Choosing the right Large Language Model isn’t easy anymore. With so many options now available—each promising better accuracy, speed, or flexibility—it’s tough to know what really works for your business. Looking to know about right approach for llm evaluation?
The problem runs deeper than just picking a popular model. According to Gartner Research, 85% of generative AI projects fail. Often, the reason isn’t the model itself—it’s poor-quality data or the lack of proper evaluation. Without a solid way to measure how well a model performs for your actual use case, even the most advanced system can fall short.
At Dextralabs, we help growing tech teams and startups in the USA, UAE, and Singapore make practical, well-informed decisions when it comes to LLMs. Whether you’re building a chatbot, automating workflows, or integrating AI into your product, this guide lays out how to test and compare models in a way that actually makes sense—no fluff, just the stuff that matters.
Let’s get started.
What Is LLM Evaluation?
At its core, LLM evaluation assesses a model’s ability to execute tasks like understanding, generating, or reasoning with human-like accuracy. It uses user feedback, real-world testing, and LLM evaluation benchmarks to identify its advantages and disadvantages. Consider it as an AI system’s quality control.
LLM evaluation methods can vary based on use cases. For instance:
- For conversational AI, coherence and context recall are essential.
- For code generation, precision and error rates are crucial.
Why Is LLM Model Evaluation Necessary?
The LLM landscape is both vast and rapidly advancing. Certain models have gone above and beyond what was possible before. It includes big names like GPT-4, Claude v1, and Falcon.
But how do we know which one really works best? Evaluating LLMs ensures they’re reliable, scalable, and tailored to specific needs. Failure to properly assess a model puts businesses at risk of using a flawed one. Eventually, it leads to wasted time and resources.
Consider these numbers from the Business Research Company. By 2025, the global LLM market is expected to surge to $5.03 billion, growing at a staggering CAGR of 28%. This rapid growth makes it hard to find the best performers in a crowd. When the stakes are high, accurate LLM evaluation metrics make all the difference. At Dextra Labs, we understand the importance of evaluating LLMs to ensure reliability and scalability for businesses.
Types of Evaluation Frameworks:
There are various LLM evaluation frameworks to standardize how models are compared. Some focus on technical benchmarks, while others assess alignment with human preferences. Popular approaches include:

1. Holistic Metrics
Frameworks like HELM (Holistic Evaluation of Language Models) evaluate models across diverse tasks, from sentiment analysis to reasoning. They also consider social impact metrics, such as bias and ethical alignment.
2. Human Benchmarks
Despite technological advancements, human evaluation remains essential. Humans assess output quality. When assessing intricate or subtle tasks, it becomes absolutely essential. This approach is time-consuming yet yields invaluable information.
3. LLMs as Judges
A newer concept involves using LLMs themselves for evaluation tasks. While faster, this method raises questions about bias and reliability. Can a model truly evaluate another impartially?
4. DeepEval
Emerging frameworks like DeepEval compare a model’s performance against established leaderboards, such as Chatbot Arena or Hugging Face’s Open LLM Leaderboard. These benchmarks monitor metrics like MMLU and HellaSwag scores for consistency and quality.
What Role Does Human Evaluation Play in Assessing LLM Performance?
Though frameworks like DeepEval are gaining traction, human evaluation remains a gold standard. Only humans can fully assess subjective outputs, such as tone, context relevance, and creativity. These are areas where models often underperform, even with vast datasets.
For instance:
- Real-time connectivity models, like Bard, boast advanced internet integration. However, evaluating how well users interact with its 1.6 trillion parameter architecture often requires human scrutiny.
- Likewise, algorithmic reflection alone is insufficient to guide ethical decision-making and societal influence.
Nevertheless, there’s a growing need to align LLM-assisted evaluation of outputs with human preferences. Ensuring AI aligns with real-world expectations ensures more accurate and inclusive results. At Dextralabs, we use both human knowledge and modern tools to make sure that evaluations meet real-world standards.
Evaluating Large Language Models Using Metrics:
For large language model evaluation, it’s vital to use reliable LLM evaluation metrics tailored to your goals. Here’s what to pay attention to:
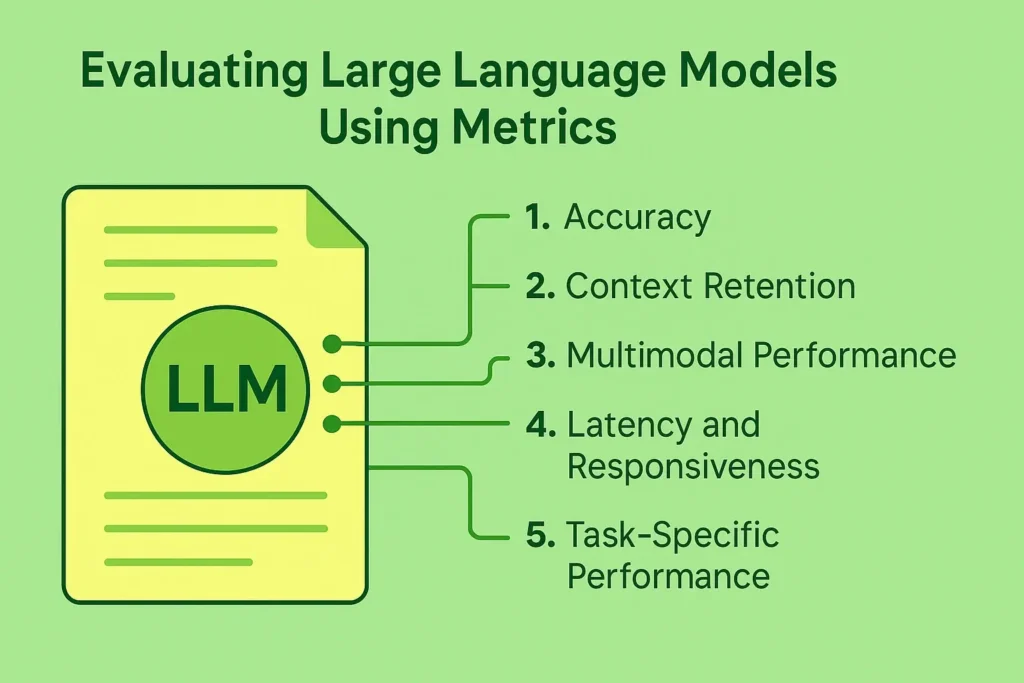
1. Accuracy
How often does the model produce correct, factual information? For example, GPT-4 is celebrated for its alignment capabilities, reducing hallucination rates in factual reasoning.
