When people ask, “how does rag work?” in business, the answer is simple: it’s a smarter way to get better AI answers by combining retrieval and generation.
What Does RAG Stand For in AI?
Retrieval-Augmented Generation (RAG) is changing how we build and use large language models. Instead of relying only on what the model learned during training, RAG brings in the ability to search and pull in fresh, relevant information before generating a response.
At Dextralabs, we’ve studied RAG systems closely because they solve one of the biggest challenges with standard language models: static knowledge. Whether you’re building an AI assistant, knowledge bot, or custom domain-specific tool, RAG gives your model the flexibility to fetch answers that are current, accurate, and grounded in real sources.
In short, retrieval augmented language models make LLMs smarter — not by guessing, but by checking first.
Why RAG Matters for Modern Tech Teams?
If you’re running a fast-moving startup or scaling a tech product in the U.S., UAE, or Singapore, you need your AI to be sharp, current, and reliable. But most LLMs have a blind spot — they can’t access new or domain-specific information after their training date. This creates risk when you’re using them for customer-facing tools, internal systems, or compliance-heavy tasks.
RAG solves that. It adds a search layer to your AI so it can find relevant data before it speaks. This means fewer hallucinations, better accuracy, and real trust in the system’s output.
At Dextralabs, we help teams build and deploy RAG-based systems that integrate seamlessly with existing data sources — whether you’re using PDFs, vector databases, or internal knowledge graphs. We’ve seen firsthand how retrieval-augmented generation helps businesses reduce support costs, improve automation, and launch smarter AI products faster. Let’s continue reading this Guide.

Build Your First RAG System with Dextralabs
Ready to implement RAG for your business? Our experts help startups and enterprises deploy scalable, secure retrieval-augmented systems—fast.
Book Your Free AI ConsultationWhat is RAG and How Does It Work?
At its core, Retrieval-Augmented Generation (RAG) works by adding a smart search layer to a large language model. Instead of expecting the model to “know everything,” RAG allows it to retrieve specific information just before responding. It’s a two-part system:
- Retriever – fetches relevant documents or passages from a database or knowledge source
- Generator – uses the retrieved content to create a response that’s both fluent and factually grounded
So rather than generating content from memory alone, a RAG model works more like a well-informed assistant that quickly checks your knowledge base before replying.
The Standard RAG Flow Looks Like This:
- Input Query – The user asks a question
- Query Encoder – The question is encoded into a searchable format
- Retriever – The model searches a connected source (e.g., a vector database)
- Retrieved Documents – Relevant texts are returned
- Generator (LLM) – A response is created based on those retrieved texts

Where RAG Fits in Enterprise AI?
Standard LLMs are great at generating language, but they struggle with:
- Real-time or domain-specific queries
- Responses that require up-to-date facts
- Tasks where accuracy matters (compliance, legal, support)
This is where RAG shines. At Dextralabs, we implement RAG-based pipelines for clients who want their AI to work with live documents, secure internal data, or evolving industry knowledge. From AI support tools for SaaS startups to decision-assist systems in mid-sized tech firms — RAG makes sure your AI isn’t guessing.
Evolution of RAG: From Naive to Modular
RAG Didn’t Stop at the First Draft!
When RAG first emerged, it followed a straightforward process: retrieve documents, then generate a response. This simple approach, now called Naive RAG, worked well for many use cases — but it had limits. As the demand for smarter, more precise AI grew, so did the RAG architecture.
Today, RAG systems have evolved into Advanced and even Modular frameworks, offering better control, deeper accuracy, and more flexibility for custom applications.
At Dextralabs, we’ve seen this evolution first-hand while designing retrieval systems for startups and enterprise clients across the U.S., UAE, and Singapore.

The Three Core Paradigms of RAG:
1. Naive RAG
- Retrieves top-N documents and passes them directly to the generator.
- Fast and simple, but can include irrelevant content.
- Still useful in narrow domains or small knowledge bases.
2. Advanced RAG
- Adds filtering, reranking, or scoring to prioritize better context.
