Do you know which one “Claude 3 vs GPT-4” is best for enterprise use cases? Let’s get crack it! Claude 3 by Anthropic and GPT 4 by OpenAI are two leading enterprise-grade large language models (LLMs). While both support advanced reasoning, tool use, and API integrations, they differ in context window size, safety philosophy, multimodal depth, cost structure, and deployment flexibility for enterprise environments.
The LLM pricing market tells a clear story about where enterprise AI is heading. Research tracking intelligence-per-dollar shows that from October 2022 through December 2025, prices have been declining steadily while performance has surged, making model selection increasingly strategic rather than budgetary. Choosing the wrong model doesn’t just slow your team down, it costs real money at scale.
At Dextra Labs, we help enterprises and SMEs across the UAE, USA, and Singapore evaluate, benchmark, and deploy LLMs for production systems. This guide gives you the honest, research-backed comparison between Claude 3 vs GPT-4, so that you can make a confident decision.
Quick Answer: Which Is Better for Enterprise?
- Best for long-context processing: Claude 3
- Best ecosystem and plugin maturity: GPT-4
- Best for AI safety and alignment: Claude 3
- Best for product integrations and Microsoft stack: GPT-4
- Best for regulated industries: Claude 3
- Best for multimodal workflows: GPT-4
- Best LLM for enterprise overall: Depends on regulatory needs, infrastructure stack, and deployment model
The honest truth? Most production enterprises in 2026 use both, routing tasks based on context, cost, and capability. We cover why at the end of this guide.
What Is Claude 3?
Claude 3 is Anthropic’s advanced LLM family designed with safety-first architecture and enterprise deployability. According to Anthropic’s official documentation, the Claude 3 family includes three tiers:
- Claude 3 Opus: Highest reasoning capability, best for complex analytical tasks
- Claude 3 Sonnet: Balanced performance and speed, ideal for most enterprise workflows
- Claude 3 Haiku: Fastest and most cost-efficient, suitable for high-volume lightweight tasks
Claude 3’s defining characteristic is its 200,000-token context window, which allows it to process entire codebases, lengthy legal contracts, or large research documents in a single pass. Anthropic built Claude 3 on Constitutional AI (CAI), a methodology where the model is trained to follow a set of principles to self-critique and improve its outputs, as described in Anthropic’s published research.
What Is GPT-4?
GPT-4 is OpenAI’s flagship multimodal model powering ChatGPT Enterprise and API deployments. It supports text, vision, code generation, and tool calling across complex enterprise workflows.
GPT-4 was the first widely deployed model to demonstrate strong performance across both text and vision inputs, making it a default choice for enterprises building multimodal applications. According to research tracking model performance from 2022 to 2025, GPT-4 maintained state-of-the-art performance for approximately one year before Claude 3.5 and Gemini briefly took the lead in mid-2024 (Fradkin & Larsen, SSRN 2025).
GPT-4’s key differentiator is its mature ecosystem: tight integration with Microsoft Azure, GitHub Copilot, Microsoft 365 Copilot, and an extensive library of third-party plugins and enterprise tools.
