Large Language Models, or LLMs, have revolutionized the way businesses deal with data, document analysis, and software management. Whether it involves summarization, code analysis, or complex business-related questions, LLMs have begun to become an integral part of business workflows.
However, context size remains a critical challenge. Their legal teams have to cope with thousands of contracts, engineering teams with huge amounts of code, and the data teams with ever-expanding data lakes.
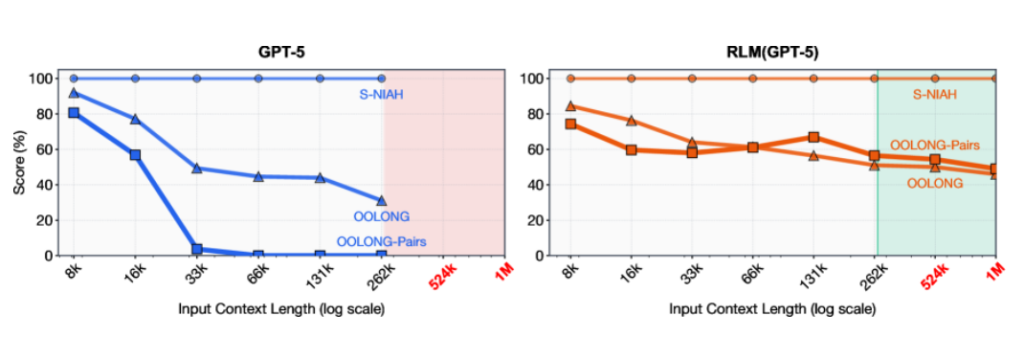
Even frontier LLMs such as GPT-5 perform poorly on long context tasks. RLMs maintain strong performance at scales exceeding 10 million tokens. They achieve double-digit percentage gains over standard long-context approaches. These gains often come at comparable or lower cost, as per research published on arXiv. Increasing context windows alone is not enough. Without recursive orchestration, models still suffer from slower responses, higher costs, and context rot.
Dextralabs leverages Recursive Language Models (RLMs) to address these challenges. What RLMs do is orchestrate reasoning over the context, allowing for inference-time analysis, re-evaluation, and reasoning. The goal of scaling LLM reasoning capabilities is no longer a matter of larger models and longer context inputs. But rather a smarter orchestration Intelligence that can produce the right enterprise-grade outputs for AI.

Scale AI Reasoning Beyond Context Limits
Dextralabs helps enterprises move beyond RAG and ultra-long context LLMs by deploying Recursive Language Models that deliver accurate, traceable, and controlled reasoning at scale.
Schedule an Architecture ConsultationWhat are the Core Limitations of Traditional LLM Inference?
1. Fixed Context Windows
Every LLM has a context window, limiting how many tokens it can process at once. Even for those models that handle 128K or 1M tokens, they fall short compared to real-world enterprise data. The legal proceedings may run into thousands of pages, whereas full-fledged software may run into millions of lines of code. It is not practical or efficient to put all the information in one place. Even if it is possible, it may be slow, costly, and inaccurate.
Why Even Large Context Windows Fail?
- High cost: More tokens mean higher inference expenses
- Slow responses: Long inputs increase latency
- Poor focus: The model struggles to prioritize critical information
2. Context Rot and Attention Degradation
Context rot occurs when earlier information gradually loses influence on model outputs. This results in missed details, shallow reasoning, and lower accuracy, critical issues for compliance, audits, or financial analysis.
Why Chunking, RAG, and Prompt Engineering Fall Short?
Techniques such as chunking, “Retrieval-Augmented Generation” (RAG), and “prompt engineering” are partial solutions. Chunking results in loss of the overall context, the retrieval in RAG is static, and the prompt engineering is fragile.
While helpful, these approaches cannot fully support long-range, enterprise-grade reasoning, which is why Dextralabs focuses on the Recursive Language Model (RLMs) to orchestrate deep, reliable inference.
What are Recursive Language Models (RLMs)?
