools are not just nice-to-haves; they are essential. It doesn’t matter if you choose a cloud-based solution or leaning into LLM local deployment, you’ve got to make sure every data stream is locked down, traceable, and compliant.
Now, if your teams are working across regions like the US, UAE, or Singapore (which a lot of our clients are), compliance adds even more pressure. You’re dealing with HIPAA in the States, ADGM in the UAE, and PDPA in Singapore—each with its own data privacy demands. At Dextralabs, we’ve built secure deployment pipelines that check all those boxes from day one. One client we worked with in the UAE’s fintech space needed full compliance with ADGM, so we designed a hybrid setup: sensitive data stayed on-prem, with encrypted traffic flowing to a cloud-hosted LLM inference layer. It worked seamlessly—and kept the regulators happy.
Bottom line: if you’re serious about enterprise AI deployment, don’t wait until later to think about security. Add it into your architecture from the start.
Infrastructure Planning: Cloud, On-Premise, or Hybrid?
One of the first real decisions you’ll face in enterprise LLM deployment is where to actually run your models. Do you go full cloud? Keep it all on-prem? Or do what I’ve found works best for most orgs—go hybrid? There’s no perfect answer, but if you know your compliance needs, latency expectations, and budget, you can make a smart, future-proof call.
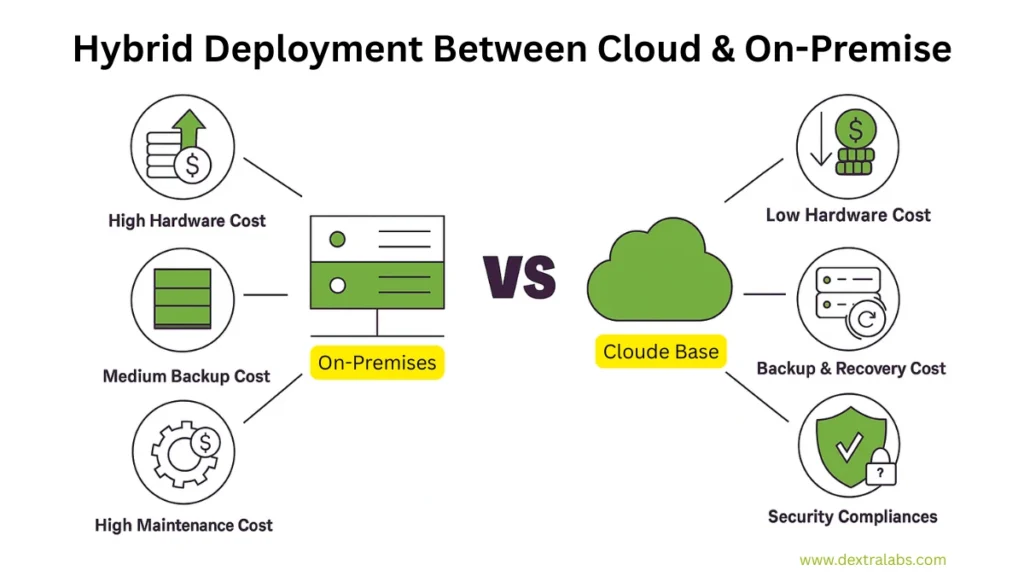
Hybrid cloud setups are quickly becoming the go-to for enterprise AI deployments, and for good reason. They give you the flexibility of the cloud—like rapid scaling and integration with modern APIs—while letting you keep sensitive data on-prem or in a private environment. That’s especially useful if you’re working across regions with strict privacy laws or just want tighter control over your stack. At Dextralabs, we’ve helped teams deploy hybrid LLM solutions that let them train in the cloud and serve locally, cutting costs and reducing risk.
You’ll also want to think carefully about your GPU strategy. LLMs are compute-heavy, and unless you optimize for inference, costs and latency can spiral. It is always recommended starting with quantized models or using tools like NVIDIA’s Triton for smarter GPU usage. It doesn’t matter if your deployment is on AWS, GCP, or a private cluster; your infrastructure decisions will determine if your LLM works—or just works well. If you have no idea how to start, we’re happy to walk you through what has (and hasn’t) worked in real-world LLM deployment architectures.
Inference Optimization and Cost Management
When it comes to enterprise LLM deployment, inference speed isn’t just a nice-to-have—it directly impacts user experience and productivity. Slow responses can kill adoption, frustrate users, and slow down decision-making. That’s why inference optimization is a must, especially if your LLM powers customer-facing apps or internal workflows.
One of the best ways to speed things up and cut costs is through quantization—basically shrinking your model to run faster without sacrificing much accuracy. We’ve seen teams cut inference time by up to 50% with this technique. Plus, tools like Ollama, NVIDIA NIM, and Hugging Face’s Inference API make it easier to manage and deploy optimized models without reinventing the wheel.