Claude 3 vs GPT-4 — Head-to-Head Enterprise Comparison
| Feature | Claude 3 | GPT-4 |
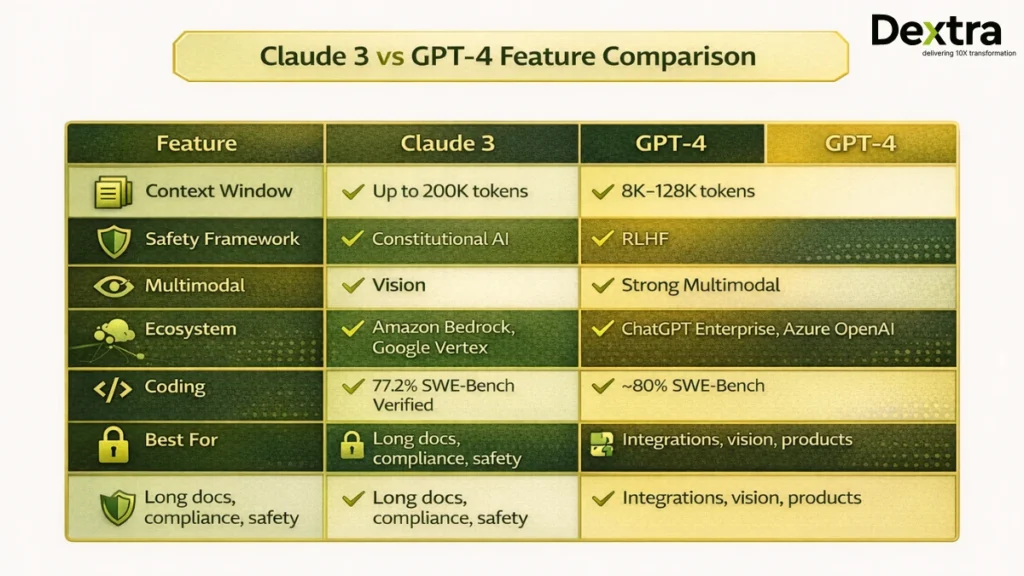
| Context Window | Up to 200K tokens | 8K–128K (varies by version) |
| Safety Framework | Constitutional AI (CAI) | RLHF |
| Multimodal | Vision (Opus) | Strong multimodal (text + vision) |
| Enterprise Plans | Amazon Bedrock, Google Vertex, API | ChatGPT Enterprise, Azure OpenAI |
| Ecosystem Maturity | Growing | Mature, Microsoft-native |
| Coding Performance | 77.2% SWE-Bench Verified | ~80% SWE-Bench (GPT-5.2 line) |
| Best For | Long docs, compliance, safety | Integrations, vision, products |
| Pricing Model | Per-token, tiered by variant | Per-token, tiered by capability |
Research from an independent benchmark study found Claude 3 Opus outperforms GPT-4 in solving undergraduate control engineering problems, with human expert panels rating Claude 3 Opus as the state-of-the-art LLM on ControlBench. That said, GPT-4 maintains advantages in multimodal tasks and ecosystem integration.
Claude vs ChatGPT for Developers
1. API Usability
Claude 3 API:
- Clean, well-documented SDK via Anthropic’s Python and TypeScript clients
- Available through Amazon Bedrock and Google Vertex AI for enterprise-grade infrastructure
- Rate limits tiered by plan; enterprise tiers support high-throughput deployments
GPT-4 API:
- Extensive documentation with broad community adoption
- Native Azure OpenAI Service integration for enterprises already in the Microsoft ecosystem
- Rich tooling for fine-tuning, embeddings, and function calling
Verdict: If your team is already on Azure or Microsoft 365, GPT-4’s API offers frictionless integration. For teams on AWS or GCP, Claude 3 via Bedrock or Vertex is the more natural fit.
2. Tool Calling and Agents
Claude 3 Tool Architecture:
- Native tool use with parallel tool calling
- Strong at multi-step agentic workflows requiring long context
- Works natively with LangChain, LlamaIndex, and custom agent frameworks
GPT-4 Function Calling:
- Robust function calling with JSON schema enforcement
- Extensive agent frameworks built specifically around GPT-4 (AutoGPT, AgentGPT)
- LangChain supports both equally; GPT-4 has more community-built agents
According to METR’s 2025 randomized controlled trial, AI agents can now complete software engineering tasks that take humans up to 5 hours, with task complexity doubling every 7 months. Both Claude 3and GPT-4 benefit from this agentic shift, but their strengths differ.
3. RAG Compatibility
Both Claude 3 vs GPT-4 integrate cleanly with major vector databases (Pinecone, Weaviate, Chroma, FAISS). The key difference:
- Claude 3’s 200K token window reduces retrieval frequency needed, you can fit more context in a single call
- GPT-4’s ecosystem has more pre-built RAG integrations and templates through LangChain and LlamaIndex
Which LLM Performs Better in Enterprise Use Cases?