Recursive Language Models are an inference-time orchestration pattern where an LLM repeatedly calls itself on smaller, focused sub-tasks instead of processing all context in one pass. RLMs scale reasoning across very large datasets without requiring new model architectures or retraining.
RLMs are not new neural networks. They do not require retraining or fine-tuning the base model. Instead, RLMs are an inference-time execution pattern. They define how an LLM interacts with information, decomposes tasks, and reasons across large contexts by calling itself recursively.
This makes RLMs:
- Not a new architecture
- Not a training-time innovation
- A smarter way to use existing LLMs
The Main Concept in RLMs:
The core concept is both simple and profound.
Instead of placing all context in a statement, RLMs view this statement and data as another external environment of their system. The model is given tools or interfaces to explore this environment as needed.
This enables the model to:
- Break down large problems into smaller ones.
- Call itself recursively on focused sub-tasks
- Re-enter reasoning with new, relevant context
The impact is deep reasoning without burdening the model.
How Recursive Language Models Work (Step by Step)
Recursive Language Models use a linear, multi-step approach for inference. They do not attempt to grasp everything within a single inference but, instead, reduce complex tasks into smaller ones and resolve these smaller tasks recursively.
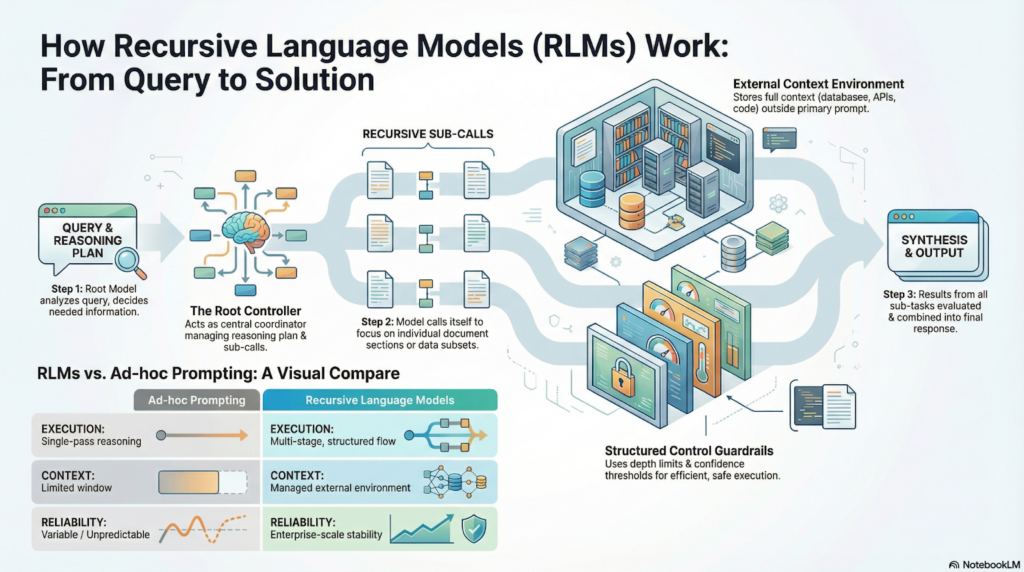
1. High-Level Execution Flow
The general RLM process follows this path:
First of all, the user must submit their question or task to the system. In other cases, instead of uploading all the available information to one query, the system stores the context externally. This can be documents, databases, APIs, code repositories, or even knowledge bases.
A root language model then reviews the user query and creates a reasoning plan. Its role is not to provide immediate answers, but to decide what information is needed and where to look next.
Using this plan, recursive sub-calls are applied in the model. These sub-calls concentrate on different aspects within the context, perhaps a part of the document or a code section. The results from the sub-calls are then assessed and combined to make a comprehensive answer.
This process continues until the model has learned enough to complete the task confidently.
2. Structured Control Flow in RLMs
Recursive Language Models involve controlled flows of data, rather than text generation. It is this controlled nature which makes them useful on an enterprise scale.