2. Context Retention
Models with long-context capabilities, like Claude v1’s 100K-token context window, excel in summarizing or analyzing lengthy inputs like books or legal documents.
3. Multimodal Performance
Multimodal models, such as Gemini by Google DeepMind, are transforming expectations by seamlessly processing text, images, and even audio. It’s crucial to find out if apps that create content or serve as virtual assistants are compatible with these formats.
4. Latency and Responsiveness
Speed matters, especially for chatbots or real-time applications. Models like GPT-3.5 stand out for delivering responses quickly without compromising accuracy.
5. Task-Specific Performance
Generalized benchmarks like MMLU and ARC help compare capabilities across disciplines. Falcon and Guanaco, for instance, lead in open-source rankings, scoring high on NLP tasks like text classification and sentiment analysis.
How LLM-As-A-Judge Compares to Traditional Evaluation Methods?
The idea of letting models evaluate each other sounds futuristic but holds promise. Using LLM-as-a-judge can boost scalability by automating routine comparisons. However, traditional evaluations bring unmatched precision in areas requiring subjective judgment.
Automation can be quick, but human comprehension cannot be entirely replaced by it. Refer to experts for evaluations that involve identifying bias, comprehending cultural differences, or considering ethics.
How Does Deepeval Compare to Other LLM Evaluation Frameworks?
One standout in the field is Deepeval. Unlike traditional benchmarks, DeepEval accounts for contextual variability and complex real-world applications. It performs exceptionally well at tracking consistency across iterative tasks and analyzing cross-modal relationships.
For developers and companies wishing to deploy dependable AI systems, adopting such frameworks is essential. They provide transparency, ensuring LLM performance metrics remain relevant as models evolve.
Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences
LLM-assisted evaluations offer speed and scalability. They can automate tasks like ranking outputs or checking responses against quality benchmarks. However, this raises a critical question: who ensures these evaluations are accurate and unbiased?
To trust LLM-assisted evaluations, we need checks in place. Models evaluating other models might unintentionally carry over biases in their training. This can lead to skewed results, failing to address human expectations like ethical considerations or cultural nuances.
Human oversight becomes essential here. Professionals can assess whether the evaluation metrics truly reflect what users value. They can pinpoint areas like tone, creativity, or fairness where automated methods might fall short. Human input adds context and ensures the alignment process stays grounded in real-world needs.
But humans can only do so much. The challenge lies in creating hybrid systems. We need frameworks where human preferences guide LLM-assisted evaluations while addressing the question of bias in the process itself. Developing independent audits for both tools and evaluators could be one solution.
State of What Art? A Call for Multi-Prompt LLM Evaluation
Evaluating LLMs with a single prompt gives an incomplete picture of their abilities. These models are versatile, tackling tasks like reasoning, summarization, and creativity. Overlooking this range can lead to misjudging their strengths.
Multi-prompt evaluation addresses this. It explores diverse scenarios, reflecting real-world use better. A study by MDPI demonstrates that prompt selection can cause performance differences of up to 76 percentage points in specific tasks. This underlines how critical varied prompts are for fair comparisons.
By using multi-prompt frameworks, we ensure LLM eval captures their depth and avoids narrow assessments. It’s a necessary step for building robust, practical AI solutions.
Final Words
As the industry continues to innovate, proper LLM evaluation frameworks will define the success of AI applications. From traditional testing to emerging systems like DeepEval, the importance of robust assessments cannot be overstated.
With the global LLM market on track to hit $13.52 billion by 2029 (source: Research & Markets), understanding how to evaluate LLMs is more critical than ever.
Companies need to carefully think about what they need. You need to look at both qualitative and quantitative standards. It’s very important to choose the model that works best for you. Whether you want the latest in multimodality, smooth user interactions, or ethical alignment.
At Dextra Labs, we help companies streamline this procedure. With proven expertise in evaluating large language models, we ensure our clients deploy solutions that are scalable, reliable, and future-proof. If you’re ready to benefit from the best LLMs in 2025, we can assist you at every turn.
FAQs on LLM Evaluation:
Q. What are the best metrics for evaluating LLMs?
Accuracy, multimodal capabilities, and latency are essential metrics. Additionally, don’t overlook context retention and ethical alignment.
Q. Why does human evaluation still matter?
Humans offer insights that algorithms can’t, particularly for subjective decisions around tone, creativity, and cultural sensitivity.
Q. Which frameworks are best for assessing LLMs?
Leaderboards like HELM and DeepEval provide task-wise benchmarks, ensuring reliable results across industries.
Q. What makes a good LLM evaluation framework?
A robust framework balances precision, scalability, and real-world relevance. It must consider both quantitative data and human preferences.