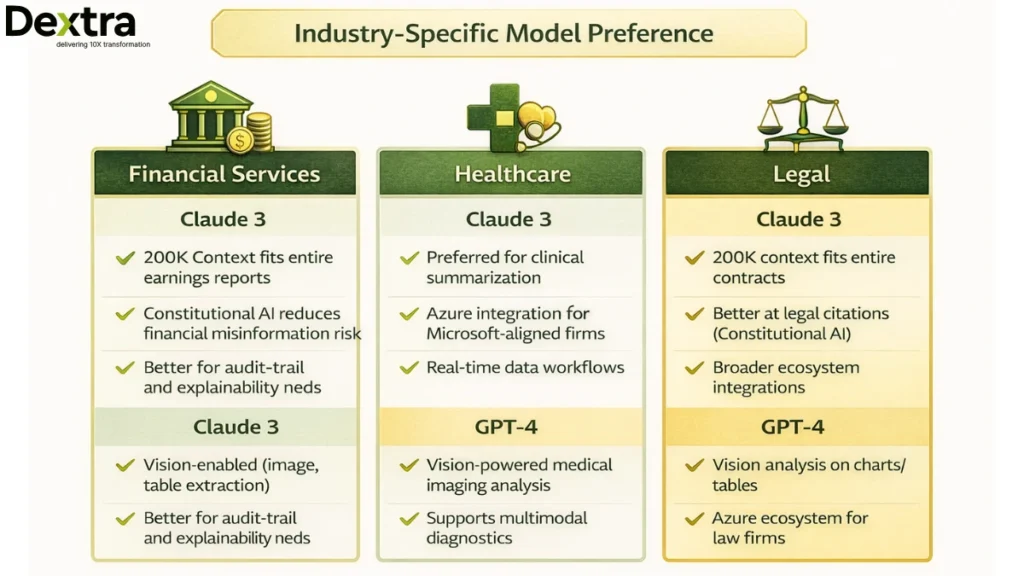
Financial Services
Claude 3 shows an edge in financial document processing:
- 200K context fits entire earnings reports, regulatory filings, and contracts
- Constitutional AI reduces risk of generating misleading financial information
- Better suited for audit-trail requirements and explainability needs
GPT-4 excels in:
- Vision-enabled processing (charts, tables from scanned documents)
- Integration with Microsoft Azure for banks already in that ecosystem
- Real-time data workflows through function calling
Healthcare AI
Research shows that worse-performing LLMs exhibited paradoxically higher confidence—a critical concern in healthcare. A 2025 study in JMIR Medical Informatics found that lower-performing models showed 46% accuracy but 76% confidence, while top-performing models had 74% accuracy with 63% confidence (JMIR Medical Informatics, 2025). Both Claude 3 and GPT-4 fall into the more calibrated category, but enterprises should evaluate on domain-specific benchmarks.
- Claude 3: Preferred for clinical summarization, long patient records, compliance-heavy documentation
- GPT-4: Preferred for medical imaging analysis, multimodal diagnostics support, broader ecosystem integrations
Legal and Compliance
Claude 3 is the preferred choice for most legal applications:
- Fits entire contracts (200K context) without chunking
- Constitutional AI alignment reduces risk of fabricating legal citations
- Less prone to confident hallucination in legal-specific benchmarks
According to Stanford Law School’s 2024 research, LLMs hallucinate at least 75% of the time about court rulings. This makes model choice critical, both Claude 3 and GPT-4 outperform smaller models, but Claude 3’s design emphasis on honesty and calibration makes it more suitable for high-stakes legal work.
Safety and Governance: A Critical Enterprise Factor
Safety isn’t a soft feature for enterprise LLM deployments, it’s a compliance requirement.