Important aspects are:
- Self-invocation:
The model can call itself with a more focused prompt. This will allow it to focus on a single aspect of the problem at a time.
- Structured outputs:
Each recursive call returns reliable, machine-readable results rather than open-ended text. It becomes easier to monitor the progress and aggregate the results.
- Guardrails and stopping rules:
Depth limitations, confidence thresholds, and pre-specified termination conditions ensure that infinite recursion does not occur.
As a result, RLMs have more stable operation and can be more efficiently handled compared to ad-hoc prompting or loosely described agent task flows.
3. Conceptual RLM Architecture
At a high level, a Recursive Language Model system includes the following components:
- Root controller:
Acts as the central coordinator, planning the reasoning process and managing recursive calls. - Context environment:
Contains all the external information, like documents, databases, APIs, and codebases, and provides managed access to it. - Worker sub-models:
Handle specific sub-tasks, such as analyzing a document section or examining a particular dataset.
- Aggregation Layer:
It combines the results of every recursion step to produce the final structured response.
At Dextralabs, this is reflected in how enterprise-level orchestration helps create scalable, controlled, and reliable AI systems beyond simple prompt-based methods.
RLM vs Other Long-Context Approaches: A Practical Comparison
As enterprises push LLMs to handle larger and more complex workloads, several approaches have emerged to extend context and reasoning. Recursive Language Models differ from these methods in both capability and intent.
RLM vs Chunking
Chunking breaks large inputs into smaller pieces and processes them one by one. While this works for basic tasks, it often loses the overall context and logical connections between chunks. Recursive Language Models maintain a global view of the problem, allowing the system to reason across documents instead of treating them in isolation.
RLM vs Retrieval-Augmented Generation (RAG)
RAG is effective at fetching relevant information quickly, but it stops at retrieval. The reasoning still happens in a single pass. RLMs go further by reasoning over retrieved content in multiple stages, revisiting context as needed and refining conclusions dynamically.
RLM vs Agentic Systems
Agent systems are designed to perform actions like calling tools, writing files, or interacting with external systems. Recursive Language Models are optimized for structured reasoning. Their focus goes to deep analysis, controlled exploration, and reliable decision-making rather than task execution.
RLMs vs Ultra-Long Context Models
Ultra-long context models are convenient but come with high costs, increased latency, and declining attention quality as context grows. RLMs avoid these problems since they operate with external context and recursive reasoning, skipping the overloading of a model during analysis by scaling.
Comparison Overview
| Approach | Strengths | Limitations | Best Use Case |
|---|---|---|---|
| RAG | Fast information retrieval | Limited multi-step reasoning | Knowledge lookup |
| Agent Systems | Flexible tool usage | Complex control and reliability challenges | Action execution |
| Long-Context LLMs | Simple workflows | High cost and context degradation | Medium-length tasks |
| Recursive Language Models | Scalable reasoning with a large context | Higher orchestration complexity | Enterprise-grade reasoning |
When Should Enterprises Use Recursive Language Models?
“Recursive Language Models” are most suitable when dealing with complex, critical situations requiring extensive analysis and accuracy. These models find usage in the following areas in the context of enterprise businesses:
- Multi-document legal analysis that requires consistent interpretation across contracts, policies, and case files
- Comprehending complex software codebases, such as architectural reviews, dependencies, and technical documentation
- Financial audits and technical due diligence, where tracing, validating, and reasoning are involved with information
- Synthesis of research findings for thousands of files, such as reports, whitepapers, and knowledge repositories
- Internal knowledge intelligence systems that demand reliable answers grounded in large, evolving datasets
These types of environments require more attention to being accurate, thinking deeply, and reliable rather than being fast, making Recursive Language Models highly suited to enterprise intelligence.
Engineering Considerations for Production-Ready RLMs
It requires proper planning in terms of cost, performance, and reliability when deploying production RLMs.
- Cost Control and Token Efficiency: Limiting the depth of recursion prevents runaway token usage and saves on operational expenses. Budget-aware execution makes sure resources are utilized effectively, while caching repeated results saves tokens and quickens processing.
