The Retrieval-Augmented Generation market is projected to grow from $1.2 billion in 2024 to $11.0 billion by 2030, representing a CAGR of 49.1% (Grand View Research). But here’s the problem: most tutorials teach you to copy-paste code without understanding what makes RAG actually work.
The difference between a RAG system that reduces hallucinations by 70-90% (Mordor Intelligence) and one that fails in production isn’t the generative model—it’s the retrieval component. At Dextra Labs, we help enterprises and SMEsacross the UAE, USA, and Singapore build production RAG systems. The pattern is consistent: teams that master retrieval build systems that scale; those that don’t hit a wall at deployment.
This guide presents 10 hands-on projects designed to teach you retrieval mechanics through implementation. Each project builds on the previous one, taking you from basic vector search to production-grade RAG architectures. These aren’t toy examples—they’re patterns we use in real enterprise deployments.
Why Retrieval Matters More Than You Think?
Before jumping into projects, understand this: RAG systems fail because of retrieval, not generation. Research published at NeurIPS 2024 found that “retriever matters consistently” across different generators, with retrieval quality being the primary determinant of overall system performance (RAGCHECKER, NeurIPS 2024).
The RGB Benchmark (Retrieval-Augmented Generation Benchmark) identifies four fundamental abilities required for effective RAG (arXiv):
- Noise Robustness: Handling irrelevant retrieved documents without degrading output quality
- Negative Rejection: Recognizing when no retrieved documents contain relevant information
- Information Integration: Synthesizing information from multiple retrieved sources coherently
- Counterfactual Robustness: Resisting misleading or contradictory information in retrieved context
Every project in this guide addresses one or more of these capabilities.
Project 1: Build a Semantic Search Engine (Dense Retrieval Fundamentals)
What You’ll Learn: Vector embeddings, similarity search, semantic vs. keyword matching
The Challenge: Implement a semantic search system that finds documents based on meaning, not just keywords.
Implementation Steps
- Choose an Embedding Model:
- sentence-transformers/all-MiniLM-L6-v2: Fast, good for learning (384 dimensions)
- text-embedding-3-small (OpenAI): Production-quality, 1536 dimensions
- E5-Large-Instruct: Top-performing open-source option
- Build Your Vector Database:
- Start with FAISS (Facebook AI Similarity Search) for local development
- Index 10,000+ documents from a domain you understand (Wikipedia, documentation, news articles)
- Implement Query Pipeline:
query = “How does photosynthesis work?”
query_vector = model.encode(query)
results = faiss_index.search(query_vector, k=5)
- Measure What Matters:
- Precision@K: Of the top K results, how many are actually relevant?
- Recall@K: What percentage of all relevant documents did you retrieve in top K?
- MRR (Mean Reciprocal Rank): How high up is the first relevant result?
Why This Matters?
Dense retrieval is the foundation of modern RAG systems. Unlike keyword search (BM25), dense retrieval understands that “how do plants make food” and “explain photosynthesis” are asking the same thing.
Project 2: Implement Hybrid Search (Combining Sparse and Dense Retrieval)
What You’ll Learn: BM25 (sparse retrieval), score fusion, when to use which approach
The Challenge: Build a system that combines keyword matching with semantic understanding.
Why Hybrid Search Wins
The MEGA-RAG framework achieved over 40% reduction in hallucinations by integrating multiple retrieval methods (PMC). Pure semantic search misses exact matches; pure keyword search misses semantic relationships. Hybrid search gets both.
Implementation Steps
- Implement BM25 Retrieval:
from rank_bm25 import BM25Okapi
tokenized_docs = [doc.split() for doc in corpus]
bm25 = BM25Okapi(tokenized_docs)
bm25_scores = bm25.get_scores(query.split())
- Implement Dense Retrieval (from Project 1)
- Score Fusion:
- Reciprocal Rank Fusion (RRF): Combine rankings, not raw scores
- Weighted Linear Combination: Balance sparse/dense contributions
- Test on Different Query Types:
- Entity queries (“Einstein’s birth year”): BM25 often wins
- Conceptual queries (“theories of relativity”): Dense retrieval wins
- Mixed queries (“Einstein’s contributions to physics”): Hybrid wins
Project 3: Build a Reranker (Two-Stage Retrieval)
What You’ll Learn: Cross-encoders, retrieval vs. ranking, the speed-accuracy tradeoff
The Challenge: Use a slower, more accurate model to rerank top results from fast retrieval.