Claude 3: Constitutional AI (CAI):
- Model trained to follow explicit principles through self-critique loops
- (arXiv:2212.08073)
- More transparent alignment methodology, easier to audit for regulated industries
GPT-4: Reinforcement Learning from Human Feedback (RLHF):
- Trained on human preference feedback (OpenAI GPT-4 Technical Report)
- RLHF methodology is widely adopted but less explicitly rule-based than CAI
Enterprise Governance Checklist Claude 3 vs GPT-4:
- Data handling: Neither model trains on enterprise API data by default (verify per contract)
- Model auditing: Claude’s CAI provides clearer alignment documentation for auditors
- On-prem / private cloud: Both available through Bedrock (Claude) and Azure (GPT-4)
- Compliance certifications: Both support SOC 2, ISO 27001 deployments through cloud providers
- Explainability: Claude’s longer, more detailed reasoning is preferred for regulated sectors
Cost Comparison: Claude 3 vs GPT-4 Pricing
Pricing is volatile in the LLM market. Research tracking the intelligence market found that price per unit of intelligence has declined consistently from 2022 to 2025, with significant heterogeneity across providers.
Current pricing benchmarks for Claude 3 vs GPT-4:
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
| Claude 3 Haiku | ~$0.25 | ~$1.25 |
| Claude 3 Sonnet | ~$3.00 | ~$15.00 |
| Claude 3 Opus | ~$15.00 | ~$75.00 |
| GPT-4o | ~$2.50 | ~$10.00 |
| GPT-4 Turbo | ~$10.00 | ~$30.00 |
Key cost considerations:
- Long-context economics: Claude 3’s 200K window means fewer API calls for long-document tasks, reducing per-task cost
- Inference cost at scale: For high-volume workflows, Claude Haiku or GPT-4o typically win on cost-performance ratio
- Reserved capacity: Both providers offer enterprise agreements with volume discounts
- Hidden costs: Embedding, fine-tuning, and storage costs differ significantly across providers
When Should Enterprises Choose Claude 3?
- Large document processing: Contracts, financial filings, research papers, legal briefs
- Compliance-heavy industries: Healthcare, finance, legal, government
- Long-context workflows: Tasks requiring coherence across 50K+ tokens
- AI safety priority: Regulated sectors requiring auditable alignment methodology
- AWS or GCP infrastructure: Native integration through Bedrock or Vertex
- Reduced hallucination risk: Where confident wrong answers carry serious consequences
When Should Enterprises Choose GPT-4?
- Strong multimodal needs: Vision-heavy tasks, image analysis, chart interpretation
- Microsoft ecosystem: Azure, Microsoft 365, GitHub Copilot integration
- Existing ChatGPT Enterprise: Teams already using OpenAI’s enterprise offerings
- Startup product builds: Wider plugin support, larger community, more third-party tools
- Agent ecosystem maturity: More pre-built agentic frameworks built on GPT-4
- Fine-tuning workflows: More accessible fine-tuning infrastructure via OpenAI
How to Decide the Best LLM for Your Enterprise?
Before committing to production, evaluate against these criteria for Claude 3 vs GPT-4:
- Infrastructure stack compatibility: AWS → Claude via Bedrock; Azure → GPT-4 via Azure OpenAI
- Compliance requirements: Regulated industries benefit from Claude’s CAI transparency
- Context window needs: Documents over 32K tokens → Claude 3 has a clear edge
- Latency tolerance: Haiku and GPT-4o for speed; Opus and GPT-4 Turbo for quality
- Budget constraints: Run cost models using your actual token volumes before deciding
- Agentic workflow complexity: Multi-step long-horizon tasks favor Claude 3’s context advantage
- Vision requirements: Image-heavy tasks favor GPT-4’s multimodal depth
- Ecosystem dependencies: Existing Microsoft stack tilts strongly toward GPT-4
The Real Answer: Most Enterprises Need a Hybrid LLM Strategy
In 2026, enterprises will rarely rely on a single LLM. Research tracking the LLM market found that 37% of enterprises now use five or more models in production environments as they evaluate task-specific performance, cost dynamics, and governance constraints before deployment.
