
In the digital age, more businesses take on more requests, inquiries, and operations than ever before. Managing a few thousand requests per day is rather easy; however, scaling to millions of requests becomes complicated due to complexity, latency, and reliability issues that conventional systems do not cope well with.
A rapidly growing SaaS business approached Dextralabs with one burning question: “How do we manage the rising volume of customer interactions with our existing systems, which are becoming incapable of handling the workload?” There was frequent manual intervention, response times were deteriorating, and any attempts to scale through conventional infrastructure would lead to costs that were exponentially higher than what they would have expected.
Our task was simple: design and develop a system of AI agents to automate millions of requests a day, reduce the human workload, provide fast response times, and be scalable and cost-effective.
In this case study, we will examine some of the problems the client was experiencing, the fixes Dextralabs put in place, and some measurable outcomes from these improvements. While much of this content will share insights into customer support automation, you can apply these lessons and ideas in any environment where intelligent agents can make workflows smoother, more productive, and be deployed in a reliable manner.

Empower Your Business with Intelligent AI Agents
From automation to decision-making — build scalable, intelligent AI agents tailored to your enterprise needs.
Talk to Our ExpertsThe Challenge: Scaling Beyond Human Capabilities
The client, a SaaS platform, had developed a rudimentary bot and rule engine for customer support requests, internal tickets, and data look-up queries, which resulted in several challenges:
- Throughput performance limitations: Response times slowed as the volume increased. The existing system could not provide the same throughput during the spikes.
- Rigid rule logic: Many cases needed context, history, and branches in decision-making – simply rules were not sufficient.
- Manual oversight load: Human agents had to assist cases with some ambiguity, which created throughput delays.
- Cost scaling: Adding servers or manual staff would scale costs nearly linearly.
- Reliability and error handling: Edge cases or unexpected inputs often lead to some sort of resolution, which causes failures or misroutes.
They required a system that could dynamically route, reason, and act while maintaining strong performance at scale.
Our Approach: AI Agent Structure and Pipeline
Here’s how Dextralabs built a scalable agent-based pipeline to address these issues:
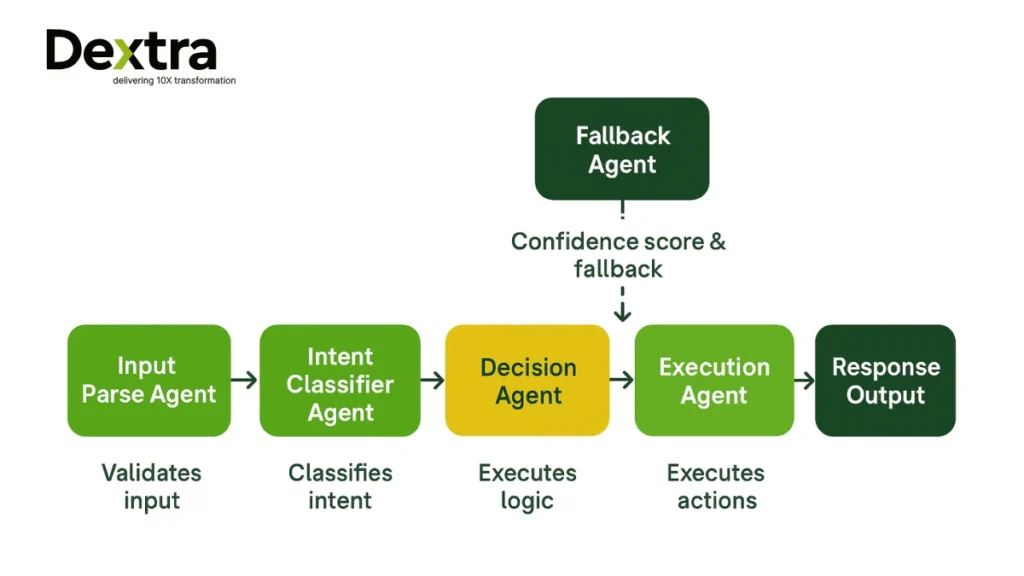
- Agent decomposition and specialization
Rather than taking a monolithic “brain” approach to the task, we divided the task into a number of agents, each with a target task to complete. For instance:
- Input Parse Agent – cleans, normalizes, and validates incoming requests.
- Intent Classifier Agent – identifies what type of request it is (support, lookup, transaction, etc).
- Decision Agent – uses logic and context to apply logic or chains to sub-agents to reach an action.