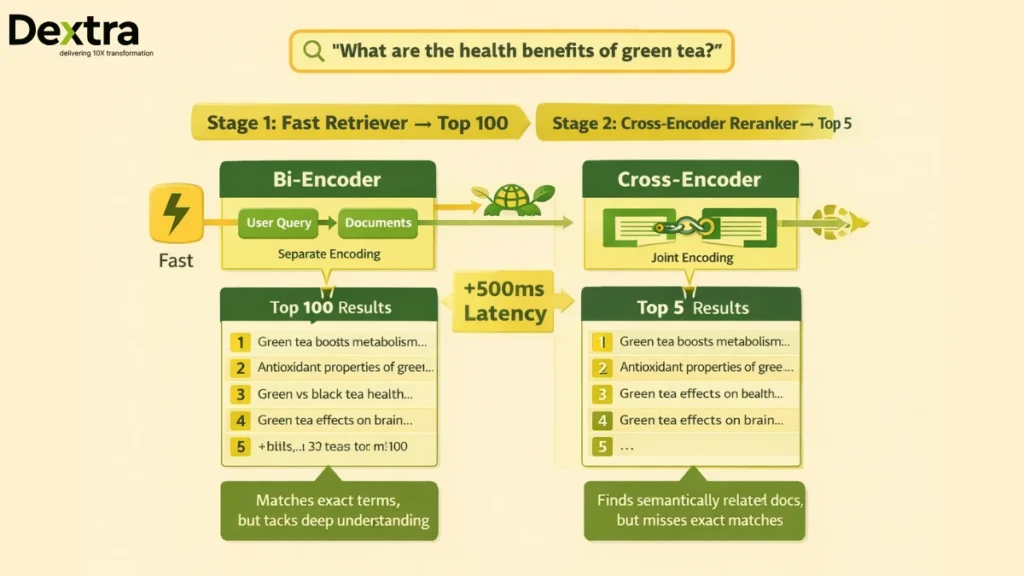
The Two-Stage Pattern
First stage: Fast retriever gets top 100 candidates
Second stage: Slow reranker scores the top 100, returns best 5
This is how production RAG systems balance latency and quality.
Implementation Steps
- Retrieve Candidates (100-200 documents using hybrid search from Project 2)
- Load a Cross-Encoder:
from sentence_transformers import CrossEncoder
reranker = CrossEncoder(‘cross-encoder/ms-marco-MiniLM-L-6-v2’)
- Score Query-Document Pairs:
pairs = [[query, doc] for doc in candidates]
scores = reranker.predict(pairs)
reranked_docs = sort_by_scores(candidates, scores)
- Measure Impact:
- Compare retrieval quality before and after reranking
- Track latency increase (typically 100-300ms)
- Calculate whether accuracy improvement justifies cost
Why Cross-Encoders Win?
Bi-encoders (your embedding model) process query and document separately, then compare vectors. Cross-encoders process them together, capturing fine-grained interactions. They’re more accurate but slower—perfect for the second stage.
Project 4: Implement Query Expansion and Transformation
What You’ll Learn: Query preprocessing, handling ambiguous queries, LLM-based query reformulation
The Challenge: Improve retrieval by transforming queries before searching.
Query Transformation Techniques
- Query Expansion with Synonyms:
- Add domain-specific synonyms
- Use WordNet or domain ontologies
- Multi-Query Generation:
- Use an LLM to generate 3-5 variations of the user query
- Retrieve for each variation
- Combine results using RRF
- HyDE (Hypothetical Document Embeddings):
- Generate a hypothetical answer to the query
- Embed the hypothetical answer
- Search using the answer embedding (often more specific than the question)
Implementation Example
# Multi-query approach
variations = llm.generate(f”Generate 3 alternative phrasings of: {query}”)
all_results = []
for variant in variations:
results = retrieve(variant, k=10)
all_results.extend(results)
final_results = reciprocal_rank_fusion(all_results, k=5)
When This Matters
User queries are often vague (“tell me about the contract”). Query transformation helps by expanding “contract” to specific terms: “service level agreement,” “payment terms,” “termination clauses.”
Project 5: Build Contextual Chunk Retrieval
What You’ll Learn: Chunking strategies, context windows, preserving semantic boundaries
The Challenge: Split documents intelligently so each chunk contains complete, meaningful information.
Chunking Strategies
Research shows that chunking strategies significantly impact RAG performance. Bad chunking breaks sentences mid-thought or splits related paragraphs.