- Latency and Performance Optimization: Parallelizing independent sub-calls reduces total execution time. Meanwhile, the selective contextual exploration narrows model focus to only the most relevant data, while the adaptive recursion stopping halts calls when sufficient confidence is reached, balancing speed with accuracy.
- Debugging and Observability: Logging of recursive traces and the ability to inspect intermediate outputs contribute to facile monitoring and debugging. The implementation of recovery upon graceful failure allows the system to remain reliable in case of sub-task failures.
Applying these practices will drive enterprises to deploy RLMs that can be scalable, efficient, robust, and accurate in reasoning over large datasets with predictable performance.
Security, Responsibility, and Compliance in Recursive Systems
Enterprise-level Recursive Language Models have to be secured thoroughly to enable efficient reasoning for generalization and to comply with regulations. At Dextralabs, ensuring systems maintain control over sensitive data while supporting enterprise-scale operations.
Key considerations include:
- Preventing unauthorized use of sensitive context information
- Restricting visibility for each recursive call
- Maintaining detailed audit logs for compliance
- Guarding against hallucination amplification
We deliver secure, enterprise-ready AI systems designed with governance and control at the core.
Evaluating RLM Performance and Reliability
Assessing Recursive Language Models goes beyond simple accuracy. Dextralabs emphasizes a thorough evaluation to ensure reliability, consistency, and high-quality reasoning.
Key considerations include:
- Balancing accuracy and completeness
- Benchmarking performance against alternatives like RAG
- Incorporating human-in-the-loop validation
- Stress testing recursion depth and edge cases
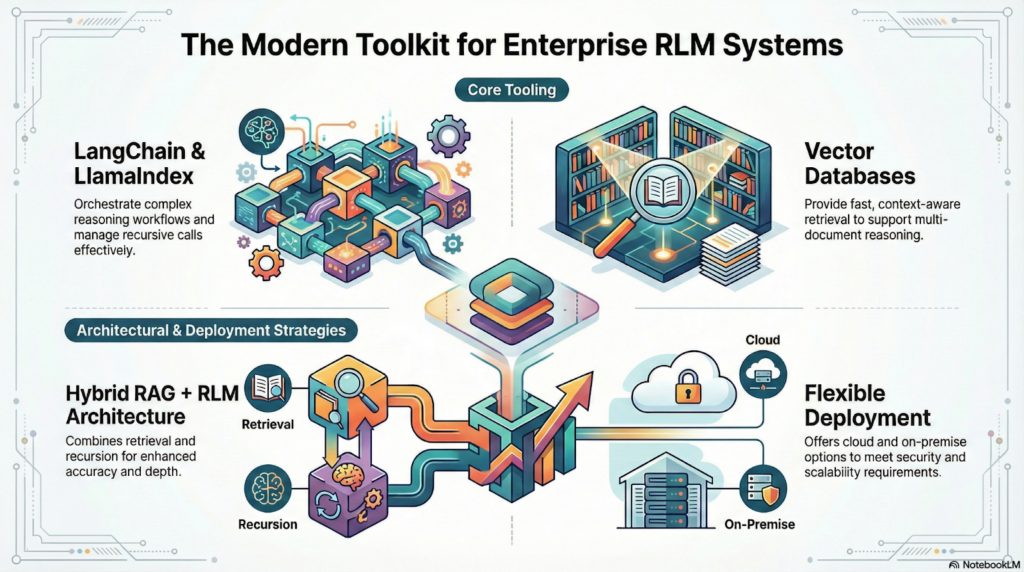
Building RLM Systems with Modern LLM Tooling
Recursive Language Models are seamlessly integrable with the modern tooling of LLM. Dextralabs utilizes this to build efficient, scalable, and robust systems of RLM systems.
Important factors and techniques include:
- LangChain and LlamaIndex: Reasoning flow orchestration, handling complex recursive calls.
- Vector databases: Enable efficient and context-related retrieval for multi-document reasoning.