Just a quick note… training an LLM from scratch is generally overkill for startups and mid-sized companies. That’s a lot of cost, time, data, and computational resources. You could also fine-tune off-the-shelf models, or take the retrieval-augmented generation (RAG) approach to get exactly what you want in an efficient way. If you want to explore intelligent and cost-effective approaches to LLM implementation – let Dextralabs take you through that costly world so you avoid those costly blunders.
LLMOps & Monitoring Tools: From Deployment to Observability
Think of LLMOps as the specialized approach to managing Large Language Models throughout their lifecycle. It goes beyond deployment to ensure models continue running smoothly, reliably, and safely over time. This is critical because LLMs can experience drift, produce unexpected outputs, or face scaling challenges without ongoing monitoring.
Tools like Fiddler AI, Arize, and Weights & Biases offer real-time insights about model performance, data quality, bias, and usage. This gives teams the ability to spot and rectify problems early – before they present risks to users or business results.
Dextralabs has created an LLMOps architecture playbook developed to integrate these different tools into an integrated workflow that includes deployment, continuous evaluation, and alerting. This framework helps organizations throughout the USA, UAE, and Singapore keep a very tight grip on their enterprise LLM deployment while maintaining reliability, security, and compliance with their growth in AI.
For startups or mid-sized companies that want to either get started or improve LLM monitoring that they have been doing, the services an expert can provide can demystify what is perceived as a complicated and opaque process.
Case Study: Dextralabs Deploying LLMs for a Global SaaS Startup
Dextralabs recently helped a global SaaS startup deploy an enterprise-grade LLM solution. The challenge was to build a system that could handle lots of users across different regions while keeping response times fast and answers accurate. The startup also needed to ensure their sensitive customer data stayed secure and met regional compliance rules.
By designing a hybrid cloud LLM deployment architecture and using smart inference optimization, Dextralabs helped reduce latency by 40% and improved the model’s accuracy on business-specific tasks. The solution was built to scale easily as the startup grew, saving both time and money in the long run.
Client feedback:
“Working with Dextralabs made deploying our AI model simple and worry-free. They understood our needs and delivered a solution that really works for us.”
This project shows how a well-planned enterprise LLM deployment can boost performance and trust, even for complex, fast-growing companies.
Top Tools for Local and Cloud-Based LLM Deployment
When it comes to LLM deployment services, choosing the right tools makes all the difference. For local setups, Ollama is a popular choice—offering fast, lightweight deployment that’s perfect for development teams testing and iterating quickly. On the cloud front, NVIDIA’s Inference Microservice (NIM) offers powerful GPU optimization that will keep the inference fast and cost-effective.
If you are seeking end-to-end AI deployments, especially for complex workflows and heavy workloads, there is C3 AI and Nutanix, platforms to help enterprises that need some robust and scalable options. At the end of the day, you will have to weigh your options based on your organization’s size, data privacy needs, and growth plans when determining the right engineering tool to use.
With extensive experience in enterprise LLM deployment and LLM implementation, Dextralabs helps you evaluate your goals and environment so that you can pick the right tools and architecture—saving time, reducing risks, and enabling smooth scaling.
Conclusion: Building Future-Ready Enterprises with Dextralabs
Implementing an enterprise-level LLM is a serious undertaking, one that requires planning, strong security, and thoughtful infrastructure selection. Having a trusted consulting partner like Dextralabs can make all the difference, guiding you through each stage from architecture design to ongoing optimization.
By working with us, startups and mid-sized firms benefit from scalable, secure, and cost-efficient enterprise LLM deployment that delivers real business impact. Ready to future-proof your AI strategy?
Book a free consultation with Dextralabs today and take the first step toward unlocking the full potential of Large Language Models for your organization. Plus, find out how you can deploy LLM for free with our expert guidance.
Build with Confidence. Deploy with Precision.
Accelerate your AI journey with Dextralabs — your trusted partner for enterprise LLM deployment services.
Book Your Free AI ConsultationFAQs:
Q. What is the name of the popular deployment tool for LLM applications?
Tools like Ollama, NVIDIA NIM, and C3 AI are currently among the most used for LLM deployment in enterprise setups.
Q. How does Ollama simplify LLM deployment?
Ollama enables developers to run and test large models locally with minimal configuration. It offers fast performance, great for development and testing phases.
Q. What are the main benefits of using Ollama for local LLM deployment?
Speed, ease of use, offline capability, and better control over fine-tuning and privacy-sensitive data make Ollama ideal for early-stage testing.