- Fixed-Size Chunking:
- 512 tokens per chunk with 50-token overlap
- Fast but context-agnostic
- Semantic Chunking:
- Split on paragraph boundaries
- Use LLMs to identify topic shifts
- Maintain complete thoughts
- Hierarchical Chunking:
- Create chunks at multiple granularities (sentence, paragraph, section)
- Retrieve at coarse level, return fine level
Implementation
def semantic_chunk(document, max_tokens=512):
paragraphs = document.split(‘\n\n’)
chunks = []
current_chunk = “”
for para in paragraphs:
if len(tokenize(current_chunk + para)) <= max_tokens:
current_chunk += para + “\n\n”
else:
chunks.append(current_chunk)
current_chunk = para + “\n\n”
return chunks
Add Context Headers
When retrieving chunks, prepend metadata:
Document: “2024 Employee Handbook”
Section: “Remote Work Policy”
Chunk: [actual content]
This helps the LLM understand where information comes from.
Project 6: Implement Metadata Filtering
What You’ll Learn: Structured filters, combining vector search with traditional filters, RAG for enterprise data
The Challenge: Search within subsets of your corpus based on metadata (date, department, document type).
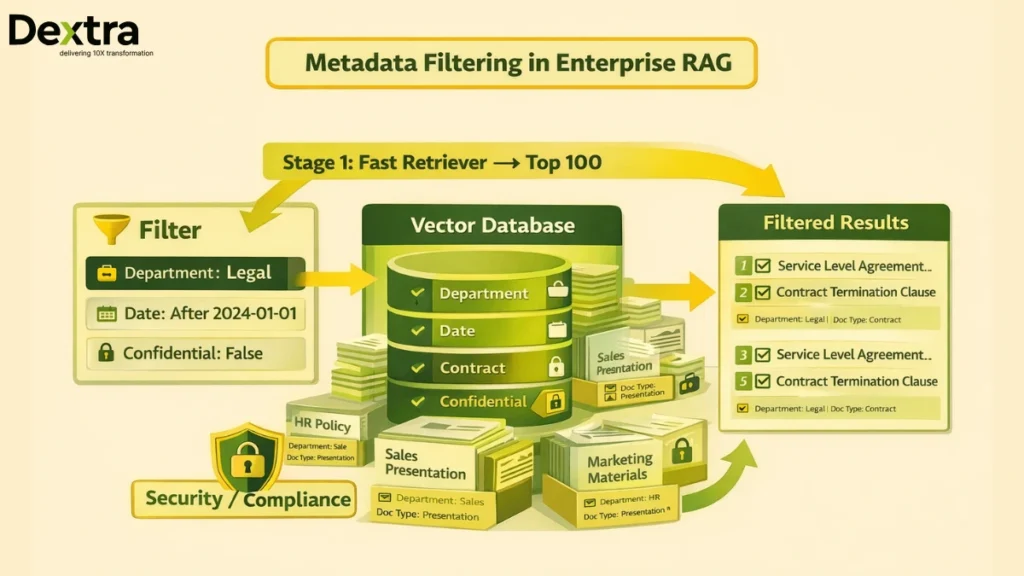
Why Metadata Matters
Enterprise RAG rarely searches all documents. A legal query should only search contracts, not marketing materials. A finance question should only search current fiscal year documents, not archived data.
Implementation Steps
- Store Metadata with Vectors:
{
“id”: “doc_123”,
“vector”: [0.12, 0.43, …],
“metadata”: {
“department”: “Legal”,
“doc_type”: “Contract”,
“date”: “2024-01-15”,
“confidential”: true
}
}
- Filter Before or During Search:
- Pre-filtering: Narrow corpus, then search (more accurate)
- Post-filtering: Search all, then filter results (faster)
- Combine Filters:
results = vector_db.search(
query_vector,
filter={
“department”: “Legal”,
“date”: {“$gte”: “2024-01-01”},
“confidential”: {“$ne”: true}
},
k=10
)
Project 7: Build a Multi-Index RAG System
What You’ll Learn: Routing queries to specialized indices, domain-specific retrieval, agentic RAG
The Challenge: Route different query types to specialized retrievers for better accuracy.
The Multi-Index Pattern
Instead of one giant index, maintain specialized indices:
- Code index: GitHub repositories, technical documentation
- Business index: Contracts, policies, financial reports
- Customer index: Support tickets, feedback, conversations
Route queries to the appropriate index(es) based on intent classification.
Implementation Steps
- Build Intent Classifier:
intent = classifier.predict(query)
# Returns: “technical”, “business”, “customer_support”
- Route to Specialized Index:
if intent == “technical”:
results = code_index.search(query)
elif intent == “business”:
results = business_index.search(query)
else:
# Search multiple indices and merge
results = merge_results([
code_index.search(query),
business_index.search(query)
])
- Optimize Each Index:
- Code index: Emphasize exact matches, function names
- Business index: Emphasize semantic search for concepts
- Customer index: Emphasize recent documents, sentiment
When Multi-Index Wins
The Agentic RAG market is expected to reach $165 billion by 2034, growing at 45.8% CAGR (Market.us), driven by routing agents that direct queries to specialized retrievers.