- Helps reduce noisy or off-topic outputs.
- Works well in support bots, customer tools, or QA systems.
3. Modular RAG
- Allows plug-and-play components like:
- Query rewriters for better search terms
- Memory modules to store past interactions
- Routers to direct queries to the right model or database
- Query rewriters for better search terms
- Ideal for enterprise workflows with varied input sources and goals
Why It Matters for Teams Building Real AI Products?
With Modular RAG, your team isn’t stuck with a one-size-fits-all system. You can tweak how queries are interpreted, choose what sources to pull from, and decide how the generator weighs different inputs. This flexibility is key when deploying AI at scale, especially across teams, clients, or regions.
For instance, at Dextralabs, we recently helped a fintech client in Singapore set up a modular RAG agent that retrieves compliance guidelines in real-time and rewrites technical queries from their support team. This reduced their resolution time by 35%.
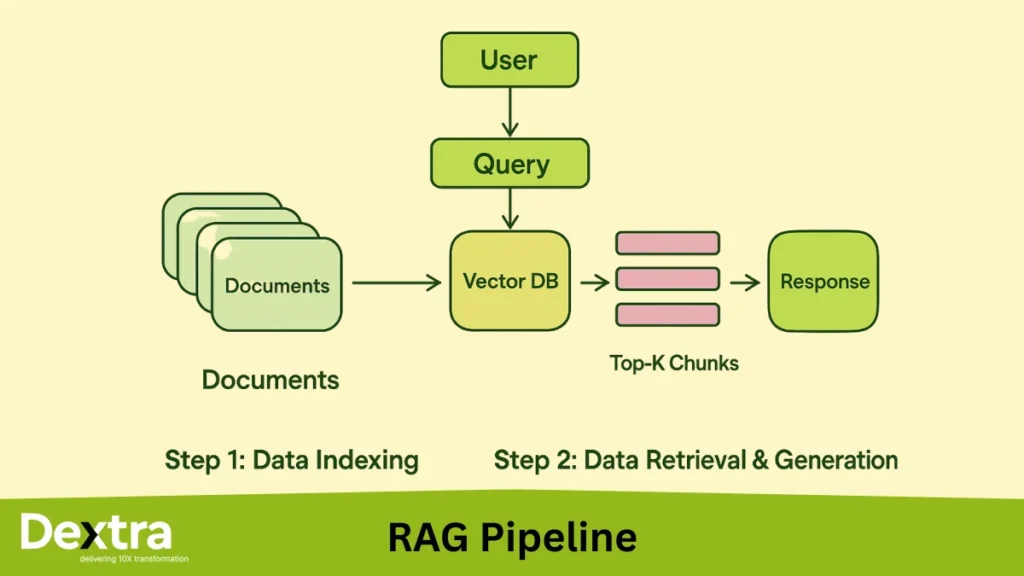
RAG Pipeline and Architecture (Detailed View)
What Really Happens Behind the Scenes? The RAG pipeline looks simple at first glance — but each stage plays a specific role in producing accurate, useful responses. Whether you’re integrating AI into a support assistant, internal tool, or enterprise dashboard, understanding the pipeline helps you build smarter systems from the ground up.
At Dextralabs, we use a modular approach to customize every part of the RAG stack based on the client’s goals — from how the model understands questions to where it pulls answers from.
Breaking Down the RAG Architecture
Here’s what the standard rag diagram typically includes:
1. Query Encoder
The input (e.g., a question) is first passed through a query encoder. This turns the text into a vector format that makes it easier to match against relevant documents in your knowledge base.
2. Document Retriever
The retriever searches a document store or vector database for matches. This can use:
- Sparse methods (like BM25)
- Dense methods (like DPR or ColBERT)
- Hybrid methods that combine both
This is a critical step, as the quality of retrieved content directly affects the final response.
3. Retrieved Documents
The system fetches top results based on similarity to the query. In more advanced setups, these documents can be reranked or filtered using additional models.
4. Generator (LLM)
The selected documents are passed into a large language model (e.g., GPT, T5, FLAN) which generates the final answer — using both the question and the retrieved content for context.

Advanced Add-ons We Recommend at Dextralabs:
- Retrieval reranking to improve result quality
- Document compression to handle context limits
- Post-generation filters to improve factuality and tone
- Support for multi-source retrieval (e.g., combine Notion + PDFs + search index)
This modular design gives you more control — so you’re not just getting answers, but getting better answers.
Real Example: From Query to Response
User: “What’s the deadline for Form 1099 filing in the U.S.?”
Retriever: Searches internal compliance documents and IRS database
Generator: Builds a reply using the retrieved data:
“According to IRS Notice 2024-05, the deadline for filing Form 1099-NEC is January 31.”
Retrieval Techniques in RAG
Getting the Right Information is Half the Job. In any retrieval augmented language model, the quality of the final output depends heavily on what the retriever pulls in. If the documents are off-topic or outdated, even the best language model will give weak answers.
That’s why retrieval isn’t just a step — it’s the core engine that powers useful, grounded AI. At Dextralabs, we’ve helped clients fine-tune this layer to get significantly better results, especially when the data is domain-specific or scattered across multiple sources.
Common Retrieval Strategies in RAG Systems:
1. Sparse Retrieval
- Uses traditional keyword matching techniques like BM25
- Works well for well-structured documents and straightforward queries
- Fast and simple to scale
2. Dense Retrieval
- Encodes both queries and documents as vectors and compares them using similarity scores
- Models like DPR (Dense Passage Retrieval) or Contriever lead here
- Better for understanding semantic meaning, not just keywords
3. Hybrid Retrieval
- Combines sparse and dense methods to improve recall and precision
- Useful when you’re working with messy data (e.g., scanned PDFs, notes, CRM logs)
4. Retrieval with Reranking
- Applies a second model to rerank retrieved documents based on task relevance
- Helps reduce noise and keep the answer focused
Case Study: Scaling Retrieval for a Legal Tech Client
A mid-sized legal SaaS firm in the UAE approached Dextralabs to build a legal assistant that could reference court filings, regulations, and templates across jurisdictions.
We implemented a hybrid retrieval setup combined with document reranking, which increased answer accuracy by 42% compared to their prior solution. The assistant now works across teams without constant manual review.
What Happens When Retrieval Goes Wrong?
If your retriever pulls in irrelevant, outdated, or incomplete information, the output suffers. This is commonly known as “garbage in, garbage out.” That’s why we always include a retrieval quality audit step in our RAG pipeline consulting at Dextralabs — so issues get caught early.
Prompt Engineering and Control in RAG
Why Prompts Still Matter in Retrieval-Augmented Systems? Even with retrieval in place, the way you ask a question still plays a big role in how the system responds. A vague or poorly framed query might fetch the wrong documents — or miss the point entirely.
That’s where prompt engineering comes in.
In RAG systems, prompts aren’t just about formatting inputs for a language model. They also influence:
- How the retriever interprets the query
- Which documents it prioritizes
- How the generator frames its response
At Dextralabs, we work with teams to design prompt strategies that guide both retrieval and generation layers, especially in enterprise use cases like policy bots, HR assistants, and investor-facing tools.
Common Prompting Techniques in RAG:
1. Query Rewriting
Before sending the input to the retriever, a lightweight model rewrites or expands the query to make it clearer. This is especially useful in:
- Chatbots where users speak casually
- Knowledge tools where questions may be ambiguous
Example:
Original: “1099 deadline”
Rewritten: “What is the IRS filing deadline for Form 1099 in 2024 in the United States?”
This improves both retrieval accuracy and the final output.
2. Prompt Templates
Predefined prompt structures help the generator focus on the goal — whether it’s answering, summarizing, or listing options.
Example:
“Using only the documents provided, answer the following user query clearly and concisely…”
This prevents the model from hallucinating or adding unrelated details.
3. Role-based Prompting
You can guide tone and focus by assigning a role to the model — like “compliance advisor” or “technical recruiter.” This works especially well in customer service and B2B support use cases.
Use Case: Prompt Tuning for a B2B Knowledge Bot
A U.S.-based SaaS firm approached Dextralabs to improve their AI assistant for onboarding documentation. Users were typing in general questions, and the bot gave generic answers.
We introduced:
- Prompt templates for clarity
- A query rewriting module for search precision
- And role-based guidance for tone
As a result, accuracy improved by 60%, and support tickets dropped by 28% in the first two months.
Practical Use Cases and Implementations
RAG in Action: From Proof-of-Concept to Production.
At Dextralabs, we’ve helped startups and tech firms in the U.S., UAE, and Singapore move beyond basic LLM chatbots to deploy robust, reliable systems powered by retrieval augmented language models.
What makes RAG implementation valuable is its ability to work with internal data — securely, contextually, and on-demand. It doesn’t guess; it checks before it answers.
Let’s look at where RAG is already making a strong impact.
1. Internal Knowledge Assistants
Companies often store valuable information in scattered formats — PDFs, wikis, CRMs, and cloud drives. A traditional LLM can’t access these directly.
With a RAG agent, you can build a smart assistant that:
- Answers employee queries from HR, finance, or legal docs
- Summarizes onboarding processes
- Flags outdated policies
Real Example: Dextralabs helped a tech firm in Singapore deploy a RAG LLM example trained on internal SOPs and documentation, reducing internal support emails by over 40%.
2. Customer Support Automation
Support queries often need precise, up-to-date answers pulled from product manuals, release notes, and help docs. A RAG pipeline can be built to:
- Retrieve the latest solutions
- Personalize responses based on user history
- Reduce escalations to human agents
Real Example: A UAE-based SaaS platform partnered with Dextralabs to build a RAG-based chatbot. With integrated retrieval from their help center, the bot resolved 65% of user queries without escalation.
3. Financial & Compliance Research Tools
In industries where details matter — like legal, finance, or compliance — hallucinated answers can lead to costly errors. A RAG model architecture ensures the system sticks to verified content.
Real Example: For a U.S. fintech startup, Dextralabs implemented a RAG as a service stack that pulls content from SEC filings, compliance PDFs, and industry rulebooks — giving analysts accurate, sourced answers in seconds.
4. AI-Powered Research and Summarization
For research teams drowning in PDFs, studies, and notes, RAG can:
- Summarize dense material
- Compare findings
- Highlight contradictions across sources
Whether in biotech, law, or product R&D, this leads to faster, informed decisions.
Popular Tools & Frameworks for RAG
- LangChain – Great for chaining retrieval + generation
- LlamaIndex – Ideal for connecting structured data
- Haystack – Flexible and production-ready for pipelines
At Dextralabs, we work with all major tools, or build custom RAG setups that plug directly into your existing data stack.
Tools, APIs, and Frameworks for RAG:
You Don’t Have to Build It From Scratch! One of the best things about working with retrieval augmented language models is that you don’t need to reinvent the wheel. Over the last year, open-source projects and AI platforms have released reliable frameworks to speed up RAG implementation and reduce technical friction.
At Dextralabs, we help startups and mid-sized tech companies choose and customize the right stack — depending on whether they’re working with structured databases, PDFs, APIs, or a mix of all three.
Top Tools for Building RAG Systems
1. LangChain
LangChain is a Python framework built for chaining together LLMs with tools like retrievers, vector databases, and prompt templates. It’s widely used for:
- Connecting your RAG system with sources like Pinecone, Weaviate, or FAISS
- Handling chat memory and rerouting logic
- Integrating APIs and multi-step chains
Use case: Automating document QA from internal Notion docs using LangChain + OpenAI.
2. LlamaIndex
Previously known as GPT Index, LlamaIndex helps turn your private data into a searchable index that pairs well with an LLM. It’s especially useful for:
- Working with PDF, HTML, CSV, SQL
- Creating custom retrievers from raw text
- Summarizing long documents on-the-fly
We use LlamaIndex often at Dextralabs when building tools for compliance-heavy clients with thousands of pages in their knowledge base.
3. Haystack
A powerful open-source framework by deepset, Haystack allows you to build production-grade RAG pipelines with a wide range of features:
- Built-in support for dense and sparse retrievers
- REST API setup with OpenSearch, Elasticsearch, or Milvus
- Modular components to mix retrievers, re rankers, and generators
Ideal for firms looking to self-host or deploy on private cloud infrastructure.
Using RAG Through APIs
If you’re not ready for full infrastructure, you can still use RAG via APIs. Providers like OpenAI (via function calling), Cohere, and Google Vertex AI allow you to connect external search tools or vector databases to their models.
At Dextralabs, we’ve built API-based prototypes in under a week for clients that needed:
- A secure, query-aware chatbot
- A document assistant for internal use
- A knowledge search tool for clients with limited dev teams
RAG vs LLM Fine-Tuning: When to Use What?
Not Every Problem Needs Fine-Tuning
When teams start working with large language models, one of the first questions they ask is:
“Should we fine-tune the model, or use a RAG diagram or pipeline?”
The answer depends on your data, your use case, and how fast things change in your environment.
At Dextralabs, we guide clients through this decision during our AI consultancy sessions — especially when working with domain-specific data or high-volume customer interactions.
What’s the Difference between rag vs llm?
Fine-Tuning an LLM
Fine-tuning means modifying the weights of a pre-trained model (like GPT or LLaMA) using new examples. You’re teaching the model new language patterns or domain knowledge by updating its core training.
Good for:
- Domain-specific tone or formatting
- Structured, repeatable tasks (e.g., invoice generation)
- Scenarios where data doesn’t change often
Not ideal for:
- Rapidly changing information
- Legal or regulatory content
- Highly personalized answers based on fresh data
Using a RAG System
RAG doesn’t modify the model — it builds a system around it. You connect a retriever to fetch external knowledge, then feed that into the LLM as input.
Good for:
- Real-time or up-to-date responses
- Private/internal data you don’t want to hardcode into a model
- Scalable systems that need low maintenance
Not ideal for:
- Tasks that require style imitation or ultra-specific phrasing
- Extremely short, low-context queries
Choosing Between the Two “rag vs llm”
| Feature | RAG | Fine-Tuning |
| New/Updated Info | ✅ Yes (live retrieval) | ❌ No (static knowledge) |
| Setup Time | ⚡ Faster to deploy | ?️ Longer dev cycles |
| Custom Style & Tone | ⚠️ Limited control | ✅ High control |
| Works with Private Data | ✅ Yes | ⚠️ Risky unless self-hosted |
| Maintenance | ? Low (update docs, not model) | ? High (retrain as data shifts) |
What We Recommend at Dextralabs?
In many real-world use cases, you don’t need to fine-tune at all. We often build RAG-first systems, then explore lightweight prompt tuning or instruction-based adjustments if tone becomes an issue.
For example, a UAE-based HR-tech startup asked us to build a recruiter assistant trained on job descriptions and internal hiring policies. Instead of fine-tuning a model, we built a rag model architecture that pulls from their Google Drive and Airtable database — saving them months of training work and compliance reviews.
Current Challenges and Open Problems in RAG
RAG Is Smart, but Not Perfect! While Retrieval-Augmented Generation (RAG) solves several problems traditional LLMs struggle with, it comes with its own set of challenges. These issues usually show up when systems move from prototype to production — especially in enterprise environments with messy, sensitive, or fast-changing data.
Let’s walk through the most common hurdles and how teams can address them.
1. Low-Quality Retrieval Results
If your retriever pulls in irrelevant or outdated documents, your LLM will generate poor answers. Many teams assume retrieval “just works” — but in practice, it often needs tuning.
Fixes We Recommend:
- Use hybrid retrieval (dense + sparse)
- Add reranking layers based on semantic relevance
- Monitor retrieval precision regularly
This is often uncovered during rag analysis and should be part of any ongoing rag implementation review.
2. Context Window Limitations
Language models have a limit on how much information they can process at once. If you feed too many retrieved documents, the model might miss key points or ignore your question entirely.
Fixes We Recommend:
- Use document compression and chunk filtering
- Summarize long docs before feeding them into the model
- Try newer models with larger context windows (e.g., GPT-4-128K)
3. Latency and Cost at Scale
Every RAG query involves multiple steps — encode, search, retrieve, generate. This increases response time and compute cost, especially with high traffic.
Fixes We Recommend:
- Cache common queries and embeddings
- Use vector stores optimized for fast retrieval (e.g., Pinecone, Weaviate)
- Benchmark your rag pipeline llm against expected workloads
4. Security and Data Governance
When using RAG with private or regulated data, teams must ensure:
- No sensitive data leaks into external models
- Retrieval respects access control and version history
- Logs are stored and encrypted properly
At Dextralabs, we help clients design RAG architecture that balances data accessibility with security compliance (GDPR, HIPAA, etc.).
5. Evaluation Remains Tricky
Unlike supervised tasks, it’s hard to measure the quality of RAG output automatically. There’s no single “right” answer — especially in open-ended queries.
Fixes We Recommend:
- Use human-in-the-loop scoring for evaluation
- Apply factuality checks with tools like TruLens or RAGAS
- Incorporate feedback from real users to improve over time
The Future of RAG and Final Thoughts
Over the past year, Retrieval-Augmented Generation has evolved from a clever workaround to a critical AI design pattern — especially for businesses that care about accuracy, reliability, and data control.
The research community is actively exploring better retrievers, smarter reranking models, and ways to scale RAG without compromising speed or cost. In fact, as outlined in the paper “Retrieval-Augmented Generation for Large Language Models: A Survey” (Gao et al., 2023), the future of RAG is deeply tied to advances in, let’s look at multiple rag examples:
- Modular retrieval setups
- Long-context LLMs
- Autonomous RAG agents
- Retrieval evaluation metrics
What This Means for Startups and Tech Teams
Whether you’re building your first AI assistant or refining an enterprise knowledge system, RAG offers a faster path to production than traditional LLM fine-tuning. It’s flexible, easier to maintain, and better suited for real-world business logic.
More importantly, it brings your language model closer to your live data — making AI actually useful, not just impressive.
If You’re Exploring RAG, Start Here:
- Identify what content your users actually need answers from
- Choose a retriever strategy based on your data formats (PDFs? APIs? SQL?)
- Define how your system should balance generation with source accuracy
- Run a pilot — and iterate fast
The LLM space is moving fast — but the most useful AI systems aren’t just large, they’re smart. And right now, the smartest way to build with LLMs is through Retrieval-Augmented Generation.
And if you’re looking to build a solution with real business impact, our team at Dextralabs is here to help — from strategy to full-scale RAG implementation.
If your business is ready to move from generic AI to task-specific intelligence, let’s talk. At Dextralabs, we don’t just build with LLMs — we make them work for you.
Scale Your LLM with RAG as a Service
From prompt design to vector DB integration, Dextralabs offers complete RAG as a Service to help you go live with confidence and clarity.
Book Your Free AI ConsultationFAQs on RAG Pipeline & Use Cases:
Q. What is meant by “retrieval-augmented generation for large language models: a survey”?
Q. What does ‘type RAG’ mean in AI conversations?
Q. What is a RAG assessment?
Q. How do the purposes of retrieved vs generated passages differ?
Q. Can you give three examples of information (in contrast to raw data)?
– Information: “The filing deadline for Form 1099 is January 31, 2025.”
– Information: “Company X raised $5M in Series A funding last month.”
– Information: “Employee onboarding requires completion of 3 specific documents.”
All of these are interpreted, meaningful facts — unlike raw data, which might just be numbers or unstructured text.