- Combined RAG & RLM schemes: Adding the strength of RAG techniques for better accuracy and depth.
- Cloud & on-prem deployment models: Provides adaptability, where the enterprise can decide on the model of deployment based on its own needs regarding security & scalability.
This contemporary tooling ecosystem ensures that RLM systems remain robust, efficient, and fully aligned with enterprise operational needs.
Future of Recursive Language Models
The future of Recursive Language Models promises more advanced enterprise reasoning, with Dextralabs focusing on innovation and scalable solutions.
Key developments include:
- Parallel recursive trees
- Multi-agent recursive planners
- Memory-augmented transformer integration
- Fully autonomous enterprise reasoning systems
Dextralabs’ Approach to Recursive Language Models
Dextralabs assists companies in the design and implementation of Recursive Language Models that are specifically targeted at the desired goals of the organization. This is not a model of experimentation but one that creates impact.
Core offerings include:
- Custom RLM architecture design tailored to enterprise needs
- Secure deployment of LLMs in private cloud or on-prem environments
- Technical due diligence for AI systems
- Scalable cost-effective orchestration for reliable enterprise reasoning
This will ensure RLM environments remain strong, safe, and optimized for real-world apps.
Final Thoughts
Recursive Language Models (RLMs) are a paradigm shift in scaling AI logic and reasoning. Dextralabs makes it crystal clear that the “future of enterprise AI isn’t about bigger models and longer input statements, but about more intelligent and structured inference.”
Through the combination of orchestration, recursion, and control, RLMs empower systems with the capabilities of extensive data reasoning, multi-step problem-solving, and precision even in mission-critical applications. This model not only overcomes the shortcomings of token-bound models, providing a framework for next-generation AI systems that are both intelligent and operationally efficient.
Key takeaways for enterprises:
- Smart inference enables deeper thinking with smaller models
- Scalable architectures handle complicated multi-document and multi-source analysis tasks.
- A controlled execution will provide certainty and accuracy
- RLMs provide a strategic advantage by realizing true business value
For forward-looking organizations, adopting RLMs is no longer optional, it is essential for competitive AI-driven strategies.
Turn LLMs Into Enterprise Intelligence Systems
Dextralabs partners with enterprises to transform generic LLMs into production-ready reasoning systems, secure, cost-efficient, and aligned with governance.
Speak with an AI Strategy ConsultantFAQs on RLMs:
Q. How do RLMs scale reasoning beyond LLM context window limits?
RLMs keep large context external to the model and allow the LLM to recursively explore, analyze, and re-evaluate relevant information as needed. This avoids overloading the context window while preserving deep, multi-step reasoning across millions of tokens.
Q. How are RLMs different from Retrieval-Augmented Generation (RAG)?
RAG focuses on retrieving relevant information and performing reasoning in a single generation step. RLMs go further by enabling multi-stage recursive reasoning, allowing the model to revisit retrieved context, refine conclusions, and maintain global coherence across large knowledge spaces.
Q. Do Recursive Language Models require training or fine-tuning?
No. RLMs do not require training or fine-tuning. They operate entirely at inference time and work with existing LLMs such as GPT, Claude, or Gemini, making them cost-efficient and faster to deploy in enterprise environments.
Q. When should enterprises use Recursive Language Models?
RLMs are most valuable for complex, high-stakes tasks such as legal document analysis, software codebase comprehension, financial audits, technical due diligence, and enterprise knowledge intelligence, where accuracy, traceability, and deep reasoning matter more than speed.
Q. Are Recursive Language Models safe and controllable for enterprise use?
Yes, when designed correctly. Production RLM systems include guardrails, depth limits, confidence thresholds, audit logging, and access controls, ensuring predictable behavior, data security, and compliance with enterprise governance requirements.
Q. How are Recursive Language Models evaluated for reliability?
RLM evaluation goes beyond accuracy and includes reasoning consistency, traceability of intermediate steps, hallucination resistance, recursion stability, and human-in-the-loop validation, making them suitable for mission-critical enterprise applications.