Project 8: Implement Retrieval Evaluation Metrics
What You’ll Learn: RAG evaluation, RAGAS framework, measuring retrieval quality, continuous improvement
The Challenge: Build systematic evaluation to measure and improve your RAG system.
The RAGAS Framework
Research published at arXiv introduced RAGAS (Retrieval-Augmented Generation Assessment), a framework for reference-free evaluation of RAG pipelines (arXiv).
Key Metrics:
- Context Precision: Are retrieved documents relevant to the query?
- Context Recall: Did you retrieve all relevant information?
- Faithfulness: Is the generated answer grounded in retrieved context?
- Answer Relevance: Does the answer actually address the question?
Implementation Example
from ragas import evaluate
from ragas.metrics import context_precision, faithfulness
results = evaluate(
dataset=test_queries,
metrics=[context_precision, faithfulness],
llm=eval_llm
)
print(f”Context Precision: {results[‘context_precision’]}”)
print(f”Faithfulness: {results[‘faithfulness’]}”)
Build Your Test Set
- Curate 50-100 Question-Answer Pairs from your domain
- Include Edge Cases: ambiguous queries, multi-hop reasoning, negations
- Track Metrics Over Time: Monitor whether changes improve or degrade performance
Production Practice
RAGBench, published in 2025, provides 100K industry-specific examples across five domains (arXiv). Build your own smaller benchmark that reflects your actual use cases.
Project 9: Build a Production RAG Pipeline with Monitoring
What You’ll Learn: End-to-end system design, latency optimization, production monitoring, cost management
The Challenge: Deploy a complete RAG system with observability and continuous improvement.
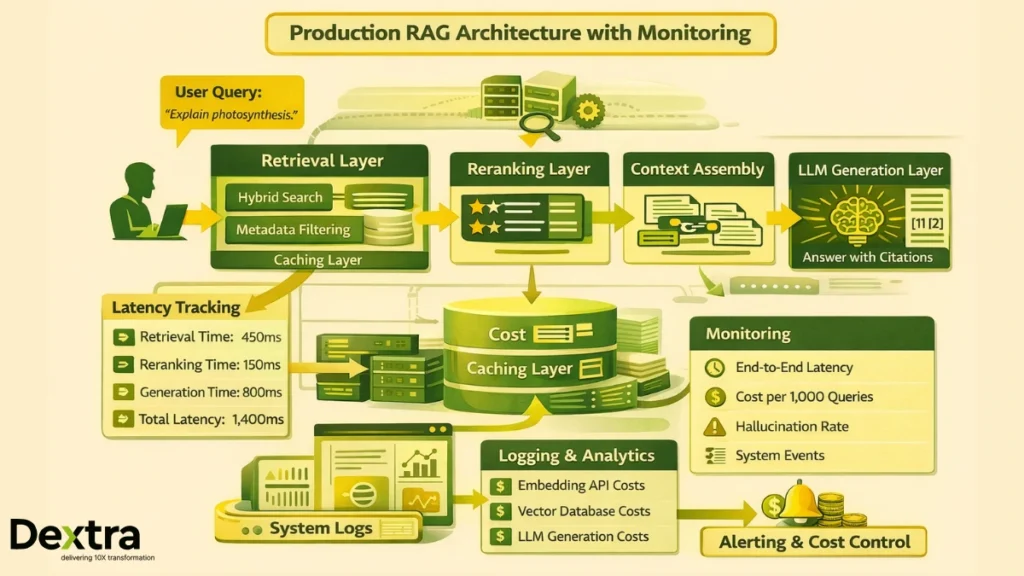
Production Architecture
User Query
↓
Query Preprocessing (transformation, expansion)
↓
Retrieval Layer (hybrid search, metadata filtering)
↓
Reranking Layer (cross-encoder scoring)
↓
Context Assembly (chunk aggregation, deduplication)
↓
Generation Layer (LLM with grounded prompting)
↓
Response + Citations
Monitor What Matters
- Latency Breakdown:
- Time spent on retrieval
- Time spent on reranking
- Time spent on generation
- Total end-to-end latency
- Quality Metrics:
- User feedback (thumbs up/down)
- Citation accuracy
- Hallucination rate
- Answer completeness
- Cost Tracking:
- Embedding API costs
- Vector database costs
- LLM generation costs
- Infrastructure costs
Optimization Strategies
- Cache frequently retrieved chunks to reduce embedding costs
- Batch queries when possible to reduce API overhead
- Use smaller models for simpler queries (tiered approach)
- Implement rate limiting to prevent cost runaway
Also Read: Production RAG in 2026: Evaluation Suites, CI/CD Gates, and Observability You Can’t Ignore
Project 10: Advanced RAG with Self-Improvement
What You’ll Learn: Active learning, retrieval feedback loops, agentic RAG, continuous optimization
The Challenge: Build a RAG system that learns from user interactions and improves over time.