A practical hybrid approach while choosing between Claude 3 vs GPT-4:
| Task | Recommended Model |
| Long document analysis | Claude 3 Opus or Sonnet |
| Image and chart processing | GPT-4o |
| High-volume customer support | Claude 3 Haiku |
| Code generation | Claude 3.5 Sonnet / GPT-4o |
| Microsoft 365 integration | GPT-4 via Azure |
| Compliance-sensitive outputs | Claude 3 Opus |
| Cost-optimized batch tasks | Claude 3 Haiku or GPT-4o mini |
This isn’t hedging, it’s how production AI systems are actually built. Routing intelligence to the right model for the right task is itself a capability, one that Dextra Labs helps enterprises implement through structured evaluation and deployment frameworks.
How Dextra Labs Helps Enterprises Evaluate and Deploy LLMs?
At Dextra Labs, we don’t recommend models based on benchmarks alone. We run structured LLM evaluation frameworks aligned to your business KPIs, before you commit to production.
What Dextra Labs Provides:
- LLM Evaluation and Benchmarking: Head-to-head comparison of Claude 3 vs GPT-4 on your actual data and tasks
- Claude vs GPT POC Experiments: Controlled proof-of-concept deployments across your specific use cases
- Production-grade deployment architecture: Scalable, cost-optimized pipelines for enterprise workloads
- RAG pipelines: Custom retrieval systems built on vector databases tailored to your knowledge base
- AI agents and orchestration: Multi-model agentic workflows that route tasks intelligently
- Compliance-safe GenAI deployment: Governance frameworks for regulated industries in the UAE, USA, and Singapore
Whether you’re in financial services, healthcare, legal, or technology, our team brings hands-on experience deploying both Claude 3 and GPT-4 in production environments.
Unsure whether Claude 3 or GPT-4 fits your stack? Dextra Labs conducts structured LLM benchmarks aligned to your business KPIs, before you commit to production.
Conclusion: Make the Decision That Fits Your Stack
Both Claude 3 and GPT-4 are genuinely strong enterprise models. The right choice isn’t about which is “smarter” it’s about which fits your infrastructure, compliance requirements, and task profile.
Choose Claude 3 if your priority is long-context processing, regulatory compliance, and a transparent safety framework. Choose GPT-4 if you need deep multimodal capabilities, Microsoft stack integration, or a mature plugin ecosystem. Choose both if you want production-grade performance that routes tasks to the right model at the right cost.
At Dextra Labs, we help enterprises and SMEs across the UAE, USA, and Singapore navigate this decision with structured benchmarking, POC experiments, and production deployment, not guesswork.
FAQs on Claude 3 vs GPT-4:
Is Claude 3 better than GPT-4?
It depends on your use case. Claude 3 Opus outperforms GPT-4 on long-context tasks and has a more transparent safety framework. GPT-4 leads in multimodal capabilities and Microsoft ecosystem integrations. For most enterprises, a hybrid approach works best.
Which LLM is safest for enterprise?
Claude 3’s Constitutional AI provides a more auditable alignment methodology for regulated industries. Both models support enterprise data privacy through their respective cloud platforms. Always validate against your specific compliance requirements.
What is the difference between Claude and ChatGPT?
Claude (Anthropic) uses Constitutional AI alignment and offers a 200K token context window. ChatGPT/GPT-4(OpenAI) uses RLHF alignment and offers stronger multimodal and ecosystem integrations. They differ in safety philosophy, context window, and integration depth.
Which LLM has the largest context window?
Among major enterprise models, Claude 3 offers up to 200,000 tokens significantly larger than base GPT-4 (8K-128K depending on version). For specialized use cases, Meta’s Llama 4 Scout offers context windows up to 10 million tokens for open-source deployments.
Should enterprises use multiple LLMs?
Yes. Research shows 37% of enterprises already use five or more models in production. Routing specific tasks to models best suited for them—by capability, cost, and compliance—is the standard production architecture in 2026.