- Execution Agent – makes external API calls (to a third party or downstream), updates state, or triggers downstream states.
- Fallback / Escalation Agent – handles cases where confidence is low by sending to human review or safe defaults.
This modular structure isolates complexity and allows for independent scaling of each agent.
- Prompt chaining and context memory
For agents that do rely on large language models (LLMs) and other models, we utilized prompt chaining, in which the output of agents is a part of the other agents’ context. In addition, we maintained a short memory buffer with recent interaction history, so that agents could “remember” a prior step, without sending a full transcript as context every time.
- Batching, asynchronous queues & horizontal scaling
For volume, many of the calls to the agents run in batches or all at once. We used message queues, such as RabbitMQ and Kafka, and pooled workers. The agents pull work from the queues. If upstream happens faster than downstream, the downstream queues buffer them. This decouples the agent function and prevents single overburdened bottlenecks from crashing it.
- Confidence thresholds & safe fallback
Each agent not only returns an outcome, but also a confidence score. If confidence is below the threshold for that agent, we route to a fallback option or human review. This ensures safety and avoids catastrophic errors.
- Monitoring, logging, & metrics
We implemented robust metrics, including latency and error rate metrics, throughput per agent, and fallback frequency. We log each request with a full trace that allows us to debug and audit. We use dashboards to alert the user of anomalies or performance degradations.
- Iterative improvement & retraining
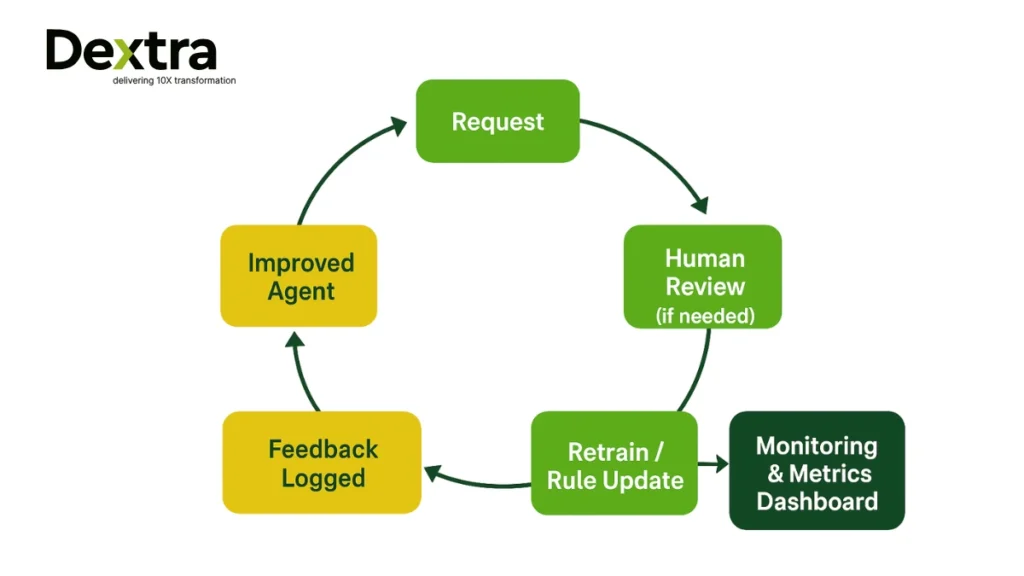
The system incorporates a feedback loop: whenever there is a human intervention, we log it, and then we can either retrain or update the agent’s logic. We periodically revisit the agents’ models and rules. In this way, the system can “learn” over time.
Implementation & Technical Choices
Below are important design choices and compromises we considered.
| Decision Area | What We Selected | Why / Trade-Offs |
| Model vs Rules | Use lightweight LLMs (or fine-tuned models) for some agents + rule logic in others | A pure LLM for everything would be too costly. Rules check simple high confidence cases. |
| Context window size | Maintain the recent 5-10 past interactions. | Too large a context significantly slows inference, too small a context is not enough to filter through needed context. |
| Batch size | Group size of 8-32. | Finding the sweet spot of “big enough to amortize the costs of the process but small enough to be reactive, low-latency.” |
| Timeout/retries | If an agent times out, a retry occurs for a maximum of N attempts, which will also avoid cascading failures. | If multiple attempts to the agent are unsuccessful, then to avoid cascading failures and errors, fallback to pre-defined behavior. |
| Autoscaling | Containerized microservices + autoscaling policies. | As loads increase on agents, they can scale up, and during lulls, they can scale down. |
| Logging granularity | Logs every request with full trace in structured logs for requests | This enables audit, but we batched older logs so they can be sent to long-term storage to save costs. |
Results & Business Impact
Following deployment of this architecture, here’s what the client experienced over the course of a few weeks:
- Millions of requests serviced: From 100,000 requests/day to reach over 2 million requests/day, with the capacity to scale even further.
- Latency managed: Core flows’ 95th percentile response time maintained below the 500ms threshold
- Human intervention reduced by 80%: Only the greatest 20% of cases require human evaluation.
- Cost per request reduced by 60%: Because autoscaling and the specialization of agents are an effective way to avoid any waste and frustration
- Faster iteration cycles: Adding a new request type (new intent) took days, rather than weeks
- Improved reliability: Fallback routing prevented catastrophic failures; errors dropped by 50%.
The data gave the client information and justification that it had confidence to expose further automation to all users, reduce support headcount, and scale their business without linear cost increases.
Implementation & Technical Choices
From this project, we compiled a list of lessons and potential traps that could inform any organization looking to build scalable AI agents.
1. Modular Agent Design is Essential
When possible, divide the work into multiple simpler, specialized agents instead of building one large “super agent.” This will be easier to manage, debug, and scale, and allow the team to iterate on each modular piece independently. With a modular design in place, it will be easier to isolate problems with the system without affecting the entire system.
2. Confidence & Fallback Logic is Mandatory
Always establish confidence levels and potential fallback paths. In circumstances where the agent is unsure, having a human review or safe defaults will avoid catastrophic errors and help keep the system stable. In the end, this facilitates users to expect consistency and security.
3. The Monitoring and Feedback Loops Drive Improvement.
Monitor variables, such as latency, error rates, and throughput, and leverage feedback from people to improve agent training. Continuous monitoring enables the system to enhance performance over time. Feedback loops also help you find patterns of failure that you may not have recognized on your own.
4. Batching and Asynchronous Processing
In order to effectively deal with a high volume of tasks, batching and processing asynchronously is the best option. This will avoid potential bottlenecks and promote quicker response times while helping maintain stability during peak traffic.
5. Small Starts, Expand Iteratively
First, automate the frequent or high-volume work, then iterate from there. This helps to minimize complexity, elude rigorous engineering, and build learning from early automations. Starting small also allows teams to validate their assumptions about the automation before trying to scale it broadly.
6. Context and Memory must be Judicious
Give agents sufficient context, so they can make ideal decisions, but don’t overload them with information that is not altogether pertinent, as this will depreciate their response times and increase error rates. The key is ensuring the context provided has meaning so that agents will remain focused and be able to act efficiently and accurately.
7. Logging Overhead Must Be Managed
Implement strategic logging methods that record important occurrences without burdening your storage or slowing performance. Quality logging methods will help to shorten time spent troubleshooting and maintain a level of compliance with audit requirements, as needed.
8. Human-in-the-Loop is Acceptable
Partial human oversight increases safety, accuracy, and trust, especially in edge cases or when rolling out new capabilities as an agent improves. Humans also possess very useful nuance in the form of knowledge that can improve agent behavior over time.
Why Dextralabs is Your AI Agent Deployment Partner?
At Dextralabs, we don’t just have technical skills; we have experience building and delivering real production systems, not just prototype code. We focus on the following important areas:
- Outcome-based design (rather than something flashy and without real intent)
- Safety, observability, and maintainability
- Strong architecture & engineering discipline
- Domain alignment and real business value
In this particular project, we didn’t just throw code over the fence. We co-designed the system, iterated with the client, trained the client’s team, and then we built a plan for the next phrases.
If your business is ready to automate at scale – whether it’s for chat, for operations, pipelines, or any intelligent request processing – Dextralabs is your partner to go from Idea to solid, efficient, and safe AI systems.
Final Thoughts
Building AI agents that can reliably handle millions of requests is not a simple task. It takes careful design, decomposition, safety logic, metrics, and iteration. But done right, the benefits are enormous: scalability, cost savings, speed, and less manual effort.
In this case study, we showed how Dextralabs approached such a problem: agent decomposition, prompt chaining, asynchronous pipelines, fallback logic, and continuous learning. The outcomes? Dramatic scaling, cost savings, and operational viability.
If you want to tackle building high-quality, scalable AI agents for your respective product or platform, we can work together to build models and systems that will meet your high-volume demand. Let’s chat about how we can convert your high-volume requests into a system that is meaningful and reliable!