Self-Improvement Mechanisms
- Collect User Feedback:
- Track which retrieved documents users click
- Record corrections to generated answers
- Monitor queries that produce low-confidence responses
- Hard Negative Mining:
- Identify documents that scored high but were irrelevant
- Fine-tune retrievers to distinguish these hard negatives
- Continuously update negative examples
- Retrieval Fine-Tuning:
- Use actual query-document pairs from your system
- Fine-tune embedding models on domain-specific data
- Research shows fine-tuned models achieve 72.5% accuracy on HaluEval vs. 44.56% for naive RAG (IEEE)
- Adaptive Chunking:
- Analyze which chunk sizes work best for different query types
- Adjust chunking strategy based on retrieval performance
- Maintain separate chunking policies for code vs. prose
Implementation Pattern
# Collect feedback
user_feedback = {
“query”: query,
“retrieved_docs”: doc_ids,
“clicked_doc”: clicked_doc_id,
“rating”: user_rating
}
# Periodically retrain
if len(feedback_buffer) >= 1000:
positives = [f for f in feedback_buffer if f[‘rating’] > 3]
negatives = [f for f in feedback_buffer if f[‘rating’] <= 2]
fine_tune_retriever(positives, negatives)
update_production_model()
Conclusion: From Projects to Production
The RAG market’s 49% CAGR (Grand View Research) reflects growing enterprise adoption, but success requires more than following tutorials. The difference between a proof-of-concept and a production system is understanding retrieval at a fundamental level.
These 10 projects teach you:
- How retrieval works (Projects 1-3)
- Why certain approaches work better (Projects 4-6)
- When to use which technique (Projects 7-8)
- How to maintain systems in production (Projects 9-10)
Research shows that hallucination reductions between 70-90% are achievable when RAG pipelines are properly implemented (Mordor Intelligence). But “properly implemented” means understanding retrieval mechanics, not just connecting APIs. At Dextra Labs, we’ve guided enterprises through this journey across fintech, healthcare, legal, and e-commerce domains. The pattern is consistent: teams that invest time understanding retrieval build systems that scale; those that treat it as a black box hit production walls.
FAQs on RAG projects:
Q. Why is retrieval more important than generation in RAG systems?
Retrieval determines whether the model receives relevant, accurate context. Even the best LLM will hallucinate if retrieval fails. Research shows retrieval quality is the primary driver of RAG performance, affecting accuracy, faithfulness, and hallucination rates.
Q. What skills do these RAG projects actually teach beyond basic tutorials?
These projects teach core retrieval mechanics, including vector search, hybrid sparse-dense retrieval, reranking, query transformation, chunking strategies, metadata filtering, and retrieval evaluation, skills required for building production-grade RAG systems.
Q. Are these RAG projects suitable for production systems or just learning exercises?
They are designed around real enterprise deployment patterns, not toy demos. The projects cover latency optimization, observability, evaluation frameworks, self-improving retrieval loops, and cost control, key requirements for production RAG systems.
Q. How do these projects help reduce hallucinations in RAG applications?
By improving retrieval quality through hybrid search, reranking, contextual chunking, and evaluation, these projects address the root cause of hallucinations. Proper retrieval pipelines can reduce hallucinations by 70–90%, according to industry research.
Q. Do I need fine-tuning to build effective RAG systems?
Not initially. Most RAG performance gains come from better retrieval design, not model fine-tuning. Fine-tuning retrievers becomes useful later, after collecting real query-document interaction data and identifying hard negative examples.
Q. How do these projects scale from small datasets to enterprise data?
The projects introduce scalable patterns such as multi-index RAG, metadata filtering, two-stage retrieval, caching, and monitoring. These techniques allow systems to scale from thousands to millions of documents without sacrificing retrieval quality.
Q. Who should work through these RAG projects?
These projects are ideal for ML engineers, backend developers, AI architects, and platform teams who already understand basic RAG concepts and want to move from proof-of-concept implementations to reliable, production-ready